- Here is a list of topics for the final exam.
- Suggested problems for Section 6.7: 1, 2, 3, 5, 7, 9, 10, 13, 16, 17, 19, 20, 21, 23, 25
- Suggested problems for Section 7.4: 3, 7, 11, 13, 14, 15, 17, 21
-
Here is a calculation of a singular value decomposition of the matrix
\[
A = \left[\!\begin{array}{rrr}
3 & -1 & 1 \\
-1 & 3 & 1 \\
1 & 1 & 1 \\
1 & 1 & 1 \end{array}\right].
\]
- (I) To find the singular values and right singular vectors we calculate the matrix \[ A^\top \!A = \left[\!\begin{array}{rrrr} 3 & -1 & 1 & 1 \\ -1 & 3 & 1 & 1 \\ 1 & 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] = \left[\!\begin{array}{rrr} 12 & -4 & 4 \\ -4 & 12 & 4 \\ 4 & 4 & 4 \end{array}\right] = 4 \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \end{array}\right]. \] Observe that adding the first two columns and subtracting twice the third column gives the zero vector. Hence $\lambda_3 = 0$ is an eigenvalue of $A^\top\!A$ and a corresponding eigenvector is $\bigl[ -1 \ -1 \ \ 2 \bigr]^\top$. Since each row of $A^\top\!A$ sums to $12$, $\lambda_2 = 12$ is an eigenvalue of $A^\top\!A$ and a corresponding eigenvector is $\bigl[ 1 \ \ 1 \ \ 1 \bigr]^\top$. Since the vector $\bigl[ 1 \ -1 \ \ 0 \bigr]^\top$ is orthogonal to both earlier found eigenvectors it also must be an eigenvector of $A^\top\!A$. The corresponding eigenvalue is $\lambda_1 = 16$. Thus the singular values of $A$ are $\sigma_1 = 4$ and $\sigma_2 = 2\sqrt{3}$, and the matrices $\Sigma$ and $V$ are as follows \[ \Sigma = \left[\!\begin{array}{rrr} 4 & 0 & 0 \\ 0 & 2\sqrt{3} & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array}\right] \qquad V = \left[\!\begin{array}{rrr} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{3}} & -\frac{1}{\sqrt{6}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{3}} & -\frac{1}{\sqrt{6}} \\ 0 & \frac{1}{\sqrt{3}} & \frac{2}{\sqrt{6}} \end{array}\right] = \bigl[ \mathbf{v}_1 \ \mathbf{v}_2 \ \mathbf{v}_3 \bigr]. \]
- (II) To find a $4\!\times\!4$ orthogonal matrix $U$ we first normalize vectors \[ A \left[\!\begin{array}{r} 1 \\ -1 \\ 0 \end{array}\right] = \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{r} 1 \\ -1 \\ 0 \end{array}\right] = \left[\!\begin{array}{r} 4 \\ -4 \\ 0 \\ 0 \end{array}\right] = 4 \left[\!\begin{array}{r} 1 \\ -1 \\ 0 \\ 0 \end{array}\right], \quad \text{hence} \quad \mathbf{u}_1 = \left[\!\begin{array}{r} \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} \\ 0 \\ 0 \end{array}\right], \] and \[ A \left[\!\begin{array}{r} 1 \\ 1 \\ 1 \end{array}\right] = \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{r} 1 \\ 1 \\ 1 \end{array}\right] = \left[\!\begin{array}{r} 3 \\ 3 \\ 3 \\ 3 \end{array}\right] = 3 \left[\!\begin{array}{r} 1 \\ 1 \\ 1 \\ 1 \end{array}\right], \quad \text{hence} \quad \mathbf{u}_2 = \left[\!\begin{array}{r} \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \end{array}\right]. \] From the general considerations about the singular value decomposition we know that the singular values and left and right singular vectors must satisfy: $A\mathbf{v}_1 = \sigma_1 \mathbf{u}_1$ and $A\mathbf{v}_2 = \sigma_2 \mathbf{u}_2$. Next we verify these equalities: \[ \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{r} \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} \\ 0 \end{array}\right] = 4 \left[\!\begin{array}{r} \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} \\ 0 \\ 0 \end{array}\right] \quad \text{and} \quad \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{r} \frac{1}{\sqrt{3}} \\ \frac{1}{\sqrt{3}} \\ \frac{1}{\sqrt{3}} \end{array}\right] = 2\sqrt{3} \left[\!\begin{array}{r} \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \end{array}\right] \] It has been established in class that $\mathbf{u}_1$ and $\mathbf{u}_2$ form an orthonormal basis for $\operatorname{Col}A$.
- (III) To complete the matrix $U$ we need an orthonormal basis for $\mathbb{R}^4$. Since the space $\operatorname{Nul}\bigl(A^\top\bigr)$ is the orthogonal complement of $\operatorname{Col}A$, we can simply find the nullspace of $A^\top$, and then find two orhonormal vectors in $\operatorname{Nul}\bigl(A^\top\bigr).$ Here we go: \[ \textstyle \left[\!\begin{array}{rrrr} 3 & -1 & 1 & 1 \\ -1 & 3 & 1 & 1 \\ 1 & 1 & 1 & 1 \end{array}\right] \sim \left[\!\begin{array}{rrrr} 1 & 1 & 1 & 1 \\ 0 & 4 & 2 & 2 \\ 0 & -4 & -2 & -2 \end{array}\right] \sim \left[\!\begin{array}{rrrr} 1 & 1 & 1 & 1 \\ 0 & 1 & 1/2 & 1/2 \\ 0 & 0 & 0 & 0 \end{array}\right] \sim \left[\!\begin{array}{rrrr} 1 & 0 & 1/2 & 1/2 \\ 0 & 1 & 1/2 & 1/2 \\ 0 & 0 & 0 & 0 \end{array}\right] \] Thus, \[ \operatorname{Nul}\bigl(A^\top\bigr) = \left\{ s \left[\!\begin{array}{r} -1 \\ -1 \\ 0 \\ 2 \end{array}\right] + t \left[\!\begin{array}{r} -1 \\ -1 \\ 2 \\ 0 \end{array}\right] \ : \ s, t \in \mathbb{R} \right\}. \] All the vectors in $\operatorname{Nul}\bigl(A^\top\bigr)$ are orthogonal to $\mathbf{u}_1$ and $\mathbf{u}_2$ (verify this). There are many pairs of orthonormal vectors in $\operatorname{Nul}\bigl(A^\top\bigr).$ One pair that cough my attention is obtained with $s=1/2$, $t=1/2$ and $s=1/2$, $t=-1/2$ and then normalized. That is the pair \[ \mathbf{u}_3 = \left[\!\begin{array}{r} -\frac{1}{2} \\ - \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \end{array}\right] \quad \text{and} \quad \mathbf{u}_4 = \left[\!\begin{array}{c} 0 \\ 0 \\ -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{array}\right] \] Finally, \[ U = \left[\!\begin{array}{rrrr} \frac{1}{\sqrt{2}} & \frac{1}{2} & -\frac{1}{2} & 0 \\ -\frac{1}{\sqrt{2}} & \frac{1}{2} & -\frac{1}{2} & 0 \\ 0 & \frac{1}{2} & \frac{1}{2} & -\frac{1}{\sqrt{2}} \\ 0 & \frac{1}{2} & \frac{1}{2} & \frac{1}{\sqrt{2}} \end{array}\right]. \]
- Remark To find vectors $\mathbf{u}_3$ and $ \mathbf{u}_4$ it might be slightly more efficient to proceed in the following way. Since we know that $\mathbf{u}_1$ and $ \mathbf{u}_2$ form a basis for $\operatorname{Col} A$ we can find a basis for $(\operatorname{Col} A)^{\perp}$ by solving the system \[ \left[\!\begin{array}{rrrr} 1 & -1 & 0 & 0 \\ 1 & 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{c} x_1 \\ x_2 \\ x_3 \\ x_4 \end{array}\right] = \left[\!\begin{array}{c} 0 \\ 0 \end{array}\right] \] The row reduction of the matrix \[ \left[\!\begin{array}{rrrr} 1 & -1 & 0 & 0 \\ 1 & 1 & 1 & 1 \end{array}\right] \sim \cdots \sim \left[\!\begin{array}{rrrr} 1 & 0 & 1/2 & 1/2 \\ 0 & 1 & 1/2 & 1/2 \end{array}\right] \] might be simpler than the row reduction that we did in (III).
- Here is a list of topics for the second exam.
- Suggested problems for Section 7.3: 1, 3, 5, 9, 11, 12
-
Three fundamental questions about a quadratic form $Q:\mathbb{R}^n \to \mathbb{R}$ are:
- Classify $Q$ as a zero form, or positive semidefinite, or negative semidefinite or indefinite form. If a form is positive semidefinite, state whether it is positive definite or not. If a form is negative semidefinite, state whether it is negative definite or not.
- Consider the set of real numbers \[ \bigl\{ Q(\mathbf{x}) \, : \, \mathbf{x} \in \mathbb{R}^n \ \text{and} \ \|\mathbf{x}\| = 1\bigr\} \] and determine its maximum (call it $M$) and its minimum (call it $m$). Describe clearly the sets \[ \bigl\{ \mathbf{x} \in \mathbb{R}^n \, : \, \|\mathbf{x}\| = 1 \ \text{and} \ Q(\mathbf{x}) = M \bigr\} \quad \text{and} \quad \bigl\{ \mathbf{x} \in \mathbb{R}^n \, : \, \|\mathbf{x}\| = 1 \ \text{and} \ Q(\mathbf{x}) = m \bigr\}. \]
- For a given real number $c$ describe the sets \[ \bigl\{ \mathbf{x} \in \mathbb{R}^n \, : \, Q(\mathbf{x}) = c \bigr\} \] In particular, describe the sets \[ \bigl\{ \mathbf{x} \in \mathbb{R}^n \, : \, Q(\mathbf{x}) = -1 \bigr\}, \quad \bigl\{ \mathbf{x} \in \mathbb{R}^n \, : \, Q(\mathbf{x}) = 0 \bigr\}, \quad \bigl\{ \mathbf{x} \in \mathbb{R}^n \, : \, Q(\mathbf{x}) = 1 \bigr\}. \]
- Suggested problems for Section 7.2: 1, 3, 5, 7, 9, 13, 17, 19, 20, 21, 23, 25
- In Sections 7.2 and 7.3 we study quadratic forms.
-
A quadratic form in $n$ variables is a special kind of function $Q:\mathbb{R}^n \to \mathbb{R}.$ Below are few examples of quadratic forms
- Below are three specific quadratic forms in two variables: \[ Q(x_1,x_2) = 6 x_1^2 - 4 x_1 x_2 + 3 x_2^2, \qquad (x_1,x_2) \in \mathbb{R}^2 \] \[ Q(x_1,x_2) = x_1^2 + 6 x_1 x_2 + x_2^2, \qquad (x_1,x_2) \in \mathbb{R}^2 \] \[ Q(x_1,x_2) = 4 x_1^2 + 4 x_1 x_2 + x_2^2, \qquad (x_1,x_2) \in \mathbb{R}^2 \] In general, a quadratic form $Q$ in two variables $x_1,x_2$ is a function defined on $\mathbb{R}^2$ with the values in $\mathbb{R}$ which can be expressed as \[ Q(x_1,x_2) = a\, x_1x_1 + b\, x_1x_2 + c\, x_2x_2, \qquad (x_1,x_2) \in \mathbb{R}^2, \] where $a, b, c$ are real coefficients.
- Below are three specific quadratic forms in three variables: \[ Q(x_1,x_2,x_3) = x_1^2 -4x_1 x_2 +4 x_2 x_3 - x_3^2, \qquad (x_1,x_2,x_3) \in \mathbb{R}^3, \] \[ Q(x_1,x_2,x_3) = 4x_1 x_2 + 2 x_1 x_3 + 3 x_2^2 + 4 x_2 x_3, \qquad (x_1,x_2,x_3) \in \mathbb{R}^3, \] \[ Q(x_1,x_2,x_3) = 2 x_1^2 + 2 x_1 x_2 + 2 x_1 x_3 + 2 x_2^2 + 2 x_2 x_3 + 2 x_3^2, \qquad (x_1,x_2,x_3) \in \mathbb{R}^3, \] In general, a quadratic form $Q$ in three variables $x_1,x_2,x_3$ is a function defined on $\mathbb{R}^3$ with the values in $\mathbb{R}$ which can be expressed as \[ Q(x_1,x_2,x_3) = a\, x_1x_1 + b\, x_1x_2 + c\, x_1x_3 + d\, x_2 x_2 + e\, x_2 x_3 + f\, x_3 x_3, \quad (x_1,x_2,x_3) \in \mathbb{R}^3, \] where $a, b, c, d, e, f$ are real coefficients.
- A quadratic form $Q$ in four variables $x_1,x_2,x_3,x_4$ is a function defined on $\mathbb{R}^4$ with the values in $\mathbb{R}$ which is a linear combination of the following ten terms \[ x_1x_1. \quad x_1x_2, \quad x_1x_3, \quad x_1 x_4, \quad x_2 x_2, \quad x_2 x_3, \quad x_2x_4, \quad x_3 x_3, \quad x_3 x_4, \quad x_4 x_4. \] In other words, a quadratic form in four variables is a polynomial in four variables which contains only terms of degree $2.$
- In general, a quadratic form in $n$ variables is a polynomial in $n$ variables which contains only terms of degree $2.$ To be more specific, for $j, k \in \{1,\ldots,n\}$ with $j \leq k$ let us define the functions $q_{jk}:\mathbb{R}^n \to \mathbb{R}$ by \[ q_{jk}(\mathbf{x}) = x_j x_k, \qquad \mathbf{x} = (x_1,\ldots,x_n) \in \mathbb{R}^n. \] Notice that there are $\binom{n+1}{2} = \frac{n(n+1)}{2}$ such functions. A linear combination of the functions $q_{jk}(\mathbf{x})$ with $j, k \in \{1,\ldots,n\}$ with $j \leq k$, is called a quadratic form in $n$ variables.
- For us the most important fact about quadratic forms is that for each quadratic form $Q$ in $n$ variables there exists a unique symmetric $n\!\times\!n$ matrix $A$ such that \[ Q(\mathbf{x}) = (A\mathbf{x})\cdot \mathbf{x} \quad \text{for all} \quad \mathbf{x} \in \mathbb{R}^n. \] Such matrix $A$ is called the matrix of a quadratic form.
- In the above example, for all $(x_1,x_2) \in \mathbb{R}^2$ we have \[ Q(x_1,x_2) = a\, x_1x_1 + b\, x_1x_2 + c\, x_2x_2 = \left(\left[\! \begin{array}{cc} a & b/2 \\ b/2 & c \end{array} \!\right] \left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right] \right) \cdot \left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right] \] And for all $(x_1,x_2,x_3) \in \mathbb{R}^3$ we have \[ Q(x_1,x_2,x_3) = a\, x_1x_1 + b\, x_1x_2 + c\, x_1x_3 + d\, x_2 x_2 + e\, x_2 x_3 + f\, x_3 x_3 = \left(\left[\! \begin{array}{ccc} a & b/2 & c/2 \\ b/2 & d & e/2 \\ c/2 & e/2 & f \end{array} \!\right] \left[\! \begin{array}{c} x_1 \\ x_2 \\ x_3 \end{array} \!\right] \right) \cdot \left[\! \begin{array}{c} x_1 \\ x_2 \\ x_3 \end{array} \!\right] \]
-
In this item I will write about polychotomies in mathematics. A polychotomy is a partition of a given set of mathematical objects into disjoint classes which are all given distinct names.
-
A dichotomy is a partition of a given set of mathematical objects into two disjoint classes each of which is given a name. The following are examples of dichotomies.
- The most important dichotomy for numbers is the partition of numbers into the singleton set $\{0\}$ consisting of only zero and the set of all nonzero numbers. Further, dichotomy for the nonzero real numbers is the partition of the nonzero real numbers into positive real numbers and negative real numbers.
- An important dichotomy for the set of real numbers is the partition into rational and irrational numbers.
- A useful dichotomy for complex numbers is the partition of the complex numbers into the real and nonreal numbers. A complex number $z$ is said to be nonreal if the imaginary part of $z$ is nonzero.
