- Read Section 7.4: Example 7. What is missing in Example 7 is the assumption that the matrix $A$ whose reduced singular value decomposition we calculate must be nonzero, $A\neq 0.$ The concept of a reduced singular value decomposition does not make sense for the zero matrix. Do exercises Chapter 7. Suplementary Exercises: 12, 13.
-
Example 1. The following $4\!\times\!5$ matrix is used as an example of Singular Value Decomposition on Wikipedia.
\[
M = \left[\!\begin{array}{rrrrr}
1 & 0 & 0 & 0 & 2 \\
0 & 0 & 3 & 0 & 0 \\
0 & 0 & 0 & 0 & 0 \\
0 & 2 & 0 & 0 & 0
\end{array}\right].
\]
Since this matrix has a lot of zero entries it should not be hard to find its SVD.
-
In this item I will state an important principle in finding an SVD by hand. Let $A$ be an $m\!\times\!n$ matrix and let
\[
A = U\Sigma V^\top
\]
be an SVD of $A.$ Notice that knowing an SVD of $A$ immediately have found a Singular Value Decomposition of $A^\top$:
\[
A^\top = V \Sigma^\top U^\top.
\]
When you write down the matrix $\Sigma^\top$ you see that the entries on the ``diagonal'' of this matrix are the same as the entries of $\Sigma$. Therefore the singular values of $A$ and $A^\top$ are the same. The only difference is that matrices $U$ and $V$ change positions. Conversely, if we know a Singular Value Decomposition of $A^\top$ we immediately know a Singular Value Decomposition of $A.$
The above observation is particularly important if the positive integer $n$ is "much" larger than the positive integer $m.$ To understand why, think of what is involved in finding an SVD of $A$: We need to find an orthogonal diagonalization of the $n\!\times\!n$ matrix $A^\top A.$ Contrast this with what is involved in finding an SVD of $A^\top$: We need to find an orthogonal diagonalization of the $m\!\times\!m$ matrix $(A^\top)^\top A^\top = AA^\top.$ Since we assume that $m$ is a smaller positive integer, it is easier to find orthogonal diagonalization of $A^\top.$ -
To find a Singular Value Decomposition of $M$ from Wikipedia, we are looking for a $4\!\times\!4$ orthogonal matrix $U$, the $4\!\times\!5$ matrix $\Sigma$ with the singular values of $M$ on the "diagonal", and a $5\!\times\!5$ orthogonal matrix $V$, such that $M = U\Sigma V^\top$.
As explained in the previous item, finding an SVD of $M^\top$ is easier. Thus, we proceed with finding \[ M^\top = V \Sigma^\top U^\top, \] with $U,$ $V$ and $\Sigma$ as above. - (I) To find the singular values and right singular vectors of $M^\top$ we calculate the matrix \[ M M^\top = \left[\!\begin{array}{rrrr} 5 & 0 & 0 & 0 \\ 0 & 9 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 4 \end{array}\right]. \] Clearly the eigenvalues of this matrix in nonincreasing order are $9,$ $5,$ $4$ and $0.$ Thus the singular values of $M$ and $M^\top$ are $3,$ $\sqrt{5},$ and $2.$ The ranks of both $M$ and $M^\top$ are $3.$ The dimension of the nulspace of $M$ is $2$ and the dimension of the nulspace of $M^\top$ is $1$. The matrix $\Sigma$, in fact for us now it is $\Sigma^\top,$ is \[ \Sigma^\top = \left[\!\begin{array}{cccc} 3 & 0 & 0 & 0 \\ 0 & \sqrt{5} & 0 & 0 \\ 0 & 0 & 2 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{array}\right] \] The corresponding orthogonal matrix $U$ is \[ U = \left[\!\begin{array}{rrrr} 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0\\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{array}\right] \]
- (II) To find a $5\!\times\!5$ orthogonal matrix $V$ we notice that the equality $M^\top = V \Sigma^\top U^\top$ implies \[ M^\top U = V \Sigma^\top. \] Thus, we calculate \[ M^\top U =\left[\!\begin{array}{rrrr} 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 2 \\ 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 2 & 0 & 0 & 0 \end{array}\right] \left[\!\begin{array}{rrrr} 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{array}\right] = \left[\!\begin{array}{rrrr} 0 & 1 & 0 & 0 \\ 0 & 0 & 2 & 0 \\ 3 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 \end{array}\right] = \left[\!\begin{array}{cccc} 0 & 1/\sqrt{5} & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 2/\sqrt{5} & 0 & 0 \end{array}\right] \left[\!\begin{array}{cccc} 3 & 0 & 0 & 0 \\ 0 & \sqrt{5} & 0 & 0 \\ 0 & 0 & 2 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{array}\right] \] Thus, the first three columns of $V$ are \[ \left[\!\begin{array}{ccc} 0 & 1/\sqrt{5} & 0 \\ 0 & 0 & 1 \\ 1 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 2/\sqrt{5} & 0 \end{array}\right]. \] Notice that to find these three columns we performed a minimal amount of calculation.
- (III) The next step is to find the remaining two columns of $V.$ Since the first three columns of $V$ form an orthonormal basis for $\operatorname{Row} M$, the remaining two columns of $V$ will be two orthonormal vectors in $\operatorname{Nul} M.$ To find these vectors row-reduce $M$: \[ M = \left[\!\begin{array}{rrrrr} 1 & 0 & 0 & 0 & 2 \\ 0 & 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 & 0 \end{array}\right] \quad \sim \quad \left[\!\begin{array}{rrrrr} 1 & 0 & 0 & 0 & 2 \\ 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ \end{array}\right]. \] Thus, the null-space of $M$ is spanned by the orthogonal vectors \[ \left[\!\begin{array}{r} -2 \\ 0 \\ 0 \\ 0 \\ 1 \end{array}\right] \qquad \text{and} \qquad \left[\!\begin{array}{r} 0 \\ 0 \\ 0 \\ 1 \\ 0 \end{array}\right]. \] Finally we have the complete $5\!\times\!5$ matrix $V$ \[ V = \left[\!\begin{array}{ccc} 0 & 1/\sqrt{5} & 0 & -2/\sqrt{5} & 0 \\ 0 & 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 \\ 0 & 2/\sqrt{5} & 0 & 1/\sqrt{5} & 0 \end{array}\right]. \]
-
In this item I will state an important principle in finding an SVD by hand. Let $A$ be an $m\!\times\!n$ matrix and let
\[
A = U\Sigma V^\top
\]
be an SVD of $A.$ Notice that knowing an SVD of $A$ immediately have found a Singular Value Decomposition of $A^\top$:
\[
A^\top = V \Sigma^\top U^\top.
\]
When you write down the matrix $\Sigma^\top$ you see that the entries on the ``diagonal'' of this matrix are the same as the entries of $\Sigma$. Therefore the singular values of $A$ and $A^\top$ are the same. The only difference is that matrices $U$ and $V$ change positions. Conversely, if we know a Singular Value Decomposition of $A^\top$ we immediately know a Singular Value Decomposition of $A.$
- To celebrate our work we verify \[ M = \left[\!\begin{array}{rrrrr} 1 & 0 & 0 & 0 & 2 \\ 0 & 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 & 0 \end{array}\right] = \left[\!\begin{array}{rrrr} 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0\\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{array}\right] \left[\!\begin{array}{ccccc} 3 & 0 & 0 & 0 & 0 \\ 0 & \sqrt{5} & 0 & 0 & 0 \\ 0 & 0 & 2 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \end{array}\right] \left[\!\begin{array}{ccc} 0 & 0 & 1 & 0 & 0 \\ 1/\sqrt{5} & 0 & 0 & 0 & 2/\sqrt{5} \\ 0 & 1 & 0 & 0 & 0 \\ -2/\sqrt{5} & 0 & 0 & 0 & 1/\sqrt{5} \\ 0 & 0 & 0 & 1 & 0 \end{array}\right] \] Or, equivalently, what is easier $MV = U\Sigma$: \[ \left[\!\begin{array}{rrrrr} 1 & 0 & 0 & 0 & 2 \\ 0 & 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 & 0 \end{array}\right] \left[\!\begin{array}{ccc} 0 & 1/\sqrt{5} & 0 & -2/\sqrt{5} & 0 \\ 0 & 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 \\ 0 & 2/\sqrt{5} & 0 & 1/\sqrt{5} & 0 \end{array}\right] = \left[\!\begin{array}{rrrr} 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0\\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{array}\right] \left[\!\begin{array}{ccccc} 3 & 0 & 0 & 0 & 0 \\ 0 & \sqrt{5} & 0 & 0 & 0 \\ 0 & 0 & 2 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \end{array}\right]. \]
-
Example 2. Here is a calculation of a singular value decomposition of the matrix
\[
A = \left[\!\begin{array}{rrr}
3 & -1 & 1 \\
-1 & 3 & 1 \\
1 & 1 & 1 \\
1 & 1 & 1 \end{array}\right].