- Consider the set of all square matrices. A square matrix $M$ is said to be singular if $\det M = 0.$ A square matrix $M$ is said to be nonsingular if $\det M \neq 0.$ You also learned that a square matrix is invertible if and only if it is nonsingular. Thus, singular-invertible is a dichotomy for square matrices.
-
A trichotomy is a partition of a given set of mathematical objects into three disjoint classes each of which is given a name. The following are examples of trichotomies.
- The most important trichotomy for the set of real numbers is the partition of numbers into singleton set $\{0\}$ consisting of only zero, the set of positive real numbers and the set of negative real numbers. As we mention before this trichotomy arrises as two dichotomies.
- In high school you learned about the trichotomy involving quadratic equations $a x^2 + b x + c = 0$ with $a\neq 0.$ Such equation can have: no solutions, exactly one solution, and exactly two solutions.
-
A quadruplicity is a partition of a given set of mathematical objects into four disjoint classes each of which is given a name. I started writing about polychotomies because of the following quadruplicity which arises with quadratic forms.
-
Let $Q : \mathbb R^n \to \mathbb R$ be a quadratic form. We distinguish the following four types of quadratic forms:
- $Q$ is said to be a zero quadratic form if $Q(\mathbf x) = 0$ for all $\mathbf x \in \mathbb R^n.$
- $Q$ is said to be a positive semidefinite quadratic form if $Q(\mathbf x) \geq 0$ for all $\mathbf x \in \mathbb R^n$ and there exists $\mathbf v \in \mathbb R^n$ such that $Q(\mathbf v) \gt 0.$
- $Q$ is said to be a negative semidefinite quadratic form if $Q(\mathbf x) \leq 0$ for all $\mathbf x \in \mathbb R^n$ and there exists $\mathbf v \in \mathbb R^n$ such that $Q(\mathbf v) \lt 0.$
- $Q$ is said to be an indefinite quadratic form if there exists $\mathbf v \in \mathbb R^n$ such that $Q(\mathbf v) \gt 0$ and there exists $\mathbf u \in \mathbb R^n$ such that $Q(\mathbf u) \lt 0.$
- $Q$ is said to be a positive definite quadratic form if $Q(\mathbf x) \gt 0$ for all $\mathbf x \in \mathbb R^n\!\setminus\!\{\mathbf 0\}.$
- $Q$ is said to be a negative definite quadratic form if $Q(\mathbf x) \lt 0$ for all $\mathbf x \in \mathbb R^n\!\setminus\!\{\mathbf 0\}.$
In the image below I give a graphical representation of the above quadruplicity. The red dot represents the zero quadratic form, the green region represents the positive semidefinite quadratic forms, the blue region represents the negative semidefinite quadratic forms and the cyan region represents the indefinite quadratic forms.
In the image above, the dark green region represents the positive definite quadratic forms and the dark blue region represents the negative definite quadratic forms. These two regions are not parts of the above quadruplicity.
-
Let $Q : \mathbb R^n \to \mathbb R$ be a quadratic form. We distinguish the following four types of quadratic forms:
-
A dichotomy is a partition of a given set of mathematical objects into two disjoint classes each of which is given a name. The following are examples of dichotomies.
- Suggested problems for Section 7.1: 3, 4, 9, 11, 15, 19, 23, 24, 25, 27, 30, 33, 35.
-
In the first Theorem in the next item we work with complex numbers. We review some basic facts about complex numbers.
The Complex Numbers. A complex number is commonly represented as $z = x + i y$ where $i$ is the imaginary unit with the property $i^2 = -1$ and $x$ and $y$ are real numbers. The real number $x$ is called the real part of $z$ and the real number $y$ is called the imaginary part of $z.$ A real number is a special complex numbers whose imaginary part is $0.$ The set of all complex numbers is denoted by $\mathbb C.$
The Complex Conjugate. By $\overline{z}$ we denote the complex conjugate of $z$. The complex conjugate of $z = x+i y$ is the complex number $\overline{z} = x - i y.$ That is, the complex conjugate $\overline{z}$ is the complex numer which has the same real part as $z$ and the imaginary part of $\overline{z}$ is the opposite of the imaginary part of $z.$ Since $-0 = 0$, a comlex number $z$ is real if and only if $\overline{z} = z.$ The operation of complex conjugation respects the algebraic operations with complex numbers: \[ \overline{z + w} = \overline{z} + \overline{w}, \quad \overline{z - w} = \overline{z} - \overline{w}, \quad \overline{z\, w} = \overline{z}\, \overline{w}. \]
The Modulus. Let $z = x + i y$ be a complex number. Here $x$ is the real part of $z$ and $y$ is the imaginary part of $z.$ The modulus of $z$ is the nonnegative number $\sqrt{x^2+y^2}.$ The modulus of $z$ is denoted by $|z|.$ Clearly, $|z|^2 = z\overline{z}$.
Vectors with Complex Entries. Let $\mathbf v$ be a vector with complex entries. By $\overline{\mathbf{v}}$ we denote the vector whose entries are complex conugates of the corresponding entries of $\mathbf v.$ That is, \[ \mathbf v = \left[\begin{array}{c} v_1 \\ \vdots \\ v_n \end{array} \right], \qquad \overline{\mathbf v} = \left[\begin{array}{c} \overline{v}_1 \\ \vdots \\ \overline{v}_n \end{array} \right]. \] The following calculation for a vector with complex entries is often useful \[ \mathbf{v}^\top \overline{\mathbf{v}} = \bigl[v_1 \ \ v_2 \ \ \cdots \ \ v_n \bigr] \left[\begin{array}{c} \overline{v}_1 \\ \overline{v}_2 \\ \vdots \\ \overline{v}_n \end{array} \right] = \sum_{k=1}^n v_k\, \overline{v}_k = \sum_{k=1}^n |v_k|^2 \geq 0. \] Moreover, \[ \mathbf{v}^\top \overline{\mathbf{v}} = 0 \quad \text{if and only if} \quad \mathbf{v} = \mathbf{0}. \]
-
There are several important theorems in Section 7.1. Their proofs are presented in this item.
Theorem. All eigenvalues of a symmetric matrix are real.
Proof. Let $A$ be a symmetric $n\!\times\!n$ matrix and let $\lambda$ be an eigenvalue of $A$. Let $\mathbf{v} = \bigl[v_1 \ \ v_2 \ \ \cdots \ \ v_n \bigr]^\top$ be a corresponding eigenvector. Then $\mathbf{v} \neq \mathbf{0}.$ We allow the possibility that $\lambda$ and the entries $v_1,$ $v_2,\ldots,$ $v_n$ of $\mathbf{v}$ are complex numbers. Since $\mathbf{v}$ is an eigenvector of $A$ corresponding to $\lambda$ we have \[ A \mathbf{v} = \lambda \mathbf{v}. \] Since $A$ is a symmetric matrix, all the entries of $A$ are real numbers. It follows from the properties of the complex conjugation that taking the complex conjugate of each side of the equality $A \mathbf{v} = \lambda \mathbf{v}$ yields \[ A \overline{\mathbf{v}} = \overline{\lambda} \overline{\mathbf{v}}. \] Since $A$ is symmetric, that is $A=A^\top$, we also have \[ A^\top \overline{\mathbf{v}} = \overline{\lambda} \overline{\mathbf{v}}. \] Multiplying both sides of the last equation by $\mathbf{v}^\top$ we get \[ \mathbf{v}^\top \bigl( A^\top \overline{\mathbf{v}} \bigr) = \mathbf{v}^\top ( \overline{\lambda} \overline{\mathbf{v}}). \] Since $\mathbf{v}^\top A^\top = \bigl(A\mathbf{v}\bigr)^\top$ and $\mathbf{v}^\top ( \overline{\lambda} \overline{\mathbf{v}}) = \overline{\lambda} \mathbf{v}^\top \overline{\mathbf{v}}$ the last displayed equality is equivalent to \[ \bigl(A\mathbf{v}\bigr)^\top \overline{\mathbf{v}} = \overline{\lambda} \mathbf{v}^\top \overline{\mathbf{v}}. \] Since $A \mathbf{v} = \lambda \mathbf{v},$ we further have \[ \bigl(\lambda \mathbf{v}\bigr)^\top \overline{\mathbf{v}} = \overline{\lambda} \mathbf{v}^\top \overline{\mathbf{v}}. \] That is, \[ \tag{*} \lambda \mathbf{v}^\top \overline{\mathbf{v}} = \overline{\lambda} \mathbf{v}^\top \overline{\mathbf{v}}. \] As explained in Vectors with Complex Entries item, $\mathbf{v} \neq \mathbf{0},$ implies $\mathbf{v}^\top \overline{\mathbf{v}} \gt 0.$ Now dividing both sides of equality (*) by $\mathbf{v}^\top \overline{\mathbf{v}} \gt 0$ yields \[ \lambda = \overline{\lambda}. \] As explained in The Complex Conjugate item above, this proves that $\lambda$ is a real number.
Theorem. Eigenspaces of a symmetric matrix which correspond to distinct eigenvalues are orthogonal.
Theorem. A symmetric $2\!\times\!2$ matrix is orthogonally diagonalizable.
Proof. Let $A = \begin{bmatrix} a & b \\ b & d \end{bmatrix}$ be an arbitrary $2\!\times\!2$ be a symmetric matrix. We need to prove that there exists an orthogonal $2\!\times\!2$ matrix $U$ and a diagonal $2\!\times\!2$ matrix $D$ such that $A = UDU^\top.$ The eigenvalues of $A$ are \[ \lambda_1 = \frac{1}{2} \Bigl( a+d - \sqrt{(a-d)^2 + 4 b^2} \Bigr), \quad \lambda_2 = \frac{1}{2} \Bigl( a+d + \sqrt{(a-d)^2 + 4 b^2} \Bigr) \] If $\lambda_1 = \lambda_2$, then $(a-d)^2 + 4 b^2 = 0$, and consequently $b= 0$ and $a=d$; that is $A = \begin{bmatrix} a & 0 \\ 0 & a \end{bmatrix}$. Hence $A = UDU^\top$ holds with $U=I_2$ and $D = A$.
Now assume that $\lambda_1 \neq \lambda_2$. Let $\mathbf{u}_1$ be a unit eigenvector corresponding to $\lambda_1$ and let $\mathbf{u}_2$ be a unit eigenvector corresponding to $\lambda_2$. We proved that eigenvectors corresponding to distinct eigenvalues of a symmetric matrix are orthogonal. Since $A$ is symmetric, $\mathbf{u}_1$ and $\mathbf{u}_2$ are orthogonal, that is the matrix $U = \begin{bmatrix} \mathbf{u}_1 & \mathbf{u}_2 \end{bmatrix}$ is orthogonal. Since $\mathbf{u}_1$ and $\mathbf{u}_2$ are eigenvectors of $A$ we have \[ AU = U \begin{bmatrix} \lambda_1 & 0 \\ 0 & \lambda_2 \end{bmatrix} = UD. \] Therefore $A=UDU^\top.$ This proves that $A$ is orthogonally diagonalizable.
Second Proof. Let $A = \begin{bmatrix} a & b \\ b & d \end{bmatrix}$ an arbitrary $2\!\times\!2$ be a symmetric matrix. If $b=0$, then an orthogonal diagonalization is \[ \begin{bmatrix} a & 0 \\ 0 & d \end{bmatrix} = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}\begin{bmatrix} a & 0 \\ 0 & d \end{bmatrix}\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}. \]
Assume that $b\neq0.$ For the given $a,b,c \in \mathbb{R},$ introduce three new coordinates $z \in \mathbb{R},$ $r \in (0,+\infty),$ and $\theta \in (0,\pi)$ such that \begin{align*} z & = \frac{a+d}{2}, \\ r & = \sqrt{\left( \frac{a-d}{2} \right)^2 + b^2}, \\ \cos(2\theta) & = \frac{\frac{a-d}{2}}{r}, \quad \sin(2\theta) = \frac{b}{r}. \end{align*} The reader will notice that these coordinates are very similar to the cylindrical coordinates in $\mathbb{R}^3.$
It is now an exercise in matrix multiplication and trigonometry to calculate \begin{align*} & \begin{bmatrix} \cos(\theta) & -\sin(\theta) \\ \sin(\theta) & \cos(\theta) \end{bmatrix} \begin{bmatrix} z+r & 0 \\ 0 & z-r \end{bmatrix}\begin{bmatrix} \cos(\theta) & \sin(\theta) \\ -\sin(\theta) & \cos(\theta) \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} \cos(\theta) & -\sin(\theta) \\ \sin(\theta) & \cos(\theta) \end{bmatrix} \begin{bmatrix} (z+r) \cos(\theta) & (z+r) \sin(\theta) \\ (r-z)\sin(\theta) & (z-r) \cos(\theta) \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} (z+r) (\cos(\theta))^2 - (r-z)(\sin(\theta))^2 & (z+r) \cos(\theta) \sin(\theta) -(z-r) \cos(\theta) \sin(\theta) \\ (z+r) \cos(\theta) \sin(\theta) + (r-z) \cos(\theta) \sin(\theta) & (z+r) (\sin(\theta))^2 + (z-r)(\cos(\theta))^2 \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} z + r \cos(2\theta) & r \sin(2\theta) \\ r \sin(2\theta) & z - r \cos(2\theta) \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} \frac{a+d}{2} + \frac{a-d}{2} & b \\ b & \frac{a+d}{2} - \frac{a-d}{2} \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} a & b \\ b & d \end{bmatrix}. \end{align*}Theorem. For every positive integer $n$, a symmetric $n\!\times\!n$ matrix is orthogonally diagonalizable.
Proof. This statement can be proved by Mathematical Induction. The base case $n = 1$ is trivial. The case $n=2$ is proved above. To get a feel how mathematical induction proceeds we will prove the theorem for $n=3.$
Let $A$ be a $3\!\times\!3$ symmetric matrix. Then $A$ has an eigenvalue, which must be real. Denote this eigenvalue by $\lambda_1$ and let $\mathbf{u}_1$ be a corresponding unit eigenvector. Let $\mathbf{v}_1$ and $\mathbf{v}_2$ be unit vectors such that the vectors $\mathbf{u}_1,$ Let $\mathbf{v}_1$ and $\mathbf{v}_2$ form an orthonormal basis for $\mathbb R^3.$ Then the matrix $V_1 = \bigl[\mathbf{u}_1 \ \ \mathbf{v}_1\ \ \mathbf{v}_2\bigr]$ is an orthogonal matrix and we have \[ V_1^\top A V_1 = \begin{bmatrix} \mathbf{u}_1^\top A \mathbf{u}_1 & \mathbf{u}_1^\top A \mathbf{v}_1 & \mathbf{u}_1^\top A \mathbf{v}_2 \\[5pt] \mathbf{v}_1^\top A \mathbf{u}_1 & \mathbf{v}_1^\top A \mathbf{v}_1 & \mathbf{v}_1^\top A \mathbf{v}_2 \\[5pt] \mathbf{v}_2^\top A \mathbf{u}_1 & \mathbf{v}_2^\top A \mathbf{v}_1 & \mathbf{v}_2^\top A \mathbf{v}_2 \\\end{bmatrix}. \] Since $A = A^\top$, $A\mathbf{u}_1 = \lambda_1 \mathbf{u}_1$ and since $\mathbf{u}_1$ is orthogonal to both $\mathbf{v}_1$ and $\mathbf{v}_2$ we have \[ \mathbf{u}_1^\top A \mathbf{u}_1 = \lambda_1, \quad \mathbf{v}_j^\top A \mathbf{u}_1 = \lambda_1 \mathbf{v}_j^\top \mathbf{u}_1 = 0, \quad \mathbf{u}_1^\top A \mathbf{v}_j = \bigl(A \mathbf{u}_1\bigr)^\top \mathbf{v}_j = 0, \quad \quad j \in \{1,2\}, \] and \[ \mathbf{v}_2^\top A \mathbf{v}_1 = \bigl(\mathbf{v}_2^\top A \mathbf{v}_1\bigr)^\top = \mathbf{v}_1^\top A^\top \mathbf{v}_2 = \mathbf{v}_1^\top A \mathbf{v}_2. \] Hence, \[ \tag{**} V_1^\top A V_1 = \begin{bmatrix} \lambda_1 & 0 & 0 \\[5pt] 0 & \mathbf{v}_1^\top A \mathbf{v}_1 & \mathbf{v}_1^\top A \mathbf{v}_2 \\[5pt] 0 & \mathbf{v}_1^\top A \mathbf{v}_2 & \mathbf{v}_2^\top A \mathbf{v}_2 \\\end{bmatrix}. \] By the already proved theorem for $2\!\times\!2$ symmetric matrix there exists an orthogonal matrix $\begin{bmatrix} u_{11} & u_{12} \\[5pt] u_{21} & u_{22} \end{bmatrix}$ and a diagonal matrix $\begin{bmatrix} \lambda_2 & 0 \\[5pt] 0 & \lambda_3 \end{bmatrix}$ such that \[ \begin{bmatrix} \mathbf{v}_1^\top A \mathbf{v}_1 & \mathbf{v}_1^\top A \mathbf{v}_2 \\[5pt] \mathbf{v}_1^\top A \mathbf{v}_2 & \mathbf{v}_2^\top A \mathbf{v}_2 \end{bmatrix} = \begin{bmatrix} u_{11} & u_{12} \\[5pt] u_{21} & u_{22} \end{bmatrix} \begin{bmatrix} \lambda_2 & 0 \\[5pt] 0 & \lambda_3 \end{bmatrix} \begin{bmatrix} u_{11} & u_{12} \\[5pt] u_{21} & u_{22} \end{bmatrix}^\top. \] Substituting this equality in (**) and using some matrix algebra we get \[ V_1^\top A V_1 = \begin{bmatrix} 1 & 0 & 0 \\[5pt] 0 & u_{11} & u_{12} \\[5pt] 0 & u_{21} & u_{22} \end{bmatrix} % \begin{bmatrix} \lambda_1 & 0 & 0 \\[5pt] 0 & \lambda_2 & 0 \\[5pt] 0 & 0 & \lambda_3 \end{bmatrix} % \begin{bmatrix} 1 & 0 & 0 \\[5pt] 0 & u_{11} & u_{12} \\[5pt] 0 & u_{21} & u_{22} \end{bmatrix}^\top \] Setting \[ U = V_1 \begin{bmatrix} 1 & 0 & 0 \\[5pt] 0 & u_{11} & u_{12} \\[5pt] 0 & u_{21} & u_{22} \end{bmatrix} \quad \text{and} \quad D = \begin{bmatrix} \lambda_1 & 0 & 0 \\[5pt] 0 & \lambda_2 & 0 \\[5pt] 0 & 0 & \lambda_3 \end{bmatrix} \] we have that $U$ is an orthogonal matrix, $D$ is a diagonal matrix and $A = UDU^\top.$ This proves that $A$ is orthogonally diagonalizable.
- Consider the following $3\!\times\!4$ matrix \[ A = \left[\! \begin{array}{rrrr} 2 & -4 & -1 & 4 \\ 1 & -2 & 1 & 5 \\ -1 & 2 & 3 & 3 \end{array} \!\right]. \] Studying this matrix and the corresponding linear transformation from $\operatorname{Row}A$ onto $\operatorname{Col}A$ will help you answer Problem 6 on Assignment 1.
- First row reduce $A$: \begin{align*} \left[\!\begin{array}{rrrr} 2 & -4 & -1 & 4 \\ 1 & -2 & 1 & 5 \\ -1 & 2 & 3 & 3 \end{array}\!\right] & \sim \left[\!\begin{array}{rrrr} 1 & -2 & 1 & 5 \\ 2 & -4 & -1 & 4 \\ -1 & 2 & 3 & 3 \end{array}\!\right] \\ & \sim \left[\!\begin{array}{rrrr} 1 & -2 & 1 & 5 \\ 0 & 0 & -3 & -6 \\ 0 & 0 & 4 & 8 \end{array}\!\right] \\ & \sim \left[\!\begin{array}{rrrr} 1 & -2 & 1 & 5 \\ 0 & 0 & 1 & 2 \\ 0 & 0 & 4 & 8 \end{array}\!\right] \\ & \sim \left[\!\begin{array}{rrrr} 1 & -2 & 0 & 3 \\ 0 & 0 & 1 & 2 \\ 0 & 0 & 0 & 0 \end{array}\!\right] \\ \end{align*}
-
The amazing apect of RREF of $A$ is that the product of the $3\!\times\!2$ matrix consisting of the pivot columns of $A$ by the $2\!\times\!4$ matrix consisting of the nonzero rows of the RREF of $A$ equals the original matrix $A$ (please verify the calculation yourself):
\[
\left[\!\begin{array}{rr}
2 & -1 \\
1 & 1\\
-1 & 3
\end{array}\!\right]
\left[\!\begin{array}{rrrr}
1 & -2 & 0 & 3\\
0 & 0 & 1 & 2\end{array}\!\right] = \left[\!\begin{array}{rrrr}
2 & -4 & -1 & 4 \\
1 & -2 & 1 & 5 \\
-1 & 2 & 3 & 3
\end{array}\!\right]
\]
The above super important matrix equality is loaded with information.
- Column Info in the above super important matrix equality tells us that each column of $A$ is a linear combination of the pivot columns. Moreover, pay attention, the coefficients with the pivot columns come from the columns of $\left[\!\begin{array}{rrrr} 1 & -2 & 0 & 3\\ 0 & 0 & 1 & 2\end{array}\!\right]$ \begin{align*} \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] & = 1 \, \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] + 0 \, \left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right] \\ \left[\!\begin{array}{r} -4 \\ -2\\ 2 \end{array}\!\right] & = (-2) \, \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] + 0 \, \left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right] \\ \left[\!\begin{array}{r} -1 \\ 1\\ 3 \end{array}\!\right] & = 0 \, \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] + 1 \, \left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right] \\ \left[\!\begin{array}{r} 4 \\ 5\\ 3 \end{array}\!\right] & = 3 \, \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] + 2 \, \left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right] \\ \end{align*}
- Row Info in the above super important matrix equality tells us that each row of $A$ is a linear combination of the nonzero rows of the RREF of $A$. Moreover, pay attention, the coefficients with the nonzero rows of RREF come from the rows of $\left[\!\begin{array}{rr} 2 & -1 \\ 1 & 1\\ -1 & 3 \end{array}\!\right]$: \begin{align*} \left[\!\begin{array}{r} 2 \\ -4\\ -1\\ 4 \end{array}\!\right] & = 2 \, \left[\!\begin{array}{r} 1 \\ -2\\ 0 \\ 3 \end{array}\!\right] + (-1) \, \left[\!\begin{array}{r} 0 \\ 0 \\ 1 \\ 2\end{array}\!\right], \\ \left[\!\begin{array}{r} 1 \\ -2\\ 1\\ 5 \end{array}\!\right] & = 1 \, \left[\!\begin{array}{r} 1 \\ -2\\ 0 \\ 3 \end{array}\!\right] + 1 \, \left[\!\begin{array}{r} 0 \\ 0 \\ 1 \\ 2 \end{array}\!\right], \\ \left[\!\begin{array}{r} - 1 \\ 2\\ 3\\ 3 \end{array}\!\right] & = (-1) \, \left[\!\begin{array}{r} 1 \\ -2\\ 0 \\ 3 \end{array}\!\right] + 3 \, \left[\!\begin{array}{r} 0 \\ 0 \\ 1 \\ 2 \end{array}\!\right] \end{align*}
-
What have we learned about the column space of $A$ which is denoted by $\operatorname{Col}A$? The column space of $A$ is defined as the span of the columns of $A$:
\[
\boxed{
\operatorname{Col}A = \operatorname{Span}\left\{ \left[\! \begin{array}{r}
2 \\
1 \\
-1
\end{array} \!\right],
\left[\! \begin{array}{r}
-4 \\
-2 \\
2
\end{array} \!\right],
\left[\! \begin{array}{r}
-1 \\
1 \\
3
\end{array} \!\right],
\left[\! \begin{array}{r}
4 \\
5 \\
3
\end{array} \!\right]
\right\}.
}
\]
In words, the column space of $A$ is the set of all linear combinations of the columns of $A.$ Since each column of $A$ is in $\mathbb{R}^3$, the column space is a subspace of $\mathbb{R}^3.$
- First recall that in the Column Info from the above super important matrix equality we deduced that each column of $A$ is a linear combination of the pivot columns. Therefore \[ \operatorname{Col}A = \operatorname{Span}\left\{ \left[\! \begin{array}{r} 2 \\ 1 \\ -1 \end{array} \!\right], \left[\! \begin{array}{r} -1 \\ 1 \\ 3 \end{array} \!\right] \right\}. \]
- Next we use the equivalence that we used before: for all $\left[\!\begin{array}{c} x_1\\ x_2 \\ x_3 \\ x_4 \end{array}\!\right] \in \mathbb{R}^4$ we have \[ \left[\!\begin{array}{rrrr} 2 & -4 & -1 & 4 \\ 1 & -2 & 1 & 5 \\ -1 & 2 & 3 & 3 \end{array}\!\right] \left[\!\begin{array}{c} x_1\\ x_2 \\ x_3 \\ x_4 \end{array}\!\right] = \left[\!\begin{array}{c} 0\\ 0 \\ 0 \end{array}\!\right] \quad \text{if and only if} \quad \left[\!\begin{array}{rrrr} 1 & -2 & 0 & 3\\ 0 & 0 & 1 & 2\end{array}\!\right] \left[\!\begin{array}{c} x_1\\ x_2 \\ x_3 \\ x_4 \end{array}\!\right] = \left[\!\begin{array}{c} 0\\ 0 \end{array}\!\right]. \] Interestingly, we use this equivalence for special vectors in $\mathbb{R}^4$: for all $\left[\!\begin{array}{c} x_1\\ 0 \\ x_3 \\ 0 \end{array}\!\right] \in \mathbb{R}^4$ we have \[ \left[\!\begin{array}{rrrr} 2 & -4 & -1 & 4 \\ 1 & -2 & 1 & 5 \\ -1 & 2 & 3 & 3 \end{array}\!\right] \left[\!\begin{array}{c} x_1\\ 0 \\ x_3 \\ 0 \end{array}\!\right] = \left[\!\begin{array}{c} 0\\ 0 \\ 0 \end{array}\!\right] \quad \text{if and only if} \quad \left[\!\begin{array}{rrrr} 1 & -2 & 0 & 3\\ 0 & 0 & 1 & 2\end{array}\!\right] \left[\!\begin{array}{c} x_1\\ 0 \\ x_3 \\ 0 \end{array}\!\right] = \left[\!\begin{array}{c} 0 \\ 0 \end{array}\!\right]. \] Written as a vector equation the above equivalence reads: \[ x_1 \left[\!\begin{array}{r} 2 \\ 1 \\ -1 \end{array}\!\right] + x_3 \left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right] = \left[\!\begin{array}{c} 0\\ 0 \\ 0 \end{array}\!\right] \quad \text{if and only if} \quad x_1 \left[\!\begin{array}{r} 1\\ 0 \end{array}\!\right] + x_3 \left[\!\begin{array}{c} 0\\ 1 \end{array}\!\right] = \left[\!\begin{array}{c} 0 \\ 0 \end{array}\!\right]. \] The last equivalence proves that the pivot columns $\left[\!\begin{array}{r} 2 \\ 1 \\ -1 \end{array}\!\right]$ and $\left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right]$ are linearly independent. Thus, \[ \operatorname{Col}A = \operatorname{Span}\left\{ \left[\! \begin{array}{r} 2 \\ 1 \\ -1 \end{array} \!\right], \left[\! \begin{array}{r} -1 \\ 1 \\ 3 \end{array} \!\right] \right\} \] and the two vectors that span $\operatorname{Col}A$ form a basis for $\operatorname{Col}A$. Therefore $\operatorname{Col}A$ is two-dimensional.
- Next we name the above basis for $\operatorname{Col}A$ \[ \mathcal{C} = \left\{ \left[\! \begin{array}{r} 2 \\ 1 \\ -1 \end{array} \!\right], \left[\! \begin{array}{r} -1 \\ 1 \\ 3 \end{array} \!\right] \right\} \]
- With this notation we can express the Colomn Info by using the language of the coordinates relative to the basis $\mathcal{C}.$: \begin{alignat*}{2} \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] & = 1 \, \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] + 0 \, \left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right], \quad & \text{that is} \quad \left[\!\left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right]\!\right]_{\mathcal{C}} & = \left[\!\begin{array}{r} 1 \\ 0 \end{array}\!\right] \\ \left[\!\begin{array}{r} -4 \\ -2\\ 2 \end{array}\!\right] & = (-2) \, \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] + 0 \, \left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right], \quad & \text{that is} \quad \left[\!\left[\!\begin{array}{r} -4 \\ -2\\ 2 \end{array}\!\right]\!\right]_{\mathcal{C}} & = \left[\!\begin{array}{r} -2 \\ 0 \end{array}\!\right] \\ \left[\!\begin{array}{r} -1 \\ 1\\ 3 \end{array}\!\right] & = 0 \, \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] + 1 \, \left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right], \quad & \text{that is} \quad \left[\!\left[\!\begin{array}{r} -1 \\ 1\\ 3 \end{array}\!\right]\!\right]_{\mathcal{C}} & = \left[\!\begin{array}{r} 0 \\ 1 \end{array}\!\right] \\ \left[\!\begin{array}{r} 4 \\ 5\\ 3 \end{array}\!\right] & = 3 \, \left[\!\begin{array}{r} 2 \\ 1\\ -1 \end{array}\!\right] + 2 \, \left[\!\begin{array}{r} -1 \\ 1 \\ 3 \end{array}\!\right], \quad & \text{that is} \quad \left[\!\left[\!\begin{array}{r} 4 \\ 5\\ 3 \end{array}\!\right]\!\right]_{\mathcal{C}} & = \left[\!\begin{array}{r} 3 \\ 2 \end{array}\!\right] \\ \end{alignat*}
-
Next we study the row space of $A$ which is denoted by $\operatorname{Row}A$. The row space of $A$ is defined as the span of the rows of $A$:
\[
\operatorname{Row}A = \operatorname{Span}\left\{ \left[\! \begin{array}{r}
2 \\
-4 \\
-1 \\
4
\end{array} \!\right],
\left[\! \begin{array}{r}
1 \\
-2 \\
1 \\
5
\end{array} \!\right],
\left[\! \begin{array}{r}
-1 \\
2 \\
3 \\
3
\end{array} \!\right] \right\} = \operatorname{Col}\bigl(A^\top\bigr).
\]
In words, the row space of $A$ is the set of all linear combinations of the rows of $A.$ Since each row of $A$ is in $\mathbb{R}^4$, the row space is a subspace of $\mathbb{R}^4.$
- Now we recall the Row Info from the above super important matrix equality. We deduced that each row of $A$ is a linear combination of the nonzero rows of the RREF of $A.$ Therefore \[ \operatorname{Row}A = \operatorname{Span}\left\{ \left[\! \begin{array}{r} 1 \\ -2 \\ 0 \\ 3 \end{array} \!\right], \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \\ 2 \end{array} \!\right] \right\}. \]
- It is clear that two vectors that span $\operatorname{Row}A$ are linearly independent. Therefore we have a basis for $\operatorname{Row}A.$ Consequently, $\operatorname{Row}A$ is two-dimensional. Denote this basis for $\operatorname{Row}A$ by $\mathcal{B}.$ That is \[ \mathcal{B} = \left\{ \left[\! \begin{array}{r} 1 \\ -2 \\ 0 \\ 3 \end{array} \!\right], \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \\ 2 \end{array} \!\right] \right\}. \]
- With this notation we can express the Row Info by using the language of the coordinates relative to the basis $\mathcal{B}.$: \begin{alignat*}{2} \left[\!\begin{array}{r} 2 \\ -4\\ -1\\ 2 \end{array}\!\right] & = (2) \, \left[\!\begin{array}{r} 1 \\ -2 \\ 0 \\ 3 \end{array}\!\right] + (-1) \, \left[\!\begin{array}{r} 0 \\ 0 \\ 1\\ 2 \end{array}\!\right], \quad & \text{that is} \quad \left[\!\left[\!\begin{array}{r} 2 \\ -4\\ -1\\ 2 \end{array}\!\right]\!\right]_{\mathcal{B}} & = \left[\!\begin{array}{r} 2 \\ -1 \end{array}\!\right] \\ \left[\!\begin{array}{r} 1 \\ -2\\ 1\\ 5 \end{array}\!\right] & = (1) \, \left[\!\begin{array}{r} 1 \\ -2 \\ 0 \\ 3 \end{array}\!\right] + (1) \, \left[\!\begin{array}{r} 0 \\ 0 \\ 1\\ 2 \end{array}\!\right], \quad & \text{that is} \quad \left[\!\left[\!\begin{array}{r} 1 \\ -2\\ 1\\ 5 \end{array}\!\right]\!\right]_{\mathcal{B}} & = \left[\!\begin{array}{r} 1 \\ 1 \end{array}\!\right] \\ \left[\!\begin{array}{r} -1 \\ 2\\ 3\\ 3 \end{array}\!\right] & = (-1) \,\left[\!\begin{array}{r} 1 \\ -2 \\ 0 \\ 3 \end{array}\!\right] + (3) \, \left[\!\begin{array}{r} 0 \\ 0 \\ 1\\ 2 \end{array}\!\right], \quad & \text{that is} \quad \left[\!\left[\!\begin{array}{r} -1 \\ 2\\ 3\\ 3\end{array}\!\right]\!\right]_{\mathcal{B}} & = \left[\!\begin{array}{r} -1 \\ 3 \end{array}\!\right] \\ \end{alignat*}
- Assignment 1 is due on Tuesday, November 12.