\]
- (I) To find the singular values and right singular vectors we calculate the matrix \[ A^\top \!A = \left[\!\begin{array}{rrrr} 3 & -1 & 1 & 1 \\ -1 & 3 & 1 & 1 \\ 1 & 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] = \left[\!\begin{array}{rrr} 12 & -4 & 4 \\ -4 & 12 & 4 \\ 4 & 4 & 4 \end{array}\right] = 4 \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \end{array}\right]. \] Observe that adding the first two columns and subtracting twice the third column gives the zero vector. Hence $\lambda_3 = 0$ is an eigenvalue of $A^\top\!A$ and a corresponding eigenvector is $\bigl[ -1 \ -1 \ \ 2 \bigr]^\top$. Since each row of $A^\top\!A$ sums to $12$, $\lambda_2 = 12$ is an eigenvalue of $A^\top\!A$ and a corresponding eigenvector is $\bigl[ 1 \ \ 1 \ \ 1 \bigr]^\top$. Since the vector $\bigl[ 1 \ -1 \ \ 0 \bigr]^\top$ is orthogonal to both earlier found eigenvectors it also must be an eigenvector of $A^\top\!A$. The corresponding eigenvalue is $\lambda_1 = 16$. Thus the singular values of $A$ are $\sigma_1 = 4$ and $\sigma_2 = 2\sqrt{3}$, and the matrices $\Sigma$ and $V$ are as follows \[ \Sigma = \left[\!\begin{array}{rrr} 4 & 0 & 0 \\ 0 & 2\sqrt{3} & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array}\right] \qquad V = \left[\!\begin{array}{rrr} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{3}} & -\frac{1}{\sqrt{6}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{3}} & -\frac{1}{\sqrt{6}} \\ 0 & \frac{1}{\sqrt{3}} & \frac{2}{\sqrt{6}} \end{array}\right] = \bigl[ \mathbf{v}_1 \ \mathbf{v}_2 \ \mathbf{v}_3 \bigr]. \]
- (II) To find a $4\!\times\!4$ orthogonal matrix $U$ we first normalize vectors \[ A \left[\!\begin{array}{r} 1 \\ -1 \\ 0 \end{array}\right] = \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{r} 1 \\ -1 \\ 0 \end{array}\right] = \left[\!\begin{array}{r} 4 \\ -4 \\ 0 \\ 0 \end{array}\right] = 4 \left[\!\begin{array}{r} 1 \\ -1 \\ 0 \\ 0 \end{array}\right], \quad \text{hence} \quad \mathbf{u}_1 = \left[\!\begin{array}{r} \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} \\ 0 \\ 0 \end{array}\right], \] and \[ A \left[\!\begin{array}{r} 1 \\ 1 \\ 1 \end{array}\right] = \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{r} 1 \\ 1 \\ 1 \end{array}\right] = \left[\!\begin{array}{r} 3 \\ 3 \\ 3 \\ 3 \end{array}\right] = 3 \left[\!\begin{array}{r} 1 \\ 1 \\ 1 \\ 1 \end{array}\right], \quad \text{hence} \quad \mathbf{u}_2 = \left[\!\begin{array}{r} \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \end{array}\right]. \] From the general considerations about the singular value decomposition we know that the singular values and left and right singular vectors must satisfy: $A\mathbf{v}_1 = \sigma_1 \mathbf{u}_1$ and $A\mathbf{v}_2 = \sigma_2 \mathbf{u}_2$. Next we verify these equalities: \[ \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{r} \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} \\ 0 \end{array}\right] = 4 \left[\!\begin{array}{r} \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} \\ 0 \\ 0 \end{array}\right] \quad \text{and} \quad \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{r} \frac{1}{\sqrt{3}} \\ \frac{1}{\sqrt{3}} \\ \frac{1}{\sqrt{3}} \end{array}\right] = 2\sqrt{3} \left[\!\begin{array}{r} \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \end{array}\right] \] It has been established in class that $\mathbf{u}_1$ and $\mathbf{u}_2$ form an orthonormal basis for $\operatorname{Col}A$.
- (III) To complete the matrix $U$ we need an orthonormal basis for $\mathbb{R}^4$. Since the space $\operatorname{Nul}\bigl(A^\top\bigr)$ is the orthogonal complement of $\operatorname{Col}A$, we can simply find the nullspace of $A^\top$, and then find two orhonormal vectors in $\operatorname{Nul}\bigl(A^\top\bigr).$ Here we go: \[ \textstyle \left[\!\begin{array}{rrrr} 3 & -1 & 1 & 1 \\ -1 & 3 & 1 & 1 \\ 1 & 1 & 1 & 1 \end{array}\right] \sim \left[\!\begin{array}{rrrr} 1 & 1 & 1 & 1 \\ 0 & 4 & 2 & 2 \\ 0 & -4 & -2 & -2 \end{array}\right] \sim \left[\!\begin{array}{rrrr} 1 & 1 & 1 & 1 \\ 0 & 1 & 1/2 & 1/2 \\ 0 & 0 & 0 & 0 \end{array}\right] \sim \left[\!\begin{array}{rrrr} 1 & 0 & 1/2 & 1/2 \\ 0 & 1 & 1/2 & 1/2 \\ 0 & 0 & 0 & 0 \end{array}\right] \] Thus, \[ \operatorname{Nul}\bigl(A^\top\bigr) = \left\{ s \left[\!\begin{array}{r} -1 \\ -1 \\ 0 \\ 2 \end{array}\right] + t \left[\!\begin{array}{r} -1 \\ -1 \\ 2 \\ 0 \end{array}\right] \ : \ s, t \in \mathbb{R} \right\}. \] All the vectors in $\operatorname{Nul}\bigl(A^\top\bigr)$ are orthogonal to $\mathbf{u}_1$ and $\mathbf{u}_2$ (verify this). There are many pairs of orthonormal vectors in $\operatorname{Nul}\bigl(A^\top\bigr).$ One pair that cough my attention is obtained with $s=1/2$, $t=1/2$ and $s=1/2$, $t=-1/2$ and then normalized. That is the pair \[ \mathbf{u}_3 = \left[\!\begin{array}{r} -\frac{1}{2} \\ - \frac{1}{2} \\ \frac{1}{2} \\ \frac{1}{2} \end{array}\right] \quad \text{and} \quad \mathbf{u}_4 = \left[\!\begin{array}{c} 0 \\ 0 \\ -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} \end{array}\right] \] Finally, \[ U = \left[\!\begin{array}{rrrr} \frac{1}{\sqrt{2}} & \frac{1}{2} & -\frac{1}{2} & 0 \\ -\frac{1}{\sqrt{2}} & \frac{1}{2} & -\frac{1}{2} & 0 \\ 0 & \frac{1}{2} & \frac{1}{2} & -\frac{1}{\sqrt{2}} \\ 0 & \frac{1}{2} & \frac{1}{2} & \frac{1}{\sqrt{2}} \end{array}\right]. \]
- Remark To find vectors $\mathbf{u}_3$ and $ \mathbf{u}_4$ it might be slightly more efficient to proceed in the following way. Since we know that $\mathbf{u}_1$ and $ \mathbf{u}_2$ form a basis for $\operatorname{Col} A$ we can find a basis for $(\operatorname{Col} A)^{\perp}$ by solving the system \[ \left[\!\begin{array}{rrrr} 1 & -1 & 0 & 0 \\ 1 & 1 & 1 & 1 \end{array}\right] \left[\!\begin{array}{c} x_1 \\ x_2 \\ x_3 \\ x_4 \end{array}\right] = \left[\!\begin{array}{c} 0 \\ 0 \end{array}\right] \] The row reduction of the matrix \[ \left[\!\begin{array}{rrrr} 1 & -1 & 0 & 0 \\ 1 & 1 & 1 & 1 \end{array}\right] \sim \cdots \sim \left[\!\begin{array}{rrrr} 1 & 0 & 1/2 & 1/2 \\ 0 & 1 & 1/2 & 1/2 \end{array}\right] \] might be simpler than the row reduction that we did in (III).
- To celebrate our work we verify \[ \left[\!\begin{array}{rrr} 3 & -1 & 1 \\ -1 & 3 & 1 \\ 1 & 1 & 1 \\ 1 & 1 & 1 \end{array}\right] = \left[\!\begin{array}{rrrr} \frac{1}{\sqrt{2}} & \frac{1}{2} & -\frac{1}{2} & 0 \\ -\frac{1}{\sqrt{2}} & \frac{1}{2} & -\frac{1}{2} & 0 \\ 0 & \frac{1}{2} & \frac{1}{2} & -\frac{1}{\sqrt{2}} \\ 0 & \frac{1}{2} & \frac{1}{2} & \frac{1}{\sqrt{2}} \end{array}\right] \left[\!\begin{array}{rrr} 4 & 0 & 0 \\ 0 & 2\sqrt{3} & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array}\right] \left[\!\begin{array}{rrr} \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} & 0 \\ \frac{1}{\sqrt{3}} & \frac{1}{\sqrt{3}} & \frac{1}{\sqrt{3}} \\ -\frac{1}{\sqrt{6}} & -\frac{1}{\sqrt{6}} & \frac{2}{\sqrt{6}} \end{array}\right] . \]
- Suggested problems for Section 7.4: 3, 7, 11, 13, 14, 15, 17, 21
- I want to summarize the discussion of the quadratic forms that we had during the last week.
-
First. It is important to establish trichotomy for nonzero qudratic forms. Let $n\in\mathbb{N}.$ Let $Q : \mathbb{R}^n \to \mathbb{R}$ be a nonzero quadratic form.
A quadratic form $Q$ is said to be a nonzero quadratic form if there exists $\mathbf{x} \in \mathbb{R}^n$ such that $Q(\mathbf{x}) \neq 0.$
We distinguish the following three exclusive types of nonzero quadratic forms:- $Q$ is said to be a positive semidefinite quadratic form if $Q(\mathbf x) \geq 0$ for all $\mathbf x \in \mathbb R^n.$
- $Q$ is said to be a negative semidefinite quadratic form if $Q(\mathbf x) \leq 0$ for all $\mathbf x \in \mathbb R^n.$
- $Q$ is said to be an indefinite quadratic form if there exists $\mathbf{x} \in \mathbb R^n$ such that $Q(\mathbf{x}) \gt 0$ and there exists $\mathbf{y} \in \mathbb R^n$ such that $Q(\mathbf{y}) \lt 0.$
- $Q$ is said to be a positive definite quadratic form if $Q(\mathbf x) \gt 0$ for all $\mathbf x \in \mathbb R^n\!\setminus\!\{\mathbf 0\}.$
- $Q$ is said to be a negative definite quadratic form if $Q(\mathbf x) \lt 0$ for all $\mathbf x \in \mathbb R^n\!\setminus\!\{\mathbf 0\}.$
- A function $Q : \mathbb{R}^n \to \mathbb{R}$ is a quadratic form on $\mathbb{R}^n$ if and only if there exists a symmetric $n\!\times\!n$ matrix $A$ such that for all $\mathbf{x} \in \mathbb{R}^n$ we have $Q(\mathbf{x}) = \mathbf{x}^\top A\mathbf{x}.$ I like to think of this statement as a characterization, the definition being what I gave earlier. But the difference is minor.
-
Second. Let $Q:\mathbb{R}^n\to\mathbb{R}$ be a nonzero quadratic form such that for all $\mathbf{x} \in \mathbb{R}^n$ we have $Q(\mathbf{x}) = \mathbf{x}^\top A\mathbf{x}$ with a symmetric $n\!\times\!n$ matrix $A.$ We need to characterize the above trichotomy in terms of the eigenvalues of the matrix $A.$ Let $\lambda_1, \ldots, \lambda_n$ be eigenvalues of $A$ such that
\[
\lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_{n-1} \geq \lambda_{n}.
\]
Notice that $Q$ is a nonzero quadratic form if and only if there exists $k\in\{1,\ldots,n\}$ such that $\lambda_k \neq 0.$
Since $Q:\mathbb{R}^n\to\mathbb{R}$ is a nonzero quadratic form we have the following trichotomy
\[
\lambda_n \geq 0 \quad \text{or} \quad \lambda_1 \leq 0 \quad \text{or} \quad \lambda_1 \gt 0 \gt \lambda_n.
\]
The preceding displayed statement is true if and only if exactly one of the three statement is true. (That is the meaning of the noun trichotomy.)
-
The quadratic form $Q$ is positive semidefinite if and only if $\lambda_n \geq 0,$ that is, if and only if all the eigenvalues of $A$ are nonnegative.
- The quadratic form $Q$ is positive definite if and only if $\lambda_n \gt 0,$ that is, if and only if all the eigenvalues of $A$ are positive.
-
The quadratic form $Q$ negative semidefinite if and only if $\lambda_1 \leq 0,$ that is, if and only if all the eigenvalues of $A$ are nonpositive.
- The quadratic form $Q$ is negative definite if and only if $\lambda_1 \lt 0,$ that is, if and only if all the eigenvalues of $A$ are negative.
-
The quadratic form $Q$ is indefinite if and only if $\lambda_1 \gt 0 \gt \lambda_n.$
- The quadratic form $Q$ is indefinite nondegenerate if and only if $\lambda_1 \gt 0 \gt \lambda_n$ and $0$ is not eigenvalue of $A$. In general, any quadratic form for which $0$ is an eigenvalue of $A$ is called degenerate. (The zero form being the ultimate degenerate form.)
-
The quadratic form $Q$ is positive semidefinite if and only if $\lambda_n \geq 0,$ that is, if and only if all the eigenvalues of $A$ are nonnegative.
-
Third. We need to understand the graphs of quadratic forms $Q:\mathbb{R}^n\to\mathbb{R}.$ What is the graph of $Q$? The graph of $Q$ is the subset of $\mathbb{R}^{n+1}$ defined by
\[
\operatorname{Graph}(Q) = \Bigl\{ \bigl(x_1,\ldots,x_n, Q(\mathbf{x})\bigr) \in \mathbb{R}^{n+1} \ : \ \mathbf{x} = (x_1,\ldots,x_n) \in \mathbb{R}^n \Bigr\}.
\]
At this point we have the language to describe the set $\operatorname{Graph}(Q)$ only for $n=2.$ If $n=2$, then $\operatorname{Graph}(Q)$ is a surface in $\mathbb{R}^3.$ We learned the terminology to describe such surface in Math 224 Multivariable Calculus. However, plotting $\operatorname{Graph}(Q)$ in this case is more a matter of art, then math. However, computers are really good at plotting such surfaces, but in this class we decided not to push that aspect of the subject.
An easier task than drawing the surface $\operatorname{Graph}(Q)$ is drawing the level curves of this surface. The level curves of $\operatorname{Graph}(Q)$ are the subsets of $\mathbb{R}^2$ such that \[ \bigl\{ (x_1,x_2) \in \mathbb{R}^{2} \ : \ Q(x_1,x_2) = c \bigr\} \quad \text{where} \quad c \in \mathbb{R}. \] To simplify things I have decided that the only important level curves (also called the contour curves) are those for $c\in\{-1,0,1\}.$ Thus,- When studying a quadratic form $Q:\mathbb{R}^2\to\mathbb{R}$ in two variables we want to describe and plot the following three sets \[ \bigl\{ (x_1,x_2) \in \mathbb{R}^{2} \ : \ Q(x_1,x_2) = c \bigr\} \quad \text{where} \quad c \in \{-1,0,1\}. \] The possible options for these sets are empty set, singleton (the only element being the origin), a pair of lines, an ellipse or a hyperbola. (I hope I got all possibilities.) When describing the lines we can give the formulas. When describing ellipses or hyperbolas we can give the equations of the axis and the vertices.
- When studying a quadratic form $Q:\mathbb{R}^3 \to\mathbb{R}$ in three variables we want to describe and plot the following three sets \[ \bigl\{ (x_1,x_2,x_3) \in \mathbb{R}^{3} \ : \ Q(x_1,x_2,x_3) = c \bigr\} \quad \text{where} \quad c \in \{-1,0,1\}. \] The possible options for these sets are empty set, singleton (the only element being the origin), a plane or a pair of planes, a cone, an ellipsoid, a two sheet hyperboloid or an one sheet hyperboloid. (I hope I got all possibilities.)
- The analogous sets can be studied for $Q:\mathbb{R}^n \to\mathbb{R}$ with $n\gt 3,$ but we do not have a way to visualise and those sets and these tasks become harder.
- Fourth. For a quadratic form $Q:\mathbb{R}^n \to\mathbb{R}$ we want to calculate the minimum and the maximum that $Q$ takes on the unit sphere in $\mathbb{R}^n.$ That is we want to study the set \[ S = \Bigl\{ Q(\mathbf{x}) \ : \ \mathbf{x} \in \mathbb{R}^n \ \text{and} \ \| \mathbf{x} \| = 1 \Bigr\} \subset \mathbb{R} \] and calculate \[ \min S \quad \text{and} \quad \max S. \] The understanding of the maximum and the minimum would not be complete without understanding the following subsets of the unit sphere in $\mathbb{R}^n$ \begin{align*} \mathcal{M}_\min &= \Bigl\{ \mathbf{x} \in \mathbb{R}^n \ : \ \|\mathbf{x}\| = 1 \ \text{and} \ Q(\mathbf{x}) = \min S \Bigr\},\\ \mathcal{M}_\max &= \Bigl\{ \mathbf{x} \in \mathbb{R}^n \ : \ \|\mathbf{x}\| = 1 \ \text{and} \ Q(\mathbf{x}) = \max S \Bigr\}. \end{align*} The options for the sets $\mathcal{M}_\min$ and $\mathcal{M}_\max$ if $n=2$ are pairs of points on the unit circle in $\mathbb{R}^2$ which must be on the orthogonal lines. The options for the sets $\mathcal{M}_\min$ and $\mathcal{M}_\max$ if $n=3$ are pairs of points or a large circle on the unit sphere in $\mathbb{R}^3.$
- Fifth. This is the extension of the preceding item. I will formulate it in terms of matrices rather than quadratic forms. Let $n\in \mathbb{N}.$ Let $A$ and $B$ be symmetric $n\!\times\!n$ matrices and assume that all eigenvalues of $B$ are positive. That is the quadratic form \[ \mathbf{x} \mapsto \mathbf{x}^\top\!\!B \mathbf{x} \quad \text{with} \quad \mathbf{x}\in\mathbb{R}^n \] is positive definite. We want to study the set \[ S = \Bigl\{ \mathbf{x}^\top A \mathbf{x} \ : \ \mathbf{x} \in \mathbb{R}^n \ \text{and} \ \mathbf{x}^\top\!\!B \mathbf{x} = 1 \Bigr\} \subset \mathbb{R} \] and calculate \[ \min S \quad \text{and} \quad \max S. \] The understanding of the maximum and the minimum would not be complete without understanding the following subsets of the unit sphere in $\mathbb{R}^n$ \begin{align*} \mathcal{M}_\min &= \Bigl\{ \mathbf{x} \in \mathbb{R}^n \ : \ \mathbf{x}^\top\!\!B \mathbf{x} = 1 \ \text{and} \ \mathbf{x}^\top A \mathbf{x} = \min S \Bigr\},\\ \mathcal{M}_\max &= \Bigl\{ \mathbf{x} \in \mathbb{R}^n \ : \ \mathbf{x}^\top\!\!B \mathbf{x} = 1 \ \text{and} \ \mathbf{x}^\top A \mathbf{x} = \max S \Bigr\}, \end{align*} The options for the sets $\mathcal{M}_\min$ and $\mathcal{M}_\max$ if $n=2$ are pairs of points on an ellipse in $\mathbb{R}^2$ which must be on the orthogonal lines. The options for the sets $\mathcal{M}_\min$ and $\mathcal{M}_\max$ if $n=3$ are pairs of points on an ellipsoid or an ellipse on the same ellipsoid in $\mathbb{R}^3.$
- Suggested problems for Section 7.3: 1, 3, 5, 9, 11, 12
-
In Section 7.2 in the book the author does not discus quadratic forms with three variables. Here are some animations that might help you understand the quadratic form $x_1^2 + x_2^2 - x_3^2$. Here I show the surfaces in ${\mathbb R}^3$ with equations $x_1^2 + x_2^2 - x_3^2 = c$ for different values of $c$. These surfaces are called hyperboloids. You can read more at the Wikipedia
Hyperboloid page. One sheet hyperboloids are often encountered in art, see these Wikipedia pages Hyperboloid structure and list of hyperboloid structures, do not miss the Gallery at the bottom of the last page.