- Suggested problems for Section 6.6: 1, 2, 3, 4, 5, 6, 7, 8, 9, 14, 15, 16
-
Exercise 4 in Section 6.6 is a simple interesting problem. In this exercise we are given four data points
\[
( 2,3), \ \ (3,2), \ \ (5,1), \ \ (6,0),
\]
and we are asked to find the least-squares line that best fits the given data points. (We will call this line simply the least-squares line.)
- Notice that these four points form a very narrow parallelogram. A characterizing property of a parallelogram is that its diagonals share the midpoint. For this parallelogram, the coordinates of the common midpoint of the diagonals are \[ \overline{x} = \frac{1}{4}(2+3+5+6) = 4, \quad \overline{y} = \frac{1}{4}(3+2+1+0) = 3/2. \] The long sides of this parallelogram are on the parallel lines $y = -2x/3 +4$ and $y = -2x/3 + 13/3.$ It is natural to guess that the least square line is the line which is parallel to these two lines and half-way between them. That is the line $y = -2x/3 + 25/6.$ This line is the red line in the picture below. Clearly this line goes through the point $(4,3/2),$ the intersection of the diagonals of the parallelogram. The only way to verify this guess is to calculate the least-squares line for these four points. We did that by finding the least-squares solution of the equation \[ \left[\begin{array}{cc} 1 & 2 \\ 1 & 3 \\ 1 & 5 \\ 1 & 6 \end{array} \right] \left[\begin{array}{c} \beta_0 \\ \beta_1 \end{array} \right] = \left[\begin{array}{c} 3 \\ 2 \\ 1 \\ 0 \end{array} \right]. \] The corresponding normal equation is \[ \left[\begin{array}{cc} 4 & 16 \\ 16 & 74 \end{array} \right] \left[\begin{array}{c} \beta_0 \\ \beta_1 \end{array} \right] = \left[\begin{array}{c} 6 \\ 17 \end{array} \right]. \] Since the inverse of the above $2\!\times\!2$ matrix is \[ \frac{1}{40} \left[\begin{array}{cc} 74 & -16 \\ -16 & 4 \end{array} \right], \] the least-squares line for the given data points is \[ y = -\frac{7}{10}x + \frac{43}{10}. \] This line is the blue line in the picture below. The picture below strongly indicates that the blue line also goes through the point $(4,3/2).$ This is easily confirmed: \[ \frac{3}{2} = -\frac{7}{10}4 + \frac{43}{10}. \]
In the image below the the forest green points are the given data points. The red line is the line which I guessed could be the least-squares line. The blue line is the true least-squares line.
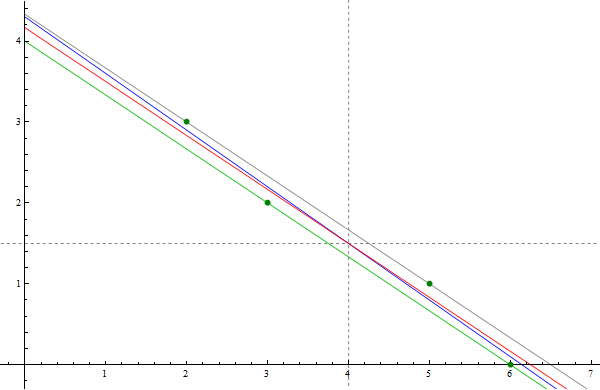
-
It is amazing that what we observed in the preceeding example is a universal:
Proposition. If the line $y = \beta_0 + \beta_1 x$ is the least-squares line for the data points \[ (x_1,y_1), \ldots, (x_n,y_n), \] then $\overline{y} = \beta_0 + \beta_1 \overline{x}$, where \[ \overline{x} = \frac{1}{n}(x_1+\cdots+x_n), \quad \overline{y} = \frac{1}{n}(y_1+\dots+y_n). \]
The above proposition is Exercise 14 in Section 6.6.Proof. Let \[ (x_1,y_1), \ldots, (x_n,y_n), \] be given data points and set \[ \overline{x} = \frac{1}{n}(x_1+\cdots+x_n), \quad \overline{y} = \frac{1}{n}(y_1+\dots+y_n). \] Let $y = \beta_0 + \beta_1 x$ be the least-squares line for the given data points. Then the vector $\left[\begin{array}{c} \beta_0 \\ \beta_1 \end{array} \right]$ satisfies the normal equation \[ \left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ x_1 & x_2 & \cdots & x_n \end{array} \right] \left[\begin{array}{cc} 1 & x_1 \\ 1 & x_2 \\ \vdots & \vdots \\ 1 & x_n \end{array} \right] \left[\begin{array}{c} \beta_0 \\ \beta_1 \end{array} \right] = \left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ x_1 & x_2 & \cdots & x_n \end{array} \right] \left[\begin{array}{c} y_1 \\ y_2 \\ \vdots \\ y_n \end{array} \right]. \] Multiplying the second matrix on the left-hand side and the third vector we get \[ \left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ x_1 & x_2 & \cdots & x_n \end{array} \right] \left[\begin{array}{c} \beta_0 + \beta_1 x_1 \\ \beta_0 + \beta_1 x_2 \\ \vdots \\ \beta_0 + \beta_1 x_n \end{array} \right] = \left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ x_1 & x_2 & \cdots & x_n \end{array} \right] \left[\begin{array}{c} y_1 \\ y_2 \\ \vdots \\ y_n \end{array} \right]. \] The above equality is an equality of vectors with two components. The top components of these vectors are equal: \[ (\beta_0 + \beta_1 x_1) + (\beta_0 + \beta_1 x_2) + \cdots + (\beta_0 + \beta_1 x_n) = y_1 + y_2 + \cdots + y_n. \] Therefore \[ n \beta_0 + \beta_1 (x_1+x_3 + \cdots + x_n) = y_1 + y_2 + \cdots + y_n. \] Dividing by $n$ we get \[ \beta_0 + \beta_1 \frac{1}{n} (x_1+x_3 + \cdots + x_n) = \frac{1}{n}( y_1 + y_2 + \cdots + y_n). \] Hence \[ \overline{y} = \beta_0 + \beta_1 \overline{x}. \]
The proof ends here. -
Do the following problem: Consider the following four data points
\[
( 0, 0, 5), \ \ (3, 0, 6), \ \ (3, 3, 14), \ \ (0, 3, 9).
\]
- Find the equation $z = \beta_0 + \beta_1 x +\beta_2 y$ of the least-squares plane that best fits the data points.
- Find the coordinates of the dark green points and the teal points in the picture below.
- Calculate the residual vector and the least-squares error.
- Find the equation of the plane through the data points \[ ( 0, 0, 5), \ \ (3, 0, 6), \ \ (0, 3, 9). \] Show that the least-squares error is larger for this plane than the error for the least-squares plane.
In this image the the navy blue points are the given data points and the light blue plane is the least-squares plane that best fits these data points. The dark green points are their projections onto the $xy$-plane. The teal points are the corresponding points in the least-square plane.
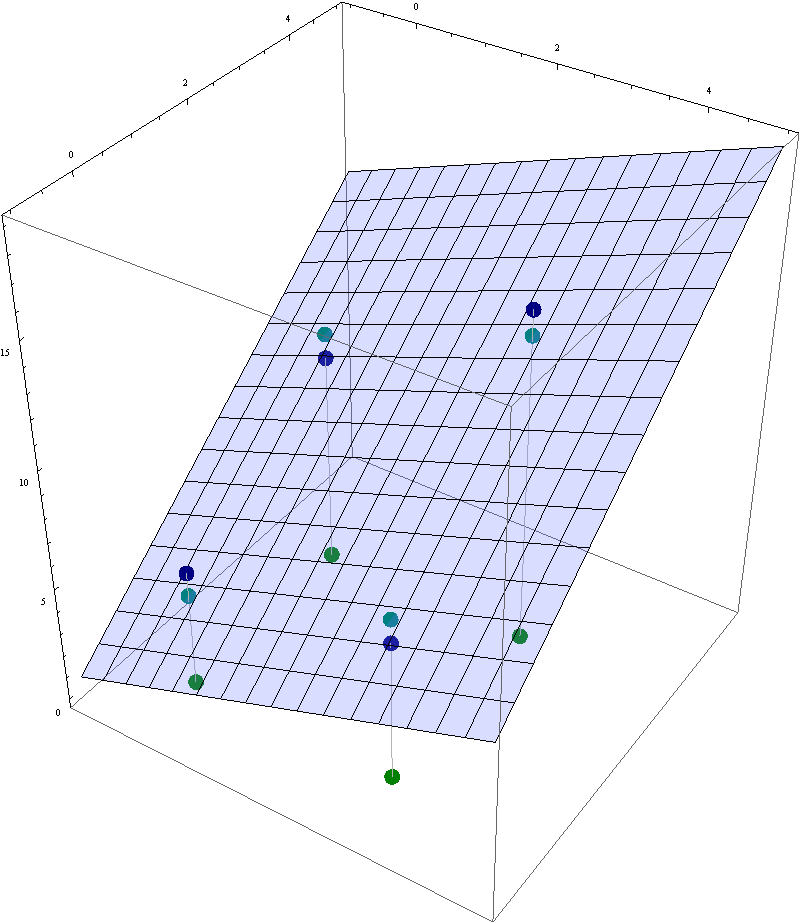
- Suggested problems for Section 6.5: 1, 3, 6, 7, 9, 13, 16, 17, 19, 20, 21, 22
-
Exercise 19 in Section 6.5 is very important. In fact, Exercise 19 in Section 6.5 is the following theorem:
Theorem. Let $A$ be an $n\!\times\!m$ matrix. Then $\operatorname{Nul}(A^\top\!\! A ) = \operatorname{Nul}(A)$.
Proof. The set equality $\operatorname{Nul}(A^\top\!\! A ) = \operatorname{Nul}(A)$ means \[ \vec{x} \in \operatorname{Nul}(A^\top\!\! A ) \quad \text{if and only if} \quad \vec{x} \in \operatorname{Nul}(A). \] So, we prove this equivalence. Assume that $\vec{x} \in \operatorname{Nul}(A)$. Then $A\vec{x} = \vec{0}$. Consequently, $A^\top\!A\vec{x} = A^\top\vec{0} = \vec{0}$. Hence, $A^\top\!A\vec{x}= \vec{0}$, and therefore $\vec{x} \in \operatorname{Nul}(A^\top\!\! A )$. This proves, \[ \vec{x} \in \operatorname{Nul}(A) \quad \Rightarrow \quad \vec{x} \in \operatorname{Nul}(A^\top\!\! A ). \] Now we prove the converse, \[ \tag{*} \vec{x} \in \operatorname{Nul}(A^\top\!\! A ) \quad \Rightarrow \quad \vec{x} \in \operatorname{Nul}(A). \] Assume, $\vec{x} \in \operatorname{Nul}(A^\top\!\! A )$. Then, $A^\top\!\!A \vec{x} = \vec{0}$. Multiplying the last equality by $\vec{x}^\top$ we get $\vec{x}^\top\! (A^\top\!\! A \vec{x}) = 0$. Using the associativity of the matrix multiplication we obtain $(\vec{x}^\top\!\! A^\top)A \vec{x} = 0$. Using the Linear Algebra with the transpose operation we get $(A \vec{x})^\top\!A \vec{x} = 0$. Now recall that for every vector $\vec{v}$ we have $\vec{v}^\top \vec{v} = \|\vec{v}\|^2$. Thus, we have proved that $\|A\vec{x}\|^2 = 0$. Now recall that the only vector whose norm is $0$ is the zero vector, to conclude that $A\vec{x} = \vec{0}$. This means $\vec{x} \in \operatorname{Nul}(A)$. This completes the proof of implication (*). The theorem is proved.
Corollary. Let $A$ be an $n\!\times\!m$ matrix. The columns of $A$ are linearly independent if and only if the $m\!\times\!m$ matrix $A^\top\!\! A$ is invertible.
Corollary. Let $A$ be an $n\!\times\!m$ matrix. Then $\operatorname{Col}(A^\top\!\! A ) = \operatorname{Col}(A^\top)$.
Corollary. Let $A$ be an $n\!\times\!m$ matrix. The matrices $A^\top$ and $A^\top\!\! A$ have the same rank.
Corollary. Let $A$ be an $n\!\times\!m$ matrix. The matrix $A^\top\!\! A$ is invertible if and only if the columns of $A$ are linearly independent.
- Suggested problems for Section 6.4: 2, 3, 5, 7, 9, 13, 15, 17, 19, 20
- The presentation of the $QR$ factorization in the textbook somewhat obscures the direct connection between the Gram-Schmidt orthogonalization algorithm and the $QR$ factorization. Below I will demonstrate the connection.