Place the cursor over the image to start the animation.
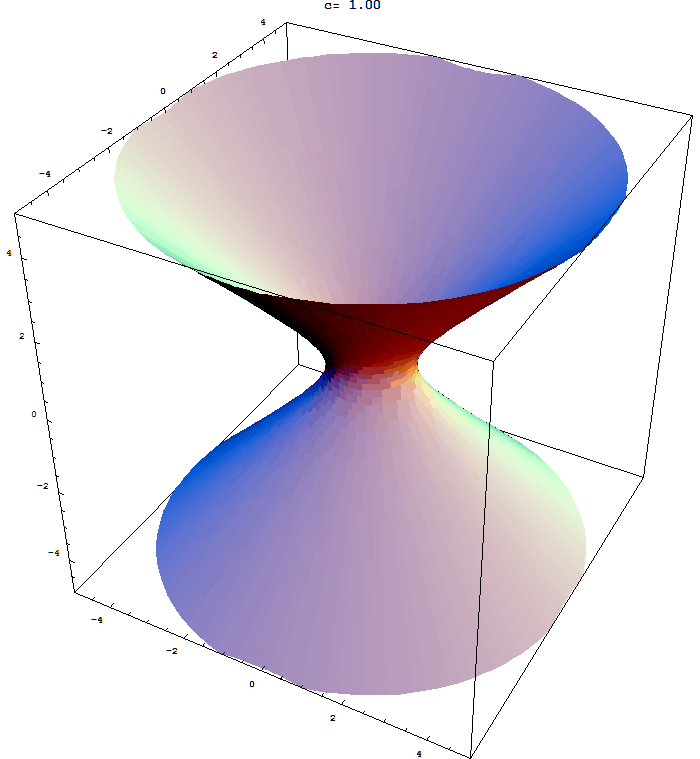
Five of the above level surfaces.
- During the class on Tuesday I used the Mathematica version 12 file Classification of Quadratic Surfaces. The file is called Classification_QF.nb. Right-click on the underlined link; in the pop-up menu that appears, your browser will offer you to save the file in your directory. Make sure that you save it with the exactly same name. After saving the file you can open it with Mathematica 12. Here is the pdf printout of the Mathematica file.
- Suggested problems for Section 7.2: 1, 3, 5, 7, 9, 13, 17, 19, 20, 21, 23, 25
- In Sections 7.2 and 7.3 we study quadratic forms.
-
A quadratic form in $n$ variables is a special kind of function $Q:\mathbb{R}^n \to \mathbb{R}.$ Below are few examples of quadratic forms
- Below are three specific quadratic forms in two variables: \[ Q(x_1,x_2) = 6 x_1^2 - 4 x_1 x_2 + 3 x_2^2, \qquad (x_1,x_2) \in \mathbb{R}^2 \] \[ Q(x_1,x_2) = x_1^2 + 6 x_1 x_2 + x_2^2, \qquad (x_1,x_2) \in \mathbb{R}^2 \] \[ Q(x_1,x_2) = 4 x_1^2 + 4 x_1 x_2 + x_2^2, \qquad (x_1,x_2) \in \mathbb{R}^2 \] In general, a quadratic form $Q$ in two variables $x_1,x_2$ is a function defined on $\mathbb{R}^2$ with the values in $\mathbb{R}$ which can be expressed as \[ Q(x_1,x_2) = a\, x_1x_1 + b\, x_1x_2 + c\, x_2x_2, \qquad (x_1,x_2) \in \mathbb{R}^2, \] where $a, b, c$ are real coefficients.
- Below are three specific quadratic forms in three variables: \[ Q(x_1,x_2,x_3) = x_1^2 -4x_1 x_2 +4 x_2 x_3 - x_3^2, \qquad (x_1,x_2,x_3) \in \mathbb{R}^3, \] \[ Q(x_1,x_2,x_3) = 4x_1 x_2 + 2 x_1 x_3 + 3 x_2^2 + 4 x_2 x_3, \qquad (x_1,x_2,x_3) \in \mathbb{R}^3, \] \[ Q(x_1,x_2,x_3) = 2 x_1^2 + 2 x_1 x_2 + 2 x_1 x_3 + 2 x_2^2 + 2 x_2 x_3 + 2 x_3^2, \qquad (x_1,x_2,x_3) \in \mathbb{R}^3, \] In general, a quadratic form $Q$ in three variables $x_1,x_2,x_3$ is a function defined on $\mathbb{R}^3$ with the values in $\mathbb{R}$ which can be expressed as \[ Q(x_1,x_2,x_3) = a\, x_1x_1 + b\, x_1x_2 + c\, x_1x_3 + d\, x_2 x_2 + e\, x_2 x_3 + f\, x_3 x_3, \quad (x_1,x_2,x_3) \in \mathbb{R}^3, \] where $a, b, c, d, e, f$ are real coefficients.
- A quadratic form $Q$ in four variables $x_1,x_2,x_3,x_4$ is a function defined on $\mathbb{R}^4$ with the values in $\mathbb{R}$ which is a linear combination of the following ten terms \[ x_1x_1, \quad x_1x_2, \quad x_1x_3, \quad x_1 x_4, \quad x_2 x_2, \quad x_2 x_3, \quad x_2x_4, \quad x_3 x_3, \quad x_3 x_4, \quad x_4 x_4. \] In other words, a quadratic form in four variables is a polynomial in four variables which contains only terms of degree $2.$
- In general, a quadratic form in $n$ variables is a polynomial in $n$ variables which contains only terms of degree $2.$ To be more specific, for $j, k \in \{1,\ldots,n\}$ with $j \leq k$ let us define the functions $q_{jk}:\mathbb{R}^n \to \mathbb{R}$ by \[ q_{jk}(\mathbf{x}) = x_j x_k, \qquad \mathbf{x} = (x_1,\ldots,x_n) \in \mathbb{R}^n. \] Notice that there are $\binom{n+1}{2} = \frac{n(n+1)}{2}$ such functions. A linear combination of the functions $q_{jk}(\mathbf{x})$ with $j, k \in \{1,\ldots,n\}$ with $j \leq k$, is called a quadratic form in $n$ variables.
- For us, the most important fact about quadratic forms is that for each quadratic form $Q$ in $n$ variables there exists a unique symmetric $n\!\times\!n$ matrix $A$ such that \[ Q(\mathbf{x}) = (A\mathbf{x})\cdot \mathbf{x} = \mathbf{x}^\top A\mathbf{x} \quad \text{for all} \quad \mathbf{x} \in \mathbb{R}^n. \] Such matrix $A$ is called the matrix of a quadratic form.
- In the above example, for all $(x_1,x_2) \in \mathbb{R}^2$ we have \[ Q(x_1,x_2) = a\, x_1x_1 + b\, x_1x_2 + c\, x_2x_2 = \left(\left[\! \begin{array}{cc} a & b/2 \\ b/2 & c \end{array} \!\right] \left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right] \right) \cdot \left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right] \] And for all $(x_1,x_2,x_3) \in \mathbb{R}^3$ we have \[ Q(x_1,x_2,x_3) = a\, x_1x_1 + b\, x_1x_2 + c\, x_1x_3 + d\, x_2 x_2 + e\, x_2 x_3 + f\, x_3 x_3 = \left(\left[\! \begin{array}{ccc} a & b/2 & c/2 \\ b/2 & d & e/2 \\ c/2 & e/2 & f \end{array} \!\right] \left[\! \begin{array}{c} x_1 \\ x_2 \\ x_3 \end{array} \!\right] \right) \cdot \left[\! \begin{array}{c} x_1 \\ x_2 \\ x_3 \end{array} \!\right] \]
-
In this item I will write about polychotomies in mathematics. A polychotomy is a partition of a given set of mathematical objects into disjoint classes which are all given distinct names.
-
A dichotomy is a partition of a given set of mathematical objects into two disjoint classes each of which is given a name. The following are examples of dichotomies.
- The most important dichotomy for numbers is the partition of numbers into the singleton set $\{0\}$ consisting of only zero and the set of all nonzero numbers. Further, dichotomy for the nonzero real numbers is the partition of the nonzero real numbers into positive real numbers and negative real numbers.
- An important dichotomy for the set of real numbers is the partition into rational and irrational numbers.
- A useful dichotomy for complex numbers is the partition of the complex numbers into the real and nonreal numbers. A complex number $z$ is said to be nonreal if the imaginary part of $z$ is nonzero.
- Consider the set of all square matrices. A square matrix $M$ is said to be singular if $\det M = 0.$ A square matrix $M$ is said to be nonsingular if $\det M \neq 0.$ You also learned that a square matrix is invertible if and only if it is nonsingular. Thus, singular-invertible is a dichotomy for square matrices.
-
A trichotomy is a partition of a given set of mathematical objects into three disjoint classes each of which is given a name. The following are examples of trichotomies.
- The most important trichotomy for the set of real numbers is the partition of numbers into singleton set $\{0\}$ consisting of only zero, the set of positive real numbers and the set of negative real numbers. As we mention before this trichotomy arrises as two dichotomies.
- In high school you learned about the trichotomy involving quadratic equations $a x^2 + b x + c = 0$ with $a\neq 0.$ Such equation can have: no solutions, exactly one solution, and exactly two solutions.
-
A quadruplicity is a partition of a given set of mathematical objects into four disjoint classes each of which is given a name. I started writing about polychotomies because of the following quadruplicity which arises with quadratic forms.
-
Let $Q : \mathbb R^n \to \mathbb R$ be a quadratic form. We distinguish the following four types of quadratic forms:
- $Q$ is said to be a zero quadratic form if $Q(\mathbf x) = 0$ for all $\mathbf x \in \mathbb R^n.$
- $Q$ is said to be a positive semidefinite quadratic form if $Q(\mathbf x) \geq 0$ for all $\mathbf x \in \mathbb R^n$ and there exists $\mathbf v \in \mathbb R^n$ such that $Q(\mathbf v) \gt 0.$
- $Q$ is said to be a negative semidefinite quadratic form if $Q(\mathbf x) \leq 0$ for all $\mathbf x \in \mathbb R^n$ and there exists $\mathbf v \in \mathbb R^n$ such that $Q(\mathbf v) \lt 0.$
- $Q$ is said to be an indefinite quadratic form if there exists $\mathbf v \in \mathbb R^n$ such that $Q(\mathbf v) \gt 0$ and there exists $\mathbf u \in \mathbb R^n$ such that $Q(\mathbf u) \lt 0.$
- $Q$ is said to be a positive definite quadratic form if $Q(\mathbf x) \gt 0$ for all $\mathbf x \in \mathbb R^n\!\setminus\!\{\mathbf 0\}.$
- $Q$ is said to be a negative definite quadratic form if $Q(\mathbf x) \lt 0$ for all $\mathbf x \in \mathbb R^n\!\setminus\!\{\mathbf 0\}.$
In the image below I give a graphical representation of the above quadruplicity. The red dot represents the zero quadratic form, the green region represents the positive semidefinite quadratic forms, the blue region represents the negative semidefinite quadratic forms and the cyan region represents the indefinite quadratic forms.
In the image above, the dark green region represents the positive definite quadratic forms and the dark blue region represents the negative definite quadratic forms. These two regions are not parts of the above quadruplicity.
-
Let $Q : \mathbb R^n \to \mathbb R$ be a quadratic form. We distinguish the following four types of quadratic forms:
-
A dichotomy is a partition of a given set of mathematical objects into two disjoint classes each of which is given a name. The following are examples of dichotomies.
- We finished Section 7.1 today. Suggested problems are 3, 4, 9, 11, 15, 19, 23, 24, 25, 27, 30, 33, 35.
-
Let us find a spectral decomposition of the matrix
\[
A = \left[\!
\begin{array}{ccc}
3 & 4 & 2 \\
4 & 3 & 2 \\
2 & 2 & 0
\end{array}
\!\right].
\]
- The characteristic polynomial of this matrix is \[ \left| \begin{array}{ccc} 3 - \lambda & 4 & 2 \\ 4 & 3 - \lambda & 2 \\ 2 & 2 & -\lambda \end{array} \right| = -\lambda^3 + 6 \lambda^2 + 15 \lambda + 8. \] The product of roots of must be $8$. Thus, if the roots of this polynomial are integers, then they must be one of these triples $(1,1,8),$ $(1,2,4),$ $(2,2,2),$ and variations of these triples with the two negative integers: $(-1,-1,8),$ $(-1,1,-8),$ $(-1,-2,4),$ $(-1,2,-4),$ $(1,-2,-4),$ $(-2,-2,2).$ Since neither $2$, $-2$ nor $1$ is a root, the only remaining option is $(-1,-1,8).$
- Next we find the corresponding eigenspaces: \begin{align*} \operatorname{Nul}(A-(-1)I_3) & = \operatorname{Span} \left\{ \left[ \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \right], \left[ \begin{array}{r} -1 \\ 0 \\ 2 \end{array} \right] \right\}, \\ \operatorname{Nul}(A-8I_3) & = \operatorname{Span} \left\{ \left[ \begin{array}{r} 2 \\ 2 \\ 1 \end{array} \right] \right\} \end{align*}
- To find an orthogonal diagonalization of $A$ we need unit eigenvectors which are orthogonal to each other. The eigenvector $\bigl[ 2 \ 2 \ 1 \bigr]^\top$ is "nice" since its length is the integer $3$ (that is, it does not involve square-root). However neither of the eigenvectors in the basis of the eigenspace corresponding to $-1$ has this property. But, if we add the vectors of the basis of the eigenspace corresponding to $-1$ we get $\bigl[ -2 \ 1 \ 2 \bigr]^\top$ and the length of this vector is also $3$. Now we need to find an eigenvector corresponding to $-1$ orthogonal to $\bigl[ -2 \ 1 \ 2 \bigr]^\top.$ To do that we use $\bigl[ -1 \ 1 \ 0 \bigr]^\top$ and apply the Gram-Schmidt orthogonalization to two vectors. \begin{align*} \mathbf{v}_1 & = \left[ \begin{array}{r} -2 \\ 1 \\ 2 \end{array} \right], \\ \mathbf{v}_2 & = \left[ \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \right] - \frac{3}{9} \left[ \begin{array}{r} -2 \\ 1 \\ 2 \end{array} \right] = \left[ \begin{array}{r} -1/3 \\ 2/3 \\ -2/3 \end{array} \right] \quad \text{take the opposite vector, fewer - signs!} \end{align*} Thus, three orthogonal unit eigenvectors of $A$ are \[ \frac{1}{3}\left[ \begin{array}{r} -2 \\ 1 \\ 2 \end{array} \right], \quad \frac{1}{3}\left[ \begin{array}{r} 1 \\ -2 \\ 2 \end{array} \right], \quad \frac{1}{3}\left[ \begin{array}{r} 2 \\ 2 \\ 1 \end{array} \right]. \]
- Thus, the orthogonal diagonalization of $A$ is \[ \left[ \begin{array}{ccc} 3 & 4 & 2 \\ 4 & 3 & 2 \\ 2 & 2 & 0 \end{array} \right] = \left[ \begin{array}{rrr} -2/3 & 1/3 & 2/3 \\ 1/3 & -2/3 & 2/3 \\ 2/3 & 2/3 & 1/3 \end{array} \right] \left[ \begin{array}{rrr} -1 & 0 & 0 \\ 0 & -1 & 0 \\ 0 & 0 & 8 \end{array} \right] \left[ \begin{array}{rrr} -2/3 & 1/3 & 2/3 \\ 1/3 & -2/3 & 2/3 \\ 2/3 & 2/3 & 1/3 \end{array} \right]. \]