- Let $\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_m$ be linearly independent vectors in $\mathbb{R}^n$. The Gram-Schmidt orthogonalization algorithm produces the mutually orthogonal vectors \begin{align*} \mathbf{v}_1 & = \mathbf{x}_1 \\ \mathbf{v}_2 & = \mathbf{x}_2 - \frac{\mathbf{x}_2\cdot \mathbf{v}_1}{\mathbf{v}_1 \cdot \mathbf{v}_1} \mathbf{v}_1 \\ \mathbf{v}_3 & = \mathbf{x}_3 - \frac{\mathbf{x}_3\cdot \mathbf{v}_1}{\mathbf{v}_1 \cdot \mathbf{v}_1} \mathbf{v}_1 - \frac{\mathbf{x}_3\cdot \mathbf{v}_2}{\mathbf{v}_2 \cdot \mathbf{v}_2} \mathbf{v}_2 \\ & \ \ \vdots \\ \mathbf{v}_m & = \mathbf{x}_m - \frac{\mathbf{x}_m\cdot \mathbf{v}_1}{\mathbf{v}_1 \cdot \mathbf{v}_1} \mathbf{v}_1 - \cdots - \frac{\mathbf{x}_m\cdot \mathbf{v}_{m-1}}{\mathbf{v}_{m-1} \cdot \mathbf{v}_{m-1}} \mathbf{v}_{m-1} \\ \end{align*} We can rewrite the above vector equations as \begin{align*} \mathbf{x}_1 & = \mathbf{v}_1 \\ \mathbf{x}_2 & = \frac{\mathbf{x}_2\cdot \mathbf{v}_{1}}{\mathbf{v}_{1} \cdot \mathbf{v}_{1}} \mathbf{v}_1 + \mathbf{v}_2 \\ \mathbf{x}_3 & = \frac{\mathbf{x}_3\cdot \mathbf{v}_{1}}{\mathbf{v}_{1} \cdot \mathbf{v}_{1}} \mathbf{v}_1 + \frac{\mathbf{x}_3\cdot \mathbf{v}_{2}}{\mathbf{v}_{2} \cdot \mathbf{v}_{2}} \mathbf{v}_2 + \mathbf{v}_3 \\ & \ \ \vdots \\ \mathbf{x}_m & = \frac{\mathbf{x}_m\cdot \mathbf{v}_{1}}{\mathbf{v}_{1} \cdot \mathbf{v}_{1}} \mathbf{v}_1 + \cdots + \frac{\mathbf{x}_m\cdot \mathbf{v}_{m-1}}{\mathbf{v}_{m-1} \cdot \mathbf{v}_{m-1}} \mathbf{v}_{m-1} + \mathbf{v}_m \\ \end{align*} Now set \[ \mathbf{u}_k = \frac{1}{\|\mathbf{v}_k\|} \mathbf{v}_k \quad \text{for} \quad k \in \{1,\ldots,m\} \] and use the fact that $\mathbf{v}_k \cdot \mathbf{v}_k = \|\mathbf{v}_k\|^2$ to rewrite the vectors $\mathbf{x}_1,\dots, \mathbf{x}_m$ in terms of the orthonormal vectors $\mathbf{u}_1,\ldots,\mathbf{u}_m$: \begin{align*} \mathbf{x}_1 & = \|\mathbf{v}_1\| \mathbf{u}_1 \\ \mathbf{x}_2 & = \frac{\mathbf{x}_2\cdot \mathbf{v}_{1}}{\|\mathbf{v}_1\|} \mathbf{u}_1 + \|\mathbf{v}_2\| \mathbf{u}_2 \\ \mathbf{x}_3 & = \frac{\mathbf{x}_3\cdot \mathbf{v}_{1}}{\|\mathbf{v}_1\|} \mathbf{u}_1 + \frac{\mathbf{x}_3\cdot \mathbf{v}_{2}}{\|\mathbf{v}_2\|} \mathbf{u}_2 + \|\mathbf{v}_3\| \mathbf{u}_3 \\ & \ \ \vdots \\ \mathbf{x}_m & = \frac{\mathbf{x}_m\cdot \mathbf{v}_{1}}{\|\mathbf{v}_1\|} \mathbf{u}_1 + \cdots + \frac{\mathbf{x}_m\cdot \mathbf{v}_{m-1}}{\|\mathbf{v}_{m-1}\|} \mathbf{u}_{m-1} + \|\mathbf{v}_m\| \mathbf{u}_m \end{align*} Now set \[ \alpha_{jk} = \frac{\mathbf{x}_k\cdot \mathbf{v}_{j}}{\|\mathbf{v}_j\|} = \mathbf{x}_k\cdot \mathbf{u}_{j} \quad \text{for} \quad j \in \{1,\ldots,k-1\}, \ \ k \in \{2,\ldots,m\} \] and the above equations can be rewritten as \begin{align*} \mathbf{x}_1 & = \|\mathbf{v}_1\| \mathbf{u}_1 \\ \mathbf{x}_2 & = \alpha_{1,2} \mathbf{u}_1 + \|\mathbf{v}_2\| \mathbf{u}_2 \\ \mathbf{x}_3 & = \alpha_{1,3} \mathbf{u}_1 + \alpha_{2,3} \mathbf{u}_2 + \|\mathbf{v}_3\| \mathbf{u}_3 \\ & \ \ \vdots \\ \mathbf{x}_m & = \alpha_{1,m} \mathbf{u}_1 + \cdots + \alpha_{m-1,m} \mathbf{u}_{m-1} + \|\mathbf{v}_m\| \mathbf{u}_m \\ \end{align*} These vector equations can be written in matrix form as \[ \left[\begin{array}{ccccc} \mathbf{x}_1 & \mathbf{x}_2 & \mathbf{x}_3 & \cdots & \mathbf{x}_m \end{array} \right] = \left[\begin{array}{ccccc} \mathbf{u}_1 & \mathbf{u}_2 & \mathbf{u}_3 & \cdots & \mathbf{u}_m \end{array} \right] \left[\begin{array}{ccccc} \|\mathbf{v}_1\| & \alpha_{1,2} & \alpha_{1,3} & \cdots & \alpha_{1,m} \\ 0 & \|\mathbf{v}_2\| & \alpha_{2,3} & \cdots & \alpha_{2,m} \\ 0 & 0 & \|\mathbf{v}_3\| & \cdots & \alpha_{3,m} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \cdots & \|\mathbf{v}_m\| \\ \end{array} \right] \] The above matrix equation is the $QR$ factorization \[ A = QR \] with \begin{align*} A & = \left[\begin{array}{ccccc} \mathbf{x}_1 & \mathbf{x}_2 & \mathbf{x}_3 & \cdots & \mathbf{x}_m \end{array} \right] \\ Q & = \left[\begin{array}{ccccc} \mathbf{u}_1 & \mathbf{u}_2 & \mathbf{u}_3 & \cdots & \mathbf{u}_m \end{array} \right] \end{align*} and the matrix $R$ is an upper triangular matrix with positive terms on the diagonal. Since the vectors $\mathbf{u}_1, \mathbf{u}_2,\ldots, \mathbf{u}_m$ are orthonormal, we have $Q^{\top} Q = I_m$. Therefore the $m\!\times\!m$ matrix $R$ can be calculated as $R = Q^{\top}A$.
-
Next I will state the $QR$ factorization of a matrix with linearly independent columns as a theorem.
Theorem. Every $n\times m$ matrix $A$ with linearly independent columns can be written as a product $A = QR$ where $Q$ is an $n\times m$ matrix whose columns form an orthonormal basis for the column space of $A$ and $R$ is an $m\times m$ upper triangular invertible matrix with positive entries on its diagonal.
- The $QR$ factorization of a matrix is just the Gram-Schmidt orthogonalization process for the columns of $A$ written in matrix form. The only difference is that a Gram-Schmidt orthogonalization process produces orthogonal vectors which we have to normalize to obtain the matrix $Q$ with orthonormal columns. A nice simple example is given by the $3\!\times\!2$ matrix \[ A = \left[ \begin{array}{rr} 1 & 1 \\[2pt] 2 & 4 \\[2pt] 2 & 3 \end{array}\right]. \] Denote the columns of $A$ by $\mathbf{a}_1$ and $\mathbf{a}_2$. The Gram-Schmidt orthogonalization of the vectors $\mathbf{a}_1$ and $\mathbf{a}_2$ leads to vectors \[ \mathbf{v}_1 = \left[ \begin{array}{r} 1 \\[2pt] 2 \\[2pt] 2 \end{array}\right], \quad \mathbf{v}_2 = \left[ \begin{array}{r} -2/3 \\[2pt] 2/3 \\[2pt] 1/3 \end{array}\right]. \] These vectors are calculated as \[ \tag{*} \mathbf{v}_1 = \mathbf{a}_1, \quad \mathbf{v}_2 = \mathbf{a}_2 - \frac{5}{3} \mathbf{v}_1. \] Next we normalize the vectors $\mathbf{v}_1$ and $\mathbf{v}_2$. The norm of vector $\mathbf{v}_1$ is $3$ and the norm of $\mathbf{v}_2$ is 1. Hence the following vectors are orthonormal: \[ \mathbf{u}_1 = \frac{1}{3} \left[ \begin{array}{r} 1 \\[2pt] 2 \\[2pt] 2 \end{array}\right], \quad \mathbf{u}_2 = \frac{1}{3} \left[ \begin{array}{r} -2 \\[2pt] 2 \\[2pt] 1 \end{array}\right]. \] We can rewrite equalities (*) using the vectors $\mathbf{u}_1$ and $\mathbf{u}_2$ as follows \[ \tag{**} \mathbf{a}_1 = 3\, \mathbf{u}_1 = 3\, \mathbf{u}_1 + 0\, \mathbf{u}_2, \quad \mathbf{a}_2 = \frac{5}{3} \, 3\, \mathbf{u}_1 + \mathbf{u}_2 = 5\,\mathbf{u}_1 + \mathbf{u}_2. \] In matrix form the equalities (**) can be written as \[ A = Q \left[ \begin{array}{rr} 3 & 5 \\[2pt] 0 & 1 \end{array}\right], \] where \[ Q = \frac{1}{3} \left[ \begin{array}{rr} 1 & -2 \\[2pt] 2 & 2 \\[2pt] 2 & 1 \end{array}\right] \] is a matrix with orthonormal columns and its column space is identical to the columns space of the matrix $A$. Here \[ R = \left[ \begin{array}{rr} 3 & 5 \\[2pt] 0 & 1 \end{array}\right]. \] Notice that on the diagonal of the matrix $R$ are the norms of the vectors $\mathbf{v}_1$ and $\mathbf{v}_2$ which we obtained by the Gram-Schmidt orthogonalization algorithm. Since the matrix $Q$ has orthonormal columns we have $Q^\top Q = I_2$. Therefore the matrix $R$ can be calculated as \[ R = Q^\top A. \] This might be simpler than making adjustments to the coefficients of the Gram-Schmidt orthogonalization algorithm as we did in this simple example. However, it is good to know that $R$ is closely related to those coefficients.
-
Next, I want to prove that $QR$ factorization of a matrix $A$ with linearly independent columns is unique. Here is a proof.
In the next proof I am experimenting with a new way of presenting a theorem and its proof. Each theorem consists of assumptions and a claim. In the theorem below I label the assumptions by green labels with two capital letters. In this theorem they are BA, AQ, AR and QR. These are short abbreviations of the content of the assumptions. Here they are, respecitively, Basic Assumptions, Assumtions about $Q$, Assumtions about $R$, $QR$ factorizations are assumed. I label the claim of the theorem by two or three capital letters in red. Here it is QRU (standing for $QR$ is Unique). The logic for selecting green and red is that the assumtions are a pleasant part of a theorem and the claim is an unpleasant part since we have to strugle intellectually to prove the claim. Although this intellectual challenge should be a pleasant task, there is a certain level of uncertainty associated associated with it.
A vital part of each proof are facts that we know from previously proved theorems. These facts give a proof its flow. Here I list all such facts and label them with green labels since they are known and useful for our task at hand. Here they are UP (Upper trianglular Product), UI (Upper trianglular Inverse).
I introduced a blue label for a comment. Here UTP introduces a notation for Upper Triangular matrices with Positive terms on diagaonal.
What is a proof?
A proof is a procedure which uses previously stated (assumed or known) green labeled facts and logic to produce new green labeled facts. The goal of a proof is to produce a sequence of green labeled facts that will terminate with the (red labeled) claim of the theorem. In terms of the colors, the goal of a proof is to greenify the red claim of a theorem.Theorem
Assumptions
- BA. $A$ is an $n\!\times\!m$ real matrix with linearly independent columns.
- AQ. Assume $Q_1, Q_2$ are $n\!\times\!m$ real matrices such that \[ Q_1^{\top} Q_1 = I_m \quad \text{and} \quad Q_2^{\top} Q_2 = I_m \]
- AR. Assume $R_1, R_2$ are $m\!\times\!m$ real upper triangular matrices with positive entries on the diagonals.
- QR. Assume $A = Q_1 R_1$ and $A = Q_2 R_2$
- QRU. Then $Q_1 = Q_2$ and $R_1 = R_2$.
In the proof ot the theorem we use the following facts that have been established elsewhere.- UP. The product of two upper triangular matrices with positive entries on the diagonals is an upper triangular matrix with positive entries on the diagonal.
- UI. The inverse of an upper triangular matrix with positive entries on the diagonal is an upper triangular matrix with positive entries on the diagonal.
- UTP. UP and UI show that the set of upper triangular matrices with positive entries on the diagonals forms a multiplicative group. Basically it behaves as the set of positive real numbers with respect to multiplication. We will use the abbreviation a "UTP matrix" for an "upper triangular matrix with positive entries on the diagonal."
The proof starts here.- NR. By UI and AR the matrix $R_2$ is invertible and $R_2^{-1}$ is a UTP matrix. By UP the matrix $R= R_1 R_2^{-1}$ is a UTP matrix. In particular, $R$ is invertible.
- RQ1. By QR and NR we have \[ \tag{RQ} Q_1 R_1 R_2^{-1} = Q_1 R = Q_2. \] Multiplying (RQ) from the left by $Q_1^{\top}$ and using AQ we get \[ R = Q_1^{\top} Q_2. \]
- RQ2. Multiplying (RQ) from the left by $Q_2^{\top}$ and using AQ we get \[ Q_2^{\top} Q_1 R = I_m. \] Thus, \[ R^{-1} = Q_2^{\top} Q_1. \]
- RI. Notice that from RQ1 and RQ2 we have \[ R^{\top} = \bigl( Q_1^{\top} Q_2 \bigr)^{\top} = Q_2^{\top} Q_1 = R^{-1}. \] The equlity $R^{\top} = R^{-1}$ is vital to this proof: by the definition of the transpose and AR $R^T$ is a lover triangular matrix with the same positive diagonal entries as $R,$ while, by NR and UI, $R^{-1}$ is an upper triangular matrix with the diagonal entries which are reciprocals of the diagonal entries of $R.$ Consequently, $R^{\top} = R^{-1}$ yields that $R^{\top} = R^{-1}$ is a diagonal matrix whose entries on the diagonal are positive real numbers which equal their reciprocals. Since the only positive real number which equals its reciprocal is the number $1$, we conclude that all the diagonal entries of $R^{\top} = R^{-1}$ are $1$. Thus \[ R = I_m. \] QRU. By RI and NR \[ R_1R_2^{-1} = R = I_m. \] Thus $R_1 = R_2$. By equation (RQ) in RQ1 and RI we get \[ Q_1 = Q_2. \]
- Since the red QRU has been turn into green QRU the proof has been completed.
- Find $QR$ factorizations of the following matrices \[ \left[ \begin{array}{ccc} -1 & -1 & 3 \\ 1 & 5 & -1 \\ 1 & 1 & 3 \\ -1 & -5 & 7 \end{array} \right] \quad \left[ \begin{array}{ccc} 6 & 8 & 7 \\ 3 & 6 & 0 \\ 2 & 2 & 0 \end{array} \right] \quad \left[ \begin{array}{ccc} 2 & 2 & 1 \\ 1 & 2 & 8 \\ 2 & 3 & 1 \end{array} \right] \quad \left[ \begin{array}{ccc} 4 & -1 & -7 \\ 2 & 8 & 7 \\ 2 & 4 & -8 \\ 1 & 5 & 5 \end{array} \right] \] \[ \left[ \begin{array}{ccc} 2 & -6 & 4 \\ -5 & 9 & 1 \\ 4 & 4 & 9 \\ 2 & -4 & 5 \end{array} \right] \]
- Suggested problems for Section 6.4: 2, 3, 5, 7, 9, 13, 15, 17, 19, 20
- We finished Section 6.3 today. Suggested problems are: 1, 2, 4, 5, 7, 10, 11, 13, 15, 16 17, 19, 20, 21, 23
- There are two important theorems in Section 6.3: The Best Approximation Theorem (Theorem 9) and Theorem 10 which I would call Standard Matrix of an Orthogonal Projection.
-
The proof of Theorem 10 given in the book is deceptively simple. Please do understand the proof in the book. Below I will give another proof of this theorem.
I believe that it is helpful to split a proof into smaller parts and label those parts in a mnemonic way. The explanations of the labels below are as follows: AW. The assumption about $\mathcal{W},$ AON. The assumption about orthonormal basis, SM. the claim about Standard Matrix, UOC. a fact about $U$ which has Orthonormal Columns, TDP. a fact abour Transpose and Dot Product, WCU. $\mathcal{W}$ is the Column space of $U,$ DOP. Definition of the Orthogonal Projection.Thorem
Assumptions
- AW. $\mathcal W$ is a subspace of $\mathbb R^n,$ $\mathbf u_1, \ldots, \mathbf u_m \in \mathcal W,$ and \[ \mathcal W = \operatorname{span} \{ \mathbf u_1, \ldots, \mathbf u_m \} \]
- AON. The set $\{ \mathbf u_1, \ldots, \mathbf u_m \}$ is an orthonormal set.
- SM. For every $\mathbf y \in \mathbb R^n$ we have \[ \operatorname{Proj}_{\mathcal W} \mathbf y = UU^\top \mathbf y, \] where \[ U = \bigl[ \mathbf{u}_1 \, \cdots \, \mathbf{u}_m \bigr] \]
In the proof ot the theorem we use the following facts that have been established elsewhere.- UOC. Since AON holds, the matrix $U$ is an $n\!\times\!m$ matrix with orthonormal columns. Therefore, by Theorem 6 on page 390, we have $U^\top U = I_m.$
- TDP. Let $A$ be an $m\!\times\!n$ matrix. Then for every $\mathbf v \in \mathbb R^m$ and every $\mathbf x \in \mathbb R^n$ we have \[ \mathbf v \cdot (A \mathbf x) = \bigl(A^\top \mathbf v\bigr) \cdot \mathbf x. \]
- WCU. By AW and the definition of a column space we have $\mathcal W = \operatorname{Col} U.$
- DOP. Let $\mathbf y \in \mathbb R^n.$ By the definition of the orthogonal projection we have $\widehat{\mathbf y} = \operatorname{Proj}_{\mathcal W} \mathbf y$ if and only if \[ \widehat{\mathbf y} \in {\mathcal W} \quad \text{and} \quad ( \mathbf y - \widehat{\mathbf y} ) \cdot \mathbf w = 0 \quad \text{for all} \quad \mathbf w \in \mathcal W. \]
The proof starts here.
Let $\mathbf y \in \mathbb R^n$ be arbitrary. By DOP, to prove that \[ UU^\top \mathbf y = \operatorname{Proj}_{\mathcal W} \mathbf y \] we have to prove that \[ UU^\top \mathbf y \in {\mathcal W} \] and \[ \bigl( \mathbf y - UU^\top \mathbf y \bigr) \cdot \mathbf w = 0 \quad \text{for all} \quad \mathbf w \in \mathcal W. \] Clearly, $UU^\top \mathbf y \in \operatorname{Col} U.$ By WCU we have $\operatorname{Col} U = \mathcal W.$ Therefore, $UU^\top \mathbf y \in {\mathcal W}$ is proved.
Again, by WCU we have $\mathcal W = \operatorname{Col} U.$ Therefore the last displayed relation can be rewritten as \[ \bigl( \mathbf y - UU^\top \mathbf y \bigr) \cdot (U \mathbf a) = 0 \quad \text{for all} \quad \mathbf a \in \mathbb R^m. \] Let $\mathbf a \in \mathbb R^m$ be arbitrary and calculate \begin{alignat*}{2} \bigl( \mathbf y - UU^\top \mathbf y \bigr) \cdot (U \mathbf a) & = \mathbf y \cdot (U \mathbf a) - \bigl( UU^\top \mathbf y \bigr) \cdot (U \mathbf a) \qquad & \text{by TDP} \\ &= \bigl( U^\top \mathbf y \bigr) \cdot \mathbf a - \bigl( U^\top UU^\top \mathbf y \bigr) \cdot \mathbf a \qquad &\text{by UOC}\\ & = \bigl( U^\top \mathbf y \bigr) \cdot \mathbf a - \bigl(I_m U^\top \mathbf y \bigr) \cdot \mathbf a & \\ & = \bigl( U^\top \mathbf y \bigr) \cdot \mathbf a - \bigl( U^\top \mathbf y \bigr) \cdot \mathbf a & \\ & = 0 \end{alignat*} The first equality above follows from the distributivity of the inner product, the second equality follows from TDP and the third equality follows from UOC.
Since $\mathbf a \in \mathbb R^m$ was arbitrary the last calculation and WCU yield \[ \bigl( \mathbf y - UU^\top \mathbf y \bigr) \cdot \mathbf w = 0 \quad \text{for all} \quad \mathbf w \in \mathcal W. \] By DOP this proves that \[ \operatorname{Proj}_{\mathcal W} \mathbf y = UU^\top \mathbf y. \] The proof ends here.
- We started Section 6.2 today. Suggested problems are: 2, 3, 5, 8, 9, 11, 13, 15, 17, 19, 21, 23, 25, 26, 27, 29.
- You need to know how to prove Theorem 4 in Section 6.2.
- An additional exercise for Section 6.1. Let \[ \mathbf{u} = \left[\! \begin{array}{r} 1 \\ -1 \\ 2 \\ -1 \end{array} \!\right], \quad \mathbf{v} = \left[\! \begin{array}{r} -3 \\ 3 \\ 2 \\ -5 \end{array} \!\right]. \] Let $\mathcal{W} = \operatorname{Span}\{\mathbf{u}, \mathbf{v}\}.$ Calculate $\mathcal{W}^\perp.$ Find vectors $\mathbf{x}$ and $\mathbf{y}$ such that \[ \mathcal{W}^\perp = \operatorname{Span}\{\mathbf{x}, \mathbf{y}\}. \] The idea here is to use the relationship \[ \bigl(\operatorname{Row} A\bigr)^\perp = \operatorname{Nul} A \] which holds for arbitrary $m\!\times\!n$ matrix $A.$ So, choose $A$ such that \[ \operatorname{Row} A = \operatorname{Span}\{\mathbf{u}, \mathbf{v}\}. \] Then, \[ \mathcal{W}^\perp = \operatorname{Nul} A. \]
- We did Section 6.1 today. Suggested problems: 1, 5, 7, 8, 9-12, 13, 15-18, 20, 22, 24, 25, 26, 27, 28, 29, 30, 31, 32 (do this problem by hand), 33 (do this problem by hand).
- Here is a proof of the Law of Cosines and its connection to dot product.
- Here is a proof of the classical Pythagorean Theorem.
- Here is a list of topics for the first exam.
- Today we did Section 5.5. Suggested problems for Section 5.5: 1-6, 7-12, 13, 16, 17, 18, 21, 25, 26.
- A brief summary of Section 5.5 is as follows. Let $A$ be a real $2\!\times\!2$ matrix. Assume that $A$ has a complex eigenvalue $\lambda = a - i b$, where $a,b \in \mathbb{R}$ with $b\neq0$, and that a corresponding eigenvector is \[ \mathbf{u} + i \mathbf{v} \quad \text{where} \quad \mathbf{u}, \mathbf{v} \in \mathbb{R}^2. \] That is we assume \[ A (\mathbf{u} + i \mathbf{v}) = (a-i b) (\mathbf{u} + i \mathbf{v}). \] Using the linearity of the matrix-vector multiplication and algebra with vectors we can rewrite the preceding equality as \[ A \mathbf{u} + i A \mathbf{v} = (a \mathbf{u} + b \mathbf{v}) + i (- b \mathbf{u} + a \mathbf{v}). \] Since the vectors $A \mathbf{u}$, $A \mathbf{v}$ and $a \mathbf{u} + b \mathbf{v}$, $- b \mathbf{u} + a \mathbf{v}$ are vectors with real entries the preceding equality implies that \begin{align*} A \mathbf{u} & = a \mathbf{u} + b \mathbf{v} \\ A \mathbf{v} & = - b \mathbf{u} + a \mathbf{v} . \end{align*} The last two equalities can be rewritten as one matrix equality \[ A \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] = \bigl[ A\mathbf{u} \ \ A\mathbf{v} \bigr] = \bigl[ a \mathbf{u} + b \mathbf{v} \ \ \ - b \mathbf{u} + a \mathbf{v} \bigr]. \] The last matrix can be factored as \[ \bigl[ a \mathbf{u} + b \mathbf{v} \ \ \ - b \mathbf{u} + a \mathbf{v} \bigr] = \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right]. \] Finaly, the last two equalities yield \[ A \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] = \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right]. \] It can be proved that the real vectors $\mathbf{u}$ and $\mathbf{v}$ are linearly independent, so the real $2\!\times\!2$ matrix $\bigl[ \mathbf{u} \ \ \mathbf{v} \bigr]$ is invertible. Therefore, \[ A = \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right] \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr]^{-1}. \] The matrix \[ \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right] \] is a composition of a scaling and a rotation. To see that factor \[ \sqrt{a^2+b^2} \left[\! \begin{array}{rr} \frac{a}{\sqrt{a^2+b^2}} & -\frac{b}{\sqrt{a^2+b^2}} \\ \frac{b}{\sqrt{a^2+b^2}} & \frac{a}{\sqrt{a^2+b^2}} \end{array} \!\right]. \] Since \[ \left( \frac{a}{\sqrt{a^2+b^2}} \right)^2 + \left( \frac{b}{\sqrt{a^2+b^2}} \right)^2 = 1, \] there exists an angle $\theta \in [0,2\pi)$ such that \[ \cos \theta = \frac{a}{\sqrt{a^2+b^2}}, \quad \sin \theta = \frac{b}{\sqrt{a^2+b^2}} . \] Thus, with $c = \sqrt{a^2+b^2}$ we have \[ \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right] = c \left[\! \begin{array}{rr} \cos\theta & -\sin \theta \\ \sin\theta & \cos\theta \end{array} \!\right]. \]
- Here is an example of the above procedure. Consider the matrix \[ \left[\! \begin{array}{rr} 1 & -3 \\ 6 & 7 \end{array} \!\right]. \] The eigenvalues of this matrix are \[ 4 - 3i \qquad \text{and} \qquad 4+3i. \] The corresponding eigenvectors are \[ \left[\! \begin{array}{r} 1 \\ -1 \end{array} \!\right] + i \left[\! \begin{array}{r} 0 \\ 1 \end{array} \!\right] \qquad \text{and} \qquad \left[\! \begin{array}{r} 1 \\ -1 \end{array} \!\right] - i \left[\! \begin{array}{r} 0 \\ 1 \end{array} \!\right] \] One of the identity for the matrix $\left[\! \begin{array}{rr} 1 & -3 \\ 6 & 7 \end{array} \!\right]$ that we established in the previous item is \[ \left[\! \begin{array}{rr} 1 & -3 \\ 6 & 7 \end{array} \!\right] \left[\! \begin{array}{rr} 1 & 0 \\ -1 & 1 \end{array} \!\right] = \left[\! \begin{array}{rr} 1 & 0 \\ -1 & 1 \end{array} \!\right] \left[\! \begin{array}{rr} 4 & -3 \\ 3 & 4 \end{array} \!\right]. \] Since $\sqrt{4^2+3^2} = 5$ we have \[ \left[\! \begin{array}{rr} 4 & -3 \\ 3 & 4 \end{array} \!\right] = 5 \left[\! \begin{array}{rr} \frac{4}{5} & -\frac{3}{5} \\ \frac{3}{5} & \frac{4}{5} \end{array} \!\right] = 5 \left[\! \begin{array}{rr} \cos\theta & -\sin \theta \\ \sin\theta & \cos\theta \end{array} \!\right], \quad \text{where} \quad \theta = \arccos \frac{4}{5} \approx 0.643501. \] Thus \[ \left[\! \begin{array}{rr} 1 & -3 \\ 6 & 7 \end{array} \!\right] = 5 \left[\! \begin{array}{rr} 1 & 0 \\ -1 & 1 \end{array} \!\right] \left[\! \begin{array}{rr} \frac{4}{5} & -\frac{3}{5} \\ \frac{3}{5} & \frac{4}{5} \end{array} \!\right] \left[\! \begin{array}{rr} 1 & 0 \\ 1 & 1 \end{array} \!\right] \]
- Here is another example of the above procedure. Consider the matrix \[ \left[\! \begin{array}{rr} -1 & 2 \\ -1 & 1 \end{array} \!\right]. \] For this matrix it is interesting to calculate its square \[ \left[\! \begin{array}{rr} -1 & 2 \\ -1 & 1 \end{array} \!\right] \left[\! \begin{array}{rr} -1 & 2 \\ -1 & 1 \end{array} \!\right] = \left[\! \begin{array}{rr} -1 & 0 \\ 0 & -1 \end{array} \!\right] \] and then \[ \left[\! \begin{array}{rr} -1 & 2 \\ -1 & 1 \end{array} \!\right]^4 = \left[\! \begin{array}{rr} -1 & 0 \\ 0 & -1 \end{array} \!\right] \left[\! \begin{array}{rr} -1 & 0 \\ 0 & -1 \end{array} \!\right] = \left[\! \begin{array}{rr} 1 & 0 \\ 0 & 1 \end{array} \!\right]. \] Explain why the fourth power of the given matrix is the identity matrix by using the method presented in this post.
- Today we did Appendix B Complex Numbers. I wrote my own introduction to complex numbers. In this introduction I offer an explanation for Euler's formula without using infinite series. Instead, I use differentiation rules.
- I will post about Matrix of a Linear Transformation here.
-
In this item I will illustrate how to calculate eigenvalues and the corresponding eigenspaces of a specific $3\!\times\!3$ matrix. Consider the matrix
\[
A = \left[\!
\begin{array}{rrr}
3 & 1 & -1 \\
1 & 3 & -1 \\
3 & 3 & -1
\end{array}
\!\right] .
\]
- First we find the characteristic polynomial of this matrix. The characteristic polynomial is the determinant of the following matrix: \[ A - \lambda I_3 = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] - \left[\! \begin{array}{rrr} \lambda & 0 & 0 \\ 0 & \lambda & 0 \\ 0 & 0 & \lambda \end{array} \!\right] = \left[\! \begin{array}{ccc} 3-\lambda & 1 & -1 \\ 1 & 3-\lambda & -1 \\ 3 & 3 & -1-\lambda \end{array} \!\right] \] Next we calculate this determinant: \begin{align*} \left|\! \begin{array}{ccc} 3-\lambda & 1 & -1 \\ 1 & 3-\lambda & -1 \\ 3 & 3 & -1-\lambda \end{array} \!\right| &= (3-\lambda) \bigl( (3-\lambda)(-1-\lambda) +3 \bigr) \\ & \phantom{XXXXX} - 1 \bigl( 1(-1-\lambda) +3 \bigr) \\ & \phantom{XXXXX} +(-1) \bigl( 3-3(3-\lambda) \bigr) \\ & = (3-\lambda) \bigl( \lambda^2 -2 \lambda \bigr) - (2-\lambda) -3 (\lambda - 2) \\ & = (\lambda - 2)\bigl( \lambda (3-\lambda) + 1 - 3 \bigr) \\ & = (\lambda - 2)\bigl( - \lambda^2 + 3\lambda -2 \bigr) \\ & = - (\lambda - 2)^2 (\lambda - 1 ) \\ & = -\lambda ^3 + 5 \lambda^2 - 8 \lambda + 4 \end{align*}
- Thus the eigenvalues of the matrix $A$ are $1$ and $2.$
- Next we will find the eigenspace corresponding to the eigenvalue $1.$ For that we need to find the nullspace of the matrix \[ A - 1 I_3 = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] - \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{ccc} 2 & 1 & -1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right]. \] So, we row reduce this matrix: \[ \left[\! \begin{array}{ccc} 2 & 1 & -1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] \sim \left[\! \begin{array}{ccc} 1 & 2 & -1 \\ 0 & 3 & -1 \\ 0 & 3 & -1 \end{array} \!\right] \sim \left[\! \begin{array}{ccc} 1 & 2 & -1 \\ 0 & 1 & -1/3 \\ 0 & 0 & 0 \end{array} \!\right] \sim \left[\! \begin{array}{ccc} 1 & 0 & -1/3 \\ 0 & 1 & -1/3 \\ 0 & 0 & 0 \end{array} \!\right]. \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} s/3 \\ s/3 \\ s \end{array} \!\right] \ : \ s \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] \right\}. \] Hence one eigenvector is $\left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right].$
- Next we will find the eigenspace corresponding to the eigenvalue $2.$ For that we need to find the nullspace of the matrix \[ A - 2 I_3 = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] - \left[\! \begin{array}{rrr} 2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & 1 & -1 \\ 1 & 1 & -1 \\ 3 & 3 & -3 \end{array} \!\right]. \] So, we row reduce this matrix: \[ \left[\! \begin{array}{rrr} 1 & 1 & -1 \\ 1 & 1 & -1 \\ 3 & 3 & -3 \end{array} \!\right] \sim \left[\! \begin{array}{rrr} 1 & 1 & -1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array} \!\right]. \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} -s + t \\ s \\ t \end{array} \!\right] \ : \ s, t \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{c} -1 \\ 1 \\ 0 \end{array} \!\right], \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] \right\}. \] Hence two linearly independent eigenvectors corresponding to the eigenvalue $2$ are $\left[\! \begin{array}{c} -1 \\ 1 \\ 0 \end{array} \!\right]$ and $\left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right].$
- The magic of what we found by now is that we found a basis of $\mathbb{R}^3$ which consists of eigenvectors of $A:$ \[ \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right], \quad \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \quad \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] \]
- Before continuing, verify whether these are really eigenvectors: \begin{align*} \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] & = 1 \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right], \\ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & = 2 \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \\ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right]\left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] & = 2 \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right]. \end{align*}
- Let $\lambda$ be an eigenvalue of $A$ and let $\mathbf{v}$ be a corresponding eigenvector. That is, \[ A\mathbf{v} = \lambda \mathbf{v}. \] Applying $A$ to both sides of the preceding equality and using linearity of matrix-vector multiplication we get \[ A^2 \mathbf{v} = A(\lambda \mathbf{v}) = \lambda A\mathbf{v} = \lambda^2 \mathbf{v}. \] We can repeat this process many, many times \[ A^{100} \mathbf{v} = \lambda^{100} \mathbf{v}. \]
- Let us now calculate $A^{100} \mathbf{x}$ for some specific vector $\mathbf{x},$ say the vector $\mathbf{x} = \left[\! \begin{array}{c} 2 \\ 3 \\ 4 \end{array} \!\right].$ First we write this vector as a linear combination of the above chosen basis of eigenvectors: \[ \left[\! \begin{array}{c} 2 \\ 3 \\ 4 \end{array} \!\right] = (-1) \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] + 4 \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] + 7 \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] \] Now apply the given $3\!\times\!3$ matrix to both sides of the above equation: \begin{align*} \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right]^{100} \left[\! \begin{array}{c} 2 \\ 3 \\ 4 \end{array} \!\right] & = (-1) 1^{100} \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] + 4 \cdot 2^{100} \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] + 7 \cdot 2^{100} \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] \\ & = -\left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] + 2^{100} \left[\! \begin{array}{r} 3 \\ 4 \\ 7 \end{array} \!\right] \end{align*}
- Since the given $3\!\times\!3$ matrix has three linearly independent eigenvectors it is diagonalizable. The following equality holds: \[ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right]. \] The matrix whose columns are the linearly independent eigenvectors is invertible: \[ \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right]. \] The following equality is called a diagonalization of a matrix: \[ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] . \]
-
In this item I will illustrate how to calculate eigenvalues and the corresponding eigenspaces of a specific $4\!\times\!4$ matrix. Consider the matrix
\[
A = \left[\!