- As explained in class and in the textbook, this equality can be written as the following equality: \[ \left[ \begin{array}{ccc} 3 & 4 & 2 \\ 4 & 3 & 2 \\ 2 & 2 & 0 \end{array} \right] = (-1) \left[ \begin{array}{rr} -2/3 & 1/3 \\ 1/3 & -2/3 \\ 2/3 & 2/3 \end{array} \right] \left[ \begin{array}{rrr} -2/3 & 1/3 & 2/3 \\ 1/3 & -2/3 & 2/3 \end{array} \right] + 8 \left[ \begin{array}{r} 2/3 \\ 2/3 \\ 1/3 \end{array} \right] \left[ \begin{array}{ccc} 2/3 & 2/3 & 1/3 \end{array} \right]. \] Recall that the matrix \[ \left[ \begin{array}{rr} -2/3 & 1/3 \\ 1/3 & -2/3 \\ 2/3 & 2/3 \end{array} \right] \left[ \begin{array}{rrr} -2/3 & 1/3 & 2/3 \\ 1/3 & -2/3 & 2/3 \end{array} \right] = \frac{1}{9} \left[ \begin{array}{rrr} 5 & -4 & -2 \\ -4 & 5 & -2 \\ -2 & -2 & 8 \end{array} \right] = P_{-1} \] is the orthogonal projection onto $ \operatorname{Nul}(A-(-1)I_3)$ and the matrix \[ \left[ \begin{array}{r} 2/3 \\ 2/3 \\ 1/3 \end{array} \right] \left[ \begin{array}{ccc} 2/3 & 2/3 & 1/3 \end{array} \right] = \frac{1}{9} \left[ \begin{array}{rrr} 4 & 4 & 2 \\ 4 & 4 & 2 \\ 2 & 2 & 1 \end{array} \right] = P_8 \] is the orthogonal projection onto $\operatorname{Nul}(A-8I_3).$ Finally we can write the Spectral Decomposition of $A$: \[ \left[ \begin{array}{ccc} 3 & 4 & 2 \\ 4 & 3 & 2 \\ 2 & 2 & 0 \end{array} \right] = (-1) \frac{1}{9} \left[ \begin{array}{rrr} 5 & -4 & -2 \\ -4 & 5 & -2 \\ -2 & -2 & 8 \end{array} \right] + 8 \frac{1}{9} \left[ \begin{array}{rrr} 4 & 4 & 2 \\ 4 & 4 & 2 \\ 2 & 2 & 1 \end{array} \right] . \] Or, briefly, we can write \[ A = (-1) P_{-1} + 8 P_8, \] where $P_{-1}$ is the orthogonal projection onto $\operatorname{Nul}(A-(-1)I_3)$ and $P_8$ is the orthogonal projection onto $\operatorname{Nul}(A-8I_3).$
- The projection matrices $P_{-1}$ and $P_8$ have the following properties: \[ (P_{-1})^2 = P_{-1}, \quad P_{-1}^\top = P_{-1}, \quad I_3 - P_{-1} = P_8, \quad P_{-1} P_8 = 0, \] \[ (P_{8})^2 = P_{8}, \quad P_{8}^\top = P_{8}, \quad I_3 - P_{8} = P_{-1}, \quad P_{8} P_{-1} = 0. \]
- Please enjoy: \[ \left[ \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \right] = \frac{1}{9} \left[ \begin{array}{rrr} 5 & -4 & -2 \\ -4 & 5 & -2 \\ -2 & -2 & 8 \end{array} \right] + \frac{1}{9} \left[ \begin{array}{rrr} 4 & 4 & 2 \\ 4 & 4 & 2 \\ 2 & 2 & 1 \end{array} \right] \] and then just by scaling the projections with the eigenvalues we get \[ A = \left[ \begin{array}{ccc} 3 & 4 & 2 \\ 4 & 3 & 2 \\ 2 & 2 & 0 \end{array} \right] = (-1) \frac{1}{9} \left[ \begin{array}{rrr} 5 & -4 & -2 \\ -4 & 5 & -2 \\ -2 & -2 & 8 \end{array} \right] + 8 \frac{1}{9} \left[ \begin{array}{rrr} 4 & 4 & 2 \\ 4 & 4 & 2 \\ 2 & 2 & 1 \end{array} \right] . \] We can modify the eigenvalues and define a new matrix: \[ B = \frac{1}{3} \left[ \begin{array}{ccc} 1 & 4 & 2 \\ 4 & 1 & 2 \\ 2 & 2 & -2 \end{array} \right] = (-1) \frac{1}{9} \left[ \begin{array}{rrr} 5 & -4 & -2 \\ -4 & 5 & -2 \\ -2 & -2 & 8 \end{array} \right] + 2 \frac{1}{9} \left[ \begin{array}{rrr} 4 & 4 & 2 \\ 4 & 4 & 2 \\ 2 & 2 & 1 \end{array} \right] . \] Pay attention to the changes that I made and you can tell (or guess) without any calculations what is the relationship between the matrices $B$ and $A.$
- Suggested problems for Section 7.1: 3, 4, 9, 11, 15, 19, 23, 24, 25, 27, 30, 33, 35.
-
In the first Theorem in the next item we work with complex numbers. We review some basic facts about complex numbers.
The Complex Numbers. A complex number is commonly represented as $z = x + i y$ where $i$ is the imaginary unit with the property $i^2 = -1$ and $x$ and $y$ are real numbers. The real number $x$ is called the real part of $z$ and the real number $y$ is called the imaginary part of $z.$ A real number is a special complex numbers whose imaginary part is $0.$ The set of all complex numbers is denoted by $\mathbb C.$
The Complex Conjugate. By $\overline{z}$ we denote the complex conjugate of $z$. The complex conjugate of $z = x+i y$ is the complex number $\overline{z} = x - i y.$ That is, the complex conjugate $\overline{z}$ is the complex numer which has the same real part as $z$ and the imaginary part of $\overline{z}$ is the opposite of the imaginary part of $z.$ Since $-0 = 0$, a comlex number $z$ is real if and only if $\overline{z} = z.$ The operation of complex conjugation respects the algebraic operations with complex numbers: \[ \overline{z + w} = \overline{z} + \overline{w}, \quad \overline{z - w} = \overline{z} - \overline{w}, \quad \overline{z\, w} = \overline{z}\, \overline{w}. \]
The Modulus. Let $z = x + i y$ be a complex number. Here $x$ is the real part of $z$ and $y$ is the imaginary part of $z.$ The modulus of $z$ is the nonnegative number $\sqrt{x^2+y^2}.$ The modulus of $z$ is denoted by $|z|.$ Clearly, $|z|^2 = z\overline{z}$.
Vectors with Complex Entries. Let $\mathbf v$ be a vector with complex entries. By $\overline{\mathbf{v}}$ we denote the vector whose entries are complex conugates of the corresponding entries of $\mathbf v.$ That is, \[ \mathbf v = \left[\begin{array}{c} v_1 \\ \vdots \\ v_n \end{array} \right], \qquad \overline{\mathbf v} = \left[\begin{array}{c} \overline{v}_1 \\ \vdots \\ \overline{v}_n \end{array} \right]. \] The following calculation for a vector with complex entries is often useful \[ \mathbf{v}^\top \overline{\mathbf{v}} = \bigl[v_1 \ \ v_2 \ \ \cdots \ \ v_n \bigr] \left[\begin{array}{c} \overline{v}_1 \\ \overline{v}_2 \\ \vdots \\ \overline{v}_n \end{array} \right] = \sum_{k=1}^n v_k\, \overline{v}_k = \sum_{k=1}^n |v_k|^2 \geq 0. \] Moreover, \[ \mathbf{v}^\top \overline{\mathbf{v}} = 0 \quad \text{if and only if} \quad \mathbf{v} = \mathbf{0}. \] Equivalently, \[ \mathbf{v}^\top \overline{\mathbf{v}} \gt 0 \quad \text{if and only if} \quad \mathbf{v} \neq \mathbf{0}. \]
-
There are several important theorems in Section 7.1. Their proofs are presented in this item.
Theorem. All eigenvalues of a symmetric matrix are real.
Proof. Let $A$ be a symmetric $n\!\times\!n$ matrix and let $\lambda$ be an eigenvalue of $A$. Let $\mathbf{v} = \bigl[v_1 \ \ v_2 \ \ \cdots \ \ v_n \bigr]^\top$ be a corresponding eigenvector. Then $\mathbf{v} \neq \mathbf{0}.$ We allow the possibility that $\lambda$ and the entries $v_1,$ $v_2,\ldots,$ $v_n$ of $\mathbf{v}$ are complex numbers. Since $\mathbf{v}$ is an eigenvector of $A$ corresponding to $\lambda$ we have \[ A \mathbf{v} = \lambda \mathbf{v}. \] Since $A$ is a symmetric matrix, all the entries of $A$ are real numbers. It follows from the properties of the complex conjugation that taking the complex conjugate of each side of the equality $A \mathbf{v} = \lambda \mathbf{v}$ yields \[ A \overline{\mathbf{v}} = \overline{\lambda} \overline{\mathbf{v}}. \] Since $A$ is symmetric, that is $A=A^\top$, we also have \[ A^\top \overline{\mathbf{v}} = \overline{\lambda} \overline{\mathbf{v}}. \] Multiplying both sides of the last equation by $\mathbf{v}^\top$ we get \[ \mathbf{v}^\top \bigl( A^\top \overline{\mathbf{v}} \bigr) = \mathbf{v}^\top ( \overline{\lambda} \overline{\mathbf{v}}). \] Since $\mathbf{v}^\top A^\top = \bigl(A\mathbf{v}\bigr)^\top$ and $\mathbf{v}^\top ( \overline{\lambda} \overline{\mathbf{v}}) = \overline{\lambda} \mathbf{v}^\top \overline{\mathbf{v}}$ the last displayed equality is equivalent to \[ \bigl(A\mathbf{v}\bigr)^\top \overline{\mathbf{v}} = \overline{\lambda} \mathbf{v}^\top \overline{\mathbf{v}}. \] Since $A \mathbf{v} = \lambda \mathbf{v},$ we further have \[ \bigl(\lambda \mathbf{v}\bigr)^\top \overline{\mathbf{v}} = \overline{\lambda} \mathbf{v}^\top \overline{\mathbf{v}}. \] That is, \[ \tag{*} \lambda \mathbf{v}^\top \overline{\mathbf{v}} = \overline{\lambda} \mathbf{v}^\top \overline{\mathbf{v}}. \] As explained in Vectors with Complex Entries item, $\mathbf{v} \neq \mathbf{0},$ implies $\mathbf{v}^\top \overline{\mathbf{v}} \gt 0.$ Now dividing both sides of equality (*) by $\mathbf{v}^\top \overline{\mathbf{v}} \gt 0$ yields \[ \lambda = \overline{\lambda}. \] As explained in The Complex Conjugate item above, this proves that $\lambda$ is a real number.