\begin{array}{rrrr}
0 & 0 & -1 & -1 \\
-1 & 0 & 0 & 0 \\
2 & 1 & 2 & 1 \\
-2 & -1 & -1 & 0
\end{array}
\!\right] .
\]
- First we find the characteristic polynomial of this matrix. The characteristic polynomial is the determinant of the following matrix: \[ A - \lambda I_4 = \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] - \left[\! \begin{array}{rrrr} \lambda & 0 &0 & 0 \\ 0 & \lambda & 0 & 0 \\ 0 & 0 & \lambda & 0 \\ 0 & 0 & 0 & \lambda \end{array} \!\right] = \left[\! \begin{array}{cccc} -\lambda & 0 & -1 & -1 \\ -1 & -\lambda & 0 & 0 \\ 2 & 1 & 2-\lambda & 1 \\ -2 & -1 & -1 & -\lambda \end{array} \!\right] \] Next we calculate the determinant of the preceding matrix: \begin{align*} \left|\! \begin{array}{cccc} -\lambda & 0 & -1 & -1 \\ -1 & -\lambda & 0 & 0 \\ 2 & 1 & 2-\lambda & 1 \\ -2 & -1 & -1 & -\lambda \end{array} \!\right| & = -\lambda \left|\begin{array}{ccc} -\lambda & 0 & 0 \\ 1 & 2-\lambda & 1 \\ -1 & -1 & -\lambda \end{array} \right| - \left| \begin{array}{ccc} -1 & -\lambda & 0 \\ 2 & 1 & 1 \\ -2 & -1 & -\lambda \end{array} \right| + \left| \begin{array}{ccc} -1 & -\lambda & 0 \\ 2 & 1 & 2-\lambda \\ -2 & -1 & -1 \end{array} \right| \\ & = \lambda^2 ( \lambda^2 -2 \lambda + 1 ) - \bigl( \lambda -1 +2 \lambda - 2 \lambda^2 \bigr) + \bigl( \lambda - 1 + 2 \lambda - 2 \lambda^2 \bigr) \\ & = \lambda^2 ( \lambda^2 -2 \lambda + 1 ) \\ & = \lambda^2 ( \lambda - 1 )^2 \end{align*}
- Thus the eigenvalues of the matrix $A$ are $0$ and $1.$
- Next we will find the eigenspace corresponding to the eigenvalue $0.$ For that we need to find the nullspace of the matrix \[ A - 0 I_4 = \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] \]
- So, we row reduce the matrix $A:$ \[ \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] \sim \cdots \sim \left[\! \begin{array}{rrrr} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & -1 \\ 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 0 \end{array} \!\right] \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} 0 \\ s \\ -s \\ s \end{array} \!\right] \ : \ s \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{r} 0 \\ 1 \\ -1 \\ 1 \end{array} \!\right] \right\}. \]
- Next we will find the eigenspace corresponding to the eigenvalue $1.$ For that we need to find the nullspace of the matrix \[ A - 1 I_4 = \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] - \left[\! \begin{array}{rrrr} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{rrrr} -1 & 0 & -1 & -1 \\ -1 & -1 & 0 & 0 \\ 2 & 1 & 1 & 1 \\ -2 & -1 & -1 & -1 \end{array} \!\right] \]
- So, we row reduce the last matrix: \[ \left[\! \begin{array}{rrrr} -1 & 0 & -1 & -1 \\ -1 & -1 & 0 & 0 \\ 2 & 1 & 1 & 1 \\ -2 & -1 & -1 & -1 \end{array} \!\right] \sim \cdots \sim \left[\! \begin{array}{rrrr} 1 & 0 & 1 & 1 \\ 0 & 1 & -1 & -1 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{array} \!\right] \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} -s-t \\ s+t \\ s \\ t \end{array} \!\right] \ : \ s, t \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{r} -1 \\ 1 \\ 1 \\ 0 \end{array} \!\right], \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \\ 1 \end{array} \!\right] \right\}. \]
- The $4\!\times\!4$ matrix $A$ in this item has two eigenvalues. The corresponding eigenspaces have dimensions $1$ and $2$. Thus, we can have at most three linearly independent eigenvectors. Consequently, we can not have a basis for $\mathbb R^4$ which consists of eigenvectors of $A.$ Hence the matrix $A$ is not diagonalizable.
- Today we review Section 5.1, Section 5.2 and Section 5.3. Suggested problems for Section 5.1: 1, 3, 4, 5, 6, 8, 11, 15, 16, 17, 19, 20, 24-27, 29, 30, 31; for Section 5.2 are 1-8, 11, 12, 14, 15, (in all these problems you can find eigenvectors as well) 9, 13, 18, 19, 20, 21, 24, 25, 27; for Section 5.3 are 2, 3, 5, 8, 9, 12, 13, 16, 18, 20, 23, 24.
- A related Wikipedia link: Eigenvalue, eigenvector and eigenspace.
- Below are animations of different $2\!\times\!2$ matrices in action. In each scene the navy blue vector is the image of the sea green vector under the multiplication by a matrix $A$. For easier visualization of the action the heads of vectors leave traces.
- Just looking at the movies you can guess what are the eigenvalues and eigenvectors of the featured matrix. In particular it is easy to see whether an eigenvalue is positive, negative, zero, or complex, ... You can also approximately calculate which matrix is featured in each movie.
Place the cursor over the image to start the animation.
|
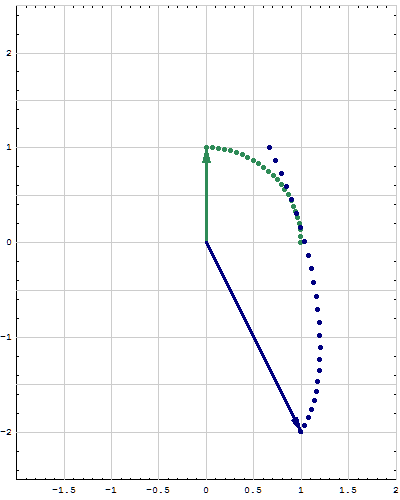
|
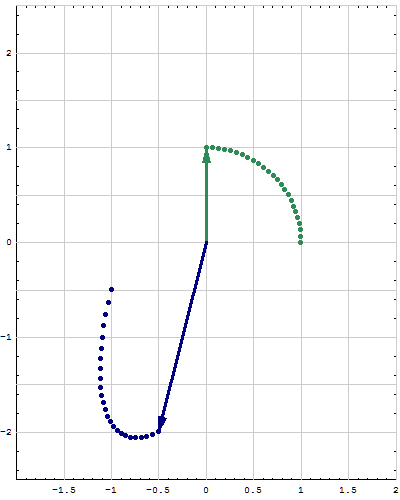
|
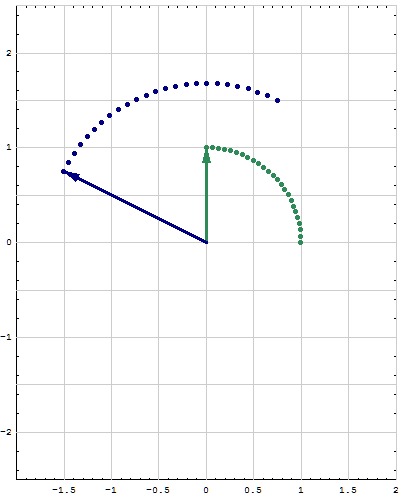
|
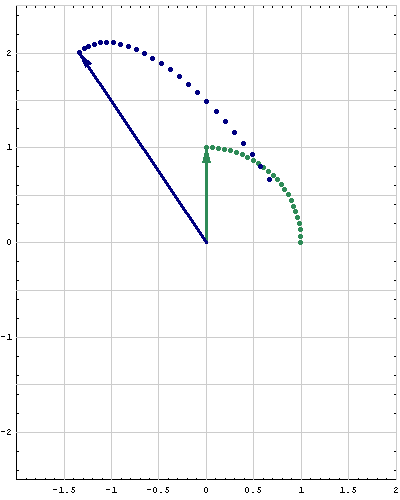
|
|
|
|
- Find the eigenvalues and the corresponding eigenspaces of the matrix \[ \left[ \begin{array}{cccc} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \right] \] Is this matrix diagonalizable?
- Assignment 0 is due on Monday, October 14.
- In this item I will illustrate the concept of a change-of-coordinates matrix on the example that we studied on Friday, October 4. Recall that we studied the following matrix \[ A = \left[\! \begin{array}{rrrrr} 1 & 3 & 2 & 2 & 2 \\ 2 & 0 & -2 & 1 & 1 \\ 2 & 1 & -1 & 1 & 2 \\ 1 & 4 & 3 & 2 & 3 \end{array} \!\right] \quad \sim \cdots \sim \quad \left[\! \begin{array}{rrrrr} 1 & 0 & -1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 1 \\ 0 & 0 & 0 & 1 & -1 \\ 0 & 0 & 0 & 0 & 0 \end{array} \!\right] . \] We established that \[ \mathcal{C} = \left\{ \left[\! \begin{array}{c} 1 \\ 2 \\ 2 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{c} 3 \\ 0 \\ 1 \\ 4 \end{array} \!\right] , \left[\! \begin{array}{c} 2 \\ 1 \\ 1 \\ 2 \end{array} \!\right] \right\} \] is a basis for the column space $\operatorname{Col} A.$ It is not difficult to establish that \[ \mathcal{D} = \left\{ \left[\! \begin{array}{c} 3 \\ 0 \\ 1 \\ 4 \end{array} \!\right] , \left[\! \begin{array}{r} 2 \\ -2 \\ -1 \\ 3 \end{array} \!\right] , \left[\! \begin{array}{c} 2 \\ 1 \\ 2 \\ 3 \end{array} \!\right] \right\} \] is another basis for $\operatorname{Col} A.$ Next we calculate \[ \underset{\mathcal{D}\leftarrow\mathcal{C}}{P} \qquad \text{and} \qquad \underset{\mathcal{C}\leftarrow\mathcal{D}}{\displaystyle P}. \] Since we already have coordinates of the columns of $A$ relative to the basis $\mathcal{C}$ we first calculate \[ \underset{\mathcal{C}\leftarrow\mathcal{D}}{\displaystyle P} = \left[ \left[ \left[\! \begin{array}{c} 3 \\ 0 \\ 1 \\ 4 \end{array} \!\right] \right]_{\mathcal{C}} \ \left[ \left[\! \begin{array}{r} 2 \\ -2 \\ -1 \\ 3 \end{array} \!\right] \right]_{\mathcal{C}} \ \left[ \left[\! \begin{array}{c} 2 \\ 1 \\ 2 \\ 3 \end{array} \!\right] \right]_{\mathcal{C}} \right] = \left[\! \begin{array}{rrr} 0 & -1 & 1 \\ 1 & 1 & 1 \\ 0 & 0 & -1 \end{array} \!\right] \] Now we just calculate the inverse of the last matrix \begin{align*} \left[\! \begin{array}{rrr|rrr} 0 & -1 & 1 & 1 & 0 & 0 \\ 1 & 1 & 1 & 0 & 1 & 0 \\ 0 & 0 & -1 & 0 & 0 & 1 \end{array} \!\right] & \sim \left[\! \begin{array}{rrr|rrr} 1 & 1 & 1 & 0 & 1 & 0 \\ 0 & 1 & -1 & -1 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & -1 \end{array} \!\right] \\ & \sim \left[\! \begin{array}{rrr|rrr} 1 & 1 & 0 & 0 & 1 & 1 \\ 0 & 1 & 0 & -1 & 0 & -1 \\ 0 & 0 & 1 & 0 & 0 & -1 \end{array} \!\right] \\ & \sim \left[\! \begin{array}{rrr|rrr} 1 & 0 & 0 & 1 & 1 & 2 \\ 0 & 1 & 0 & -1 & 0 & -1 \\ 0 & 0 & 1 & 0 & 0 & -1 \end{array} \!\right] \end{align*} Thus \[ \underset{\mathcal{D}\leftarrow\mathcal{C}}{P} = \left[\! \begin{array}{rrr} 1 & 1 & 2 \\ -1 & 0 & -1 \\ 0 & 0 & -1 \end{array} \!\right] . \] Let us verify the third column of the last matrix. It means that \[ \left[\! \begin{array}{c} 2 \\ 1 \\ 1 \\ 2 \end{array} \!\right] = 2 \left[\! \begin{array}{c} 3 \\ 0 \\ 1 \\ 4 \end{array} \!\right] +(-1) \left[\! \begin{array}{r} 2 \\ -2 \\ -1 \\ 3 \end{array} \!\right] +(-1) \left[\! \begin{array}{c} 2 \\ 1 \\ 2 \\ 3 \end{array} \!\right] . \]
- It is important to explore the concepts of a subspace and a basis in the context of an $m\!\times\!n$ matrix \[ A = \left[\! \begin{array}{cccc} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \\ \end{array} \!\right] . \] Notice that the matrix $A$ has $n$ columns which are vectors in $\mathbb{R}^m$: \[ \left[\! \begin{array}{c} a_{11} \\ a_{21} \\ \vdots \\ a_{m1} \end{array} \!\right] , \left[\! \begin{array}{c} a_{12} \\ a_{22} \\ \vdots \\ a_{m2} \end{array} \!\right] , \cdots, \left[\! \begin{array}{c} a_{1n} \\ a_{2n} \\ \vdots \\ a_{mn} \end{array} \!\right] \in \mathbb{R}^m; \] the the matrix $A$ has $m$ rows and the rows of $A$ are vectors in $\mathbb{R}^n$: \[ \left[\! \begin{array}{c} a_{11} \\ a_{12} \\ \vdots \\ a_{1n} \end{array} \!\right] , \left[\! \begin{array}{c} a_{21} \\ a_{22} \\ \vdots \\ a_{2n} \end{array} \!\right] , \cdots, \left[\! \begin{array}{c} a_{m1} \\ a_{m2} \\ \vdots \\ a_{mn} \end{array} \!\right] \in \mathbb{R}^n. \] Three fundamental subspaces associated with $A$ are \begin{align*} \operatorname{Col} A &= \operatorname{Span}\left\{ \left[\! \begin{array}{c} a_{11} \\ a_{21} \\ \vdots \\ a_{m1} \end{array} \!\right] , \left[\! \begin{array}{c} a_{12} \\ a_{22} \\ \vdots \\ a_{m2} \end{array} \!\right] , \cdots, \left[\! \begin{array}{c} a_{1n} \\ a_{2n} \\ \vdots \\ a_{mn} \end{array} \!\right] \right\} \subseteq \mathbb{R}^m, \\ \operatorname{Raw} A &= \operatorname{Span}\left\{ \left[\! \begin{array}{c} a_{11} \\ a_{12} \\ \vdots \\ a_{1n} \end{array} \!\right] , \left[\! \begin{array}{c} a_{21} \\ a_{22} \\ \vdots \\ a_{2n} \end{array} \!\right] , \cdots, \left[\! \begin{array}{c} a_{m1} \\ a_{m2} \\ \vdots \\ a_{mn} \end{array} \!\right] \right\} \subseteq \mathbb{R}^n, \\ \operatorname{Nul} A & = \bigl\{ \mathbf{x} \in \mathbb{R}^n \, : \, A \mathbf{x} = \mathbf{0} \, \bigr\} \subseteq \mathbb{R}^n . \end{align*}
- For a specific matrix, its reduced row echelon form (RREF) is the key to finding bases for the above subspaces, see Bases for $\operatorname{Nul} A$ and $\operatorname{Col} A$ on page 240.