Theorem. Eigenspaces of a symmetric matrix which correspond to distinct eigenvalues are orthogonal.
Proof. Let $A$ be a symmetric $n\!\times\!n$ matrix. Let $\lambda$ and $\mu$ be an eigenvalues of $A$ and let $\mathbf{u}$ and $\mathbf{v}$ be a corresponding eigenvector. Then $\mathbf{u} \neq \mathbf{0},$ $\mathbf{v} \neq \mathbf{0}$ and \[ A \mathbf{u} = \lambda \mathbf{u} \quad \text{and} \quad A \mathbf{v} = \mu \mathbf{v}. \] Assume that \[ \lambda \neq \mu. \] Next we calculate the same dot product in two different ways; here we use the fact that $A^\top = A$ and algebra of the dot product. The first calculation: \[ (A \mathbf{u})\cdot \mathbf{v} = (\lambda \mathbf{u})\cdot \mathbf{v} = \lambda (\mathbf{u}\cdot\mathbf{v}) \] The second calculation: \begin{align*} (A \mathbf{u})\cdot \mathbf{v} & = (A \mathbf{u})^\top \mathbf{v} = \mathbf{u}^\top A^\top \mathbf{v} = \mathbf{u} \cdot \bigl(A^\top \mathbf{v} \bigr) = \mathbf{u} \cdot \bigl(A \mathbf{v} \bigr) \\ & = \mathbf{u} \cdot (\mu \mathbf{v} ) = \mu ( \mathbf{u} \cdot \mathbf{v}) \end{align*} Since, \[ (A \mathbf{u})\cdot \mathbf{v} = \lambda (\mathbf{u}\cdot\mathbf{v}) \quad \text{and} \quad (A \mathbf{u})\cdot \mathbf{v} = \mu (\mathbf{u}\cdot\mathbf{v}) \] we conclude that \[ \lambda (\mathbf{u}\cdot\mathbf{v}) - \mu (\mathbf{u}\cdot\mathbf{v}) = 0. \] Therefore \[ ( \lambda - \mu ) (\mathbf{u}\cdot\mathbf{v}) = 0. \] Since we assume that $ \lambda - \mu \neq 0,$ the previous displayed equality yields \[ \mathbf{u}\cdot\mathbf{v} = 0. \] This proves that any two eigenvectors corresponding to distinct eigenvalues are orthogonal. Thus, the eigenspaces corresponding to distinct eigenvalues are orthogonal.
Theorem. A symmetric $2\!\times\!2$ matrix is orthogonally diagonalizable.
Proof. Let $A = \begin{bmatrix} a & b \\ b & d \end{bmatrix}$ be an arbitrary $2\!\times\!2$ be a symmetric matrix. We need to prove that there exists an orthogonal $2\!\times\!2$ matrix $U$ and a diagonal $2\!\times\!2$ matrix $D$ such that $A = UDU^\top.$ The eigenvalues of $A$ are \[ \lambda_1 = \frac{1}{2} \Bigl( a+d - \sqrt{(a-d)^2 + 4 b^2} \Bigr), \quad \lambda_2 = \frac{1}{2} \Bigl( a+d + \sqrt{(a-d)^2 + 4 b^2} \Bigr) \] Since clearly \[ (a-d)^2 + 4 b^2 \geq 0, \] the eigenvalues $\lambda_1$ and $\lambda_2$ are real numbers.
If $\lambda_1 = \lambda_2$, then $(a-d)^2 + 4 b^2 = 0$, and consequently $b= 0$ and $a=d$; that is $A = \begin{bmatrix} a & 0 \\ 0 & a \end{bmatrix}$. Hence $A = UDU^\top$ holds with $U=I_2$ and $D = A$.
Now assume that $\lambda_1 \neq \lambda_2$. Let $\mathbf{u}_1$ be a unit eigenvector corresponding to $\lambda_1$ and let $\mathbf{u}_2$ be a unit eigenvector corresponding to $\lambda_2$. We proved that eigenvectors corresponding to distinct eigenvalues of a symmetric matrix are orthogonal. Since $A$ is symmetric, $\mathbf{u}_1$ and $\mathbf{u}_2$ are orthogonal, that is the matrix $U = \begin{bmatrix} \mathbf{u}_1 & \mathbf{u}_2 \end{bmatrix}$ is orthogonal. Since $\mathbf{u}_1$ and $\mathbf{u}_2$ are eigenvectors of $A$ we have \[ AU = U \begin{bmatrix} \lambda_1 & 0 \\ 0 & \lambda_2 \end{bmatrix} = UD. \] Therefore $A=UDU^\top.$ This proves that $A$ is orthogonally diagonalizable.
Second Proof. Let $A = \begin{bmatrix} a & b \\ b & d \end{bmatrix}$ an arbitrary $2\!\times\!2$ be a symmetric matrix. If $b=0$, then an orthogonal diagonalization is \[ \begin{bmatrix} a & 0 \\ 0 & d \end{bmatrix} = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}\begin{bmatrix} a & 0 \\ 0 & d \end{bmatrix}\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}. \]
Assume that $b\neq0.$ For the given $a,b,c \in \mathbb{R},$ introduce three new coordinates $z \in \mathbb{R},$ $r \in (0,+\infty),$ and $\theta \in (0,\pi)$ such that \begin{align*} z & = \frac{a+d}{2}, \\ r & = \sqrt{\left( \frac{a-d}{2} \right)^2 + b^2}, \\ \cos(2\theta) & = \frac{\frac{a-d}{2}}{r}, \quad \sin(2\theta) = \frac{b}{r}. \end{align*} The reader will notice that these coordinates are very similar to the cylindrical coordinates in $\mathbb{R}^3.$
It is now an exercise in matrix multiplication and trigonometry to calculate \begin{align*} & \begin{bmatrix} \cos(\theta) & -\sin(\theta) \\ \sin(\theta) & \cos(\theta) \end{bmatrix} \begin{bmatrix} z+r & 0 \\ 0 & z-r \end{bmatrix}\begin{bmatrix} \cos(\theta) & \sin(\theta) \\ -\sin(\theta) & \cos(\theta) \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} \cos(\theta) & -\sin(\theta) \\ \sin(\theta) & \cos(\theta) \end{bmatrix} \begin{bmatrix} (z+r) \cos(\theta) & (z+r) \sin(\theta) \\ (r-z)\sin(\theta) & (z-r) \cos(\theta) \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} (z+r) (\cos(\theta))^2 - (r-z)(\sin(\theta))^2 & (z+r) \cos(\theta) \sin(\theta) -(z-r) \cos(\theta) \sin(\theta) \\ (z+r) \cos(\theta) \sin(\theta) + (r-z) \cos(\theta) \sin(\theta) & (z+r) (\sin(\theta))^2 + (z-r)(\cos(\theta))^2 \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} z + r \cos(2\theta) & r \sin(2\theta) \\ r \sin(2\theta) & z - r \cos(2\theta) \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} \frac{a+d}{2} + \frac{a-d}{2} & b \\ b & \frac{a+d}{2} - \frac{a-d}{2} \end{bmatrix} \\[6pt] & \quad = \begin{bmatrix} a & b \\ b & d \end{bmatrix}. \end{align*}Theorem. For every positive integer $n$, a symmetric $n\!\times\!n$ matrix is orthogonally diagonalizable.