-
Consider the matrix
\[
A = \left[\! \begin{array}{rrrrr}
1 & 3 & 2 & 2 & 2 \\
2 & 0 & -2 & 1 & 1 \\
2 & 1 & -1 & 1 & 2 \\
1 & 4 & 3 & 2 & 3
\end{array} \!\right] .
\]
- The reduced row echelon form (RREF) of this matrix \[ \left[\! \begin{array}{rrrrr} 1 & 0 & -1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 1 \\ 0 & 0 & 0 & 1 & -1 \\ 0 & 0 & 0 & 0 & 0 \end{array} \!\right] . \]
- From RREF we see that the first, the second and the fourth column of $A$ form a basis for $\operatorname{Col} A$. That is \[ \operatorname{Col} A = \operatorname{Span}\left\{ \left[\! \begin{array}{c} 1 \\ 2 \\ 2 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{c} 3 \\ 0 \\ 1 \\ 4 \end{array} \!\right] , \left[\! \begin{array}{c} 2 \\ 1 \\ 1 \\ 2 \end{array} \!\right] \right\} \subseteq \mathbb{R}^4. \] Denote the basis in the above formula for $\operatorname{Col} A$ by $\mathcal{C}.$
- Since the matrix $A$ and its RREF have the same row space and since the nonzero rows of the RREF of $A$ are linearly independent we see that \[ \operatorname{Raw} A = \operatorname{Span}\left\{ \left[\! \begin{array}{r} 1 \\ 0 \\ -1 \\ 0 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 1 \\ 1 \\ 0 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 0 \\ 0 \\ 1 \\ -1 \end{array} \!\right] \right\} \subseteq \mathbb{R}^5. \] Denote the basis in the above formula for $\operatorname{Row} A$ by $\mathcal{B}.$
- Finally, we use the RREF of $A$ to determine a basis for $\operatorname{Nul} A.$ The homogeneous system of linear equations that corresponds to the RREF of $A$ is equivalent to the matrix equation $A\mathbf{x} = \mathbf{0}.$ Next we solve that system: \begin{alignat*}{6} & x_1 \phantom{+} & \phantom{x_2} - & x_3 \phantom{+} & \phantom{x_4} + & x_5 & = & 0 \\ & & x_2 + & x_3 & + & x_5 & = & 0 \\ & & & & x_4 - & x_5 & = & 0 \\ \end{alignat*} In this system variables $x_3 = s$ and $x_5 = t$ are free and the variables are given as $x_1 = s-t$, $x_2 =-s-t$, $x_4 = t$. In vector form the solution is given by \[ \mathbf{x} = \left[\! \begin{array}{c} s-t \\ -s-t \\ s \\ t \\ t \end{array} \!\right] = s \left[\! \begin{array}{r} 1 \\ -1 \\ 1 \\ 0 \\ 0 \end{array} \!\right] + t \left[\! \begin{array}{r} -1 \\ -1 \\ 0 \\ 1 \\ 1 \end{array} \!\right]. \] Since $s$ and $t$ are arbitrary real numbsrs it follows that \[ \operatorname{Nul} A = \operatorname{Span}\left\{ \left[\! \begin{array}{r} 1 \\ -1 \\ 1 \\ 0 \\ 0 \end{array} \!\right] , \left[\! \begin{array}{r} -1 \\ -1 \\ 0 \\ 1 \\ 1\end{array} \!\right] \right\} \subseteq \mathbb{R}^5. \]
- Now that we have a basis $\mathcal{C}$ for the $\operatorname{Col} A$ we can calculate coordinates of all the columns of $A$ relative to this basis. The nature of the row reduction process is that any solution of the vector equation corresponding to the RREF of $A$ is a solution of the original vector equation. For example, we have \[ 1 \left[\! \begin{array}{c} 1 \\ 0 \\ 0 \\ 0 \end{array} \!\right] + (-1)\left[\! \begin{array}{c} 0 \\ 1 \\ 0 \\ 0 \end{array} \!\right] + 1\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \\ 0 \end{array} \!\right] + 0 \left[\! \begin{array}{c} 0 \\ 0 \\ 1 \\ 0 \end{array} \!\right] + 0 \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \\ 0 \end{array} \!\right] = \left[\! \begin{array}{c} 0 \\ 0 \\ 0 \\ 0 \end{array} \!\right]. \] Therefore, \[ 1 \left[\! \begin{array}{c} 1 \\ 2 \\ 2 \\ 1 \end{array} \!\right] + (-1) \left[\! \begin{array}{r} 3 \\ 0 \\ 1 \\ 4 \end{array} \!\right] + 1 \left[\! \begin{array}{r} 2 \\ -2 \\ -1 \\ 3 \end{array} \!\right] + 0 \left[\! \begin{array}{c} 2 \\ 1 \\ 1 \\ 2 \end{array} \!\right] + 0 \left[\! \begin{array}{r} 2 \\ 1 \\ 2 \\ 3 \end{array} \!\right] = \left[\! \begin{array}{c} 0 \\ 0 \\ 0 \\ 0 \end{array} \!\right]. \] From the last equality we obtain the coordinates of the third column in $A$ relative to the basis $\mathcal{C};$ similarly we obtain the coordinates of the fifth column of $A$ relative to the basis $\mathcal{C}:$ \[ \left[\left[\! \begin{array}{r} 2 \\ -2 \\ -1 \\ 3 \end{array} \!\right]\right]_{\mathcal{C}} = \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \qquad \left[\left[\! \begin{array}{r} 2 \\ 1 \\ 2 \\ 3 \end{array} \!\right]\right]_{\mathcal{C}} = \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \]
- In this item we determine the coordinates of the rows of $A$ relative to the basis $\mathcal{B}$ of the $\operatorname{Row} A.$ These coordinates are "easy" to calculate because of the special structure of $\mathcal{B}:$ \[ \left[\left[\! \begin{array}{r} 1 \\ 3 \\ 2 \\ 2 \\ 2 \end{array} \!\right]\right]_{\mathcal{B}} = \left[\! \begin{array}{r} 1 \\ 3 \\ 2 \end{array} \!\right], \quad \left[\left[\! \begin{array}{r} 2 \\ 0 \\ -2 \\ 1 \\ 1 \end{array} \!\right]\right]_{\mathcal{B}} = \left[\! \begin{array}{r} 2 \\ 0 \\ 1 \end{array} \!\right], \quad \left[\left[\! \begin{array}{r} 2 \\ 1 \\ -1 \\ 1 \\ 2 \end{array} \!\right]\right]_{\mathcal{B}} = \left[\! \begin{array}{r} 2 \\ 1 \\ 1 \end{array} \!\right], \quad \left[\left[\! \begin{array}{r} 1 \\ 4 \\ 3 \\ 2 \\ 3 \end{array} \!\right]\right]_{\mathcal{B}} = \left[\! \begin{array}{r} 1 \\ 4 \\ 2 \end{array} \!\right]. \]
- Please do the following calculation: \[ \left[\! \begin{array}{rrr} 1 & 3 & 2 \\ 2 & 0 & 1 \\ 2 & 1 & 1 \\ 1 & 4 & 2 \end{array} \!\right] \left[\! \begin{array}{rrrrr} 1 & 0 & -1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 1 \\ 0 & 0 & 0 & 1 & -1 \\ \end{array} \!\right] . \] Above we are multiplying the $4\!\times\!3$ matrix whose columns are the vectors in the basis $\mathcal{C}$ of the column space of $A$ by the $3\!\times\!5$ matrix whose rows are the vectors in the basis $\mathcal{B}$ of the row space of $A.$ What is the result and why? I find this result fascinating!
-
As you are working on Assignment 0 please pay attention to the concepts and propositions that you are using:
- Definition of a subspace on page 220
- Subsection A Subspace Spanned by a Set starting on page 221, the definition in the first paragraph. This definition in the set builder notation is: Let $m$ be a positive integer and let $\mathbf{v}_1,\ldots,\mathbf{v}_m$ be vectors in a vector space $\mathcal{V}$. The span of vectors $\mathbf{v}_1,\ldots,\mathbf{v}_m$ is defined as \[ \operatorname{Span}\{\mathbf{v}_1,\ldots,\mathbf{v}_m\} = \bigl\{ \alpha_1 \mathbf{v}_1 + \cdots + \alpha_m \mathbf{v}_m : \alpha_1,\ldots,\alpha_m \in \mathbb{R} \bigr\}. \] Theorem 1. $\operatorname{Span}\{\mathbf{v}_1,\ldots,\mathbf{v}_m\}$ is a subspace of $\mathcal{V}.$
- The definition of a linearly independent set on page 237. Next, I will restate this definition as an implication: An indexed set of vectors $\{\mathbf{v}_1,\ldots,\mathbf{v}_m\}$ in a vector space $\mathcal{V}$ is said to be linearly independent if the following implication holds \[ \alpha_1 \mathbf{v}_1 + \cdots + \alpha_m \mathbf{v}_m = \mathbf{0} \quad \text{implies} \quad \alpha_k = 0 \quad \text{for all} \quad k \in \{1,\ldots,m\}. \]
- The definition of a basis on page 238.
- The Unique Representation Theorem on page 246.
- Let $\mathcal{B} = \{\mathbf{b}_1,\ldots,\mathbf{b}_n\}$ be a basis of a vector space $\mathcal{V}.$ Please understand the concept of the coordinates of a vector in $\mathcal{V}$ relative to the basis $\mathcal{B}.$ This definition is on page 246. Also understand the concept of the coordinate mapping determined by the basis $\mathcal{B}.$ Briefly, for a vector $\mathbb{v}$ in $\mathcal{V}$ we have \[ [\mathbb{v}]_{\mathcal{B}} = \left[\!\!\begin{array}{c} \alpha_1 \\ \alpha_2 \\ \vdots \\ \alpha_n \end{array}\!\!\right] \quad \text{if and only if} \quad \mathbb{v} = \alpha_1 \mathbf{b}_1 + \alpha_2 \mathbf{b}_2 + \cdots + \alpha_n \mathbf{b}_n \] The coordinate mapping determined by the basis $\mathcal{B}$ is the linear mapping with domain $\mathcal{V}$ and with the range $\mathbb{R}^n$ and for an arbitrary vector $\mathbb{v}$ in $\mathcal{V}$ it is defined by \[ \mathcal{V} \ni \mathbb{v} \longmapsto [\mathbb{v}]_{\mathcal{B}} = \left[\!\!\begin{array}{c} \alpha_1 \\ \alpha_2 \\ \vdots \\ \alpha_n \end{array}\!\!\right] \in \mathbb{R}^n. \]
- Please understand the concepts of coordinates and of the coordinate mapping in the context of Problem 3 on Assignment 0. To remind you, in class we considered $\mathcal{S}_1$ and proved that $\mathcal{B} = \bigl\{ \mathbf{s}, \mathbf{c} \bigr\}$ is a basis for $\operatorname{Span}\bigl\{ \mathbf{s}, \mathbf{c} \bigr\}.$ Also, we proved that $\mathcal{S}_1 \subseteq \operatorname{Span}\bigl\{ \mathbf{s}, \mathbf{c} \bigr\}.$ What is \[ \bigl[a \sin(t+b) \bigr]_{\mathcal{B}}? \]
- I am posting some useful hints for Assignment 0 inspired by your questions.
- I am posting Assignment 0 that I did not manage to hand out in class today.
-
Here I recall the definition of a vector space as I stated it in class.
Definition. A nonempty set $\mathcal{V}$ is said to be a vector space over $\mathbb R$ if it satisfies the following 10 axioms.
Axiom 1. (AE) There exists a function $+: \mathcal{V}\!\times\!\mathcal{V} \to \mathcal{V}.$That is, for each pair $(u,v) \in \mathcal{V}\!\times\!\mathcal{V}$ there exists a unique $u+v \in \mathcal{V}$ which is called the sum of $u$ and $v.$Axiom 2. (AA) For every $u, v, w \in \mathcal{V}$ we have $u+(v+w) = (u+v)+w$Axiom 3. (AC) For every $u, v \in \mathcal{V}$ we have $u+v = v+u$Axiom 4. (AZ) There exists $0 \in \mathcal{V}$ such that for every $v \in \mathcal{V}$ we have $v+0 = v$Axiom 5. (AO) For every $v \in \mathcal{V}$ there exists $-v \in \mathcal{V}$ such that $v+(-v) = 0$Axiom 6. (SE) There exists a function $\cdot: \mathbb{R}\!\times\!\mathcal{V} \to \mathcal{V}.$That is, for each real number $\alpha \in \mathbb R$ and each $v \in \mathcal{V}$ there exists a unique $\alpha v \in \mathcal{V}$ which is called the scalar product of $\alpha$ and $v.$Axiom 7. (SA) For every $\alpha, \beta \in \mathbb R$ and every $v \in \mathcal{V}$ we have $\alpha (\beta v) = (\alpha\beta) v$Axiom 8. (SD) For every $\alpha, \beta \in \mathbb R$ and every $v \in \mathcal{V}$ we have $(\alpha +\beta) v = \alpha v + \beta v$Axiom 9. (SD) For every $\alpha \in \mathbb R$ and every $u, v \in \mathcal{V}$ we have $\alpha (u + v) = \alpha u + \alpha v$Axiom 10. (S0) For every $v \in \mathcal{V}$ we have $1 v = v$Explanation of the abbreviations: AE--addition exists, AA--addition is associative, AC--addition is commutative, AZ--addition has zero, AO--addition has opposites, SE-- scaling exists, SA--scaling is associative, SD--scaling distributes over addition of real numbers, SD--scaling distributes over addition of vectors, SO--scaling with one.
- The information sheet
-
We will start with a review. Please review
- The definition of an abstract vector space in Section 4.1, page 217.
- The definition a linearly independent set and the definition of a basis in Section 4.3; Examples 3, 4, 5, 6 and 10; Practice Problems 1, 2, 3, Exercises 1-8 and 38.
- Section 4.4: Theorem 7 (the unique representation theorem), the definition of coordinates with respect to a basis, the definition of a change-of-coordinates matrix on page 249 and the definition and the properties of a coordinate mapping; Examples 1, 2, 4, 5, 6; Practice Problems 1, 2; Exercises 3, 4, 5, 7, 9, 10, 11, 13, 18, 21, 32.
- Section 4.5: Theorem 10, the definition of a finite-dimensional vector space and its dimension and the Basis Theorem; Examples 1, 2, 3, 4; Practice Problems 1, 2; Exercises 2, 3, 7, 22, 24, and 34.
- Section 4.7 Change of Basis. Suggested exercises are 2, 3, 4, 6, 8, 9, 11, 12, 13, 14, 15, 16, 17, 19, 20.