Proof. This statement can be proved by Mathematical Induction. The base case $n = 1$ is trivial. The case $n=2$ is proved above. To get a feel how mathematical induction proceeds we will prove the theorem for $n=3.$
Let $A$ be a $3\!\times\!3$ symmetric matrix. Then $A$ has an eigenvalue, which must be real. Denote this eigenvalue by $\lambda_1$ and let $\mathbf{u}_1$ be a corresponding unit eigenvector. Let $\mathbf{v}_1$ and $\mathbf{v}_2$ be unit vectors such that the vectors $\mathbf{u}_1,$ Let $\mathbf{v}_1$ and $\mathbf{v}_2$ form an orthonormal basis for $\mathbb R^3.$ Then the matrix $V_1 = \bigl[\mathbf{u}_1 \ \ \mathbf{v}_1\ \ \mathbf{v}_2\bigr]$ is an orthogonal matrix and we have \[ V_1^\top A V_1 = \begin{bmatrix} \mathbf{u}_1^\top A \mathbf{u}_1 & \mathbf{u}_1^\top A \mathbf{v}_1 & \mathbf{u}_1^\top A \mathbf{v}_2 \\[5pt] \mathbf{v}_1^\top A \mathbf{u}_1 & \mathbf{v}_1^\top A \mathbf{v}_1 & \mathbf{v}_1^\top A \mathbf{v}_2 \\[5pt] \mathbf{v}_2^\top A \mathbf{u}_1 & \mathbf{v}_2^\top A \mathbf{v}_1 & \mathbf{v}_2^\top A \mathbf{v}_2 \\\end{bmatrix}. \] Since $A = A^\top$, $A\mathbf{u}_1 = \lambda_1 \mathbf{u}_1$ and since $\mathbf{u}_1$ is orthogonal to both $\mathbf{v}_1$ and $\mathbf{v}_2$ we have \[ \mathbf{u}_1^\top A \mathbf{u}_1 = \lambda_1, \quad \mathbf{v}_j^\top A \mathbf{u}_1 = \lambda_1 \mathbf{v}_j^\top \mathbf{u}_1 = 0, \quad \mathbf{u}_1^\top A \mathbf{v}_j = \bigl(A \mathbf{u}_1\bigr)^\top \mathbf{v}_j = 0, \quad \quad j \in \{1,2\}, \] and \[ \mathbf{v}_2^\top A \mathbf{v}_1 = \bigl(\mathbf{v}_2^\top A \mathbf{v}_1\bigr)^\top = \mathbf{v}_1^\top A^\top \mathbf{v}_2 = \mathbf{v}_1^\top A \mathbf{v}_2. \] Hence, \[ \tag{**} V_1^\top A V_1 = \begin{bmatrix} \lambda_1 & 0 & 0 \\[5pt] 0 & \mathbf{v}_1^\top A \mathbf{v}_1 & \mathbf{v}_1^\top A \mathbf{v}_2 \\[5pt] 0 & \mathbf{v}_1^\top A \mathbf{v}_2 & \mathbf{v}_2^\top A \mathbf{v}_2 \\\end{bmatrix}. \] By the already proved theorem for $2\!\times\!2$ symmetric matrix there exists an orthogonal matrix $\begin{bmatrix} u_{11} & u_{12} \\[5pt] u_{21} & u_{22} \end{bmatrix}$ and a diagonal matrix $\begin{bmatrix} \lambda_2 & 0 \\[5pt] 0 & \lambda_3 \end{bmatrix}$ such that \[ \begin{bmatrix} \mathbf{v}_1^\top A \mathbf{v}_1 & \mathbf{v}_1^\top A \mathbf{v}_2 \\[5pt] \mathbf{v}_1^\top A \mathbf{v}_2 & \mathbf{v}_2^\top A \mathbf{v}_2 \end{bmatrix} = \begin{bmatrix} u_{11} & u_{12} \\[5pt] u_{21} & u_{22} \end{bmatrix} \begin{bmatrix} \lambda_2 & 0 \\[5pt] 0 & \lambda_3 \end{bmatrix} \begin{bmatrix} u_{11} & u_{12} \\[5pt] u_{21} & u_{22} \end{bmatrix}^\top. \] Substituting this equality in (**) and using some matrix algebra we get \[ V_1^\top A V_1 = \begin{bmatrix} 1 & 0 & 0 \\[5pt] 0 & u_{11} & u_{12} \\[5pt] 0 & u_{21} & u_{22} \end{bmatrix} % \begin{bmatrix} \lambda_1 & 0 & 0 \\[5pt] 0 & \lambda_2 & 0 \\[5pt] 0 & 0 & \lambda_3 \end{bmatrix} % \begin{bmatrix} 1 & 0 & 0 \\[5pt] 0 & u_{11} & u_{12} \\[5pt] 0 & u_{21} & u_{22} \end{bmatrix}^\top \] Setting \[ U = V_1 \begin{bmatrix} 1 & 0 & 0 \\[5pt] 0 & u_{11} & u_{12} \\[5pt] 0 & u_{21} & u_{22} \end{bmatrix} \quad \text{and} \quad D = \begin{bmatrix} \lambda_1 & 0 & 0 \\[5pt] 0 & \lambda_2 & 0 \\[5pt] 0 & 0 & \lambda_3 \end{bmatrix} \] we have that $U$ is an orthogonal matrix, $D$ is a diagonal matrix and $A = UDU^\top.$ This proves that $A$ is orthogonally diagonalizable.
- Today we discussed Section 6.7 Inner Product Spaces. Suggested problems for Section 6.7: 1, 2, 3, 5, 7, 9, 10, 13, 16, 17, 19, 20, 21, 23, 25
- The most important abstract inner products are inner products given by the Riemann integral in vector spaces of functions. I illustrate this with the inner product \[ \langle p, q \rangle = \int_{-1}^{1} p(t) q(t) dt \] in the vector space of polynomials. We can restrict ourselves to the space $\mathbb{P}_4.$ The standard basis in $\mathbb{P}_4$ is the basis which consists of monomials: \[ p_0(t) = 1, \quad p_1(t) = t, \quad p_2(t) = t^2, \quad p_3(t) = t^3, \quad p_4(t) = t^4. \] Set \[ \mathcal M = \bigl\{ p_0, p_1, p_2, p_3, p_4 \bigr\}. \] $\mathcal M$ is not an orthogonal basis for $\mathbb{P}_5.$ In fact it is useful to calculate \begin{alignat*}{5} \langle p_0, p_0 \rangle & = 2, & \quad \langle p_0, p_1 \rangle & = 0, & \quad \langle p_0, p_2 \rangle & = \frac{2}{3}, & \quad \langle p_0, p_3 \rangle & = 0, & \quad \langle p_0, p_4 \rangle & = \frac{2}{5}, \\ \langle p_1, p_0 \rangle & = 0, & \quad \langle p_1, p_1 \rangle & = \frac{2}{3}, & \quad \langle p_1, p_2 \rangle & = 0, & \quad \langle p_1, p_3 \rangle & = \frac{2}{5}, & \quad \langle p_1, p_4 \rangle & = 0, \\ \langle p_2, p_0 \rangle & = \frac{2}{3}, & \quad \langle p_2, p_1 \rangle & = 0, & \quad \langle p_2, p_2 \rangle & = \frac{2}{5}, & \quad \langle p_2, p_3 \rangle & = 0, & \quad \langle p_2, p_4 \rangle & = \frac{2}{7}, \\ \langle p_3, p_0 \rangle & = 0, & \quad \langle p_3, p_1 \rangle & = \frac{2}{5}, & \quad \langle p_3, p_2 \rangle & = 0, & \quad \langle p_3, p_3 \rangle & = \frac{2}{7}, & \quad \langle p_3, p_4 \rangle & = 0, \\ \langle p_4, p_0 \rangle & = \frac{2}{5}, & \quad \langle p_4, p_1 \rangle & = 0, & \quad \langle p_4, p_2 \rangle & = \frac{2}{7}, & \quad \langle p_4, p_3 \rangle & = 0, & \quad \langle p_4, p_4 \rangle & = \frac{2}{9}. \\ \end{alignat*}
- One conclusion from the above table is that monomials of even degree are orthogonal to the monomials of odd degree. We will use this fact in the calculations in the next item.
- We can apply the Gram-Schmidt orthogonalization algorithm to the basis $\mathcal M$ obtain an orthogonal basis \[ \mathcal A = \bigl\{q_0, q_1, q_2, q_3, q_4 \bigr\} \] for $\mathbb{P}_5:$ \begin{align*} q_0(t) & = 1 \\ q_1(t) & = t \\ q_2(t) & = t^2 - \frac{\langle p_2, q_0 \rangle }{\langle q_0, q_0 \rangle} 1 = t^2 - \frac{1}{3} \\ q_3(t) & = t^3 - \frac{\langle p_3, q_1 \rangle }{\langle q_1, q_1 \rangle} t = t^3 - \frac{3}{5} t \\ q_4(t) & = t^4 - \frac{\langle p_4, q_0 \rangle }{\langle q_0, q_0 \rangle} 1 - \frac{\langle p_4, q_2 \rangle }{\langle q_2, q_2 \rangle} \left(t^2 - \frac{1}{3}\right) = t^4 - \frac{6}{7} t^2 + \frac{3}{35} \\ \end{align*} In the above calculation we used that \[ \langle q_0, q_0 \rangle = 2, \quad \langle q_1, q_1 \rangle =\frac{2}{3}, \quad \langle q_2, q_2 \rangle = \frac{8}{45} \] and \[ \langle p_2, q_0 \rangle = \frac{2}{3}, \quad \langle p_3, q_1 \rangle = \frac{2}{5}, \quad \langle p_4, q_0 \rangle = \frac{2}{5}, \quad \langle p_4, q_2 \rangle = \frac{16}{105}. \]
- It is common to normalize the polynomials $q_0, q_1, q_2, q_3, q_4$ so that they have values $1$ at $t=1.$ First calculate \[ q_0(1) = 1, \quad q_1(1) = 1, \quad q_2(1) = \frac{2}{3}, \quad q_3(1) = \frac{2}{5}, \quad q_4(1) = \frac{8}{35}. \] The polynomials \begin{alignat*}{2} P_0(t) & = 1 & & \\ P_1(t) & = t & & \\ P_2(t) & = \frac{1}{2} \left( 3 t^2 -1 \right) & & = \frac{3}{2} q_2(t) \\ P_3(t) & = \frac{1}{2} \left( 5 t^3 -3 t \right) & & = \frac{5}{2} q_3(t) \\ P_4(t) & = \frac{1}{8} \left( 35 t^4 - 30 t^2 + 3 \right) & & = \frac{35}{8} q_4(t) \\ \end{alignat*} The polynomials $P_0, P_1, P_2, P_3, P_4$ are the first five of the sequence of orthogonal polynomials called Legendre polynomials.
- There are many examples of other sequences of orthogonal polynomials. Legendre polynomials is just one example which is presented here since the inner product in which they are orthogonal is particularly simple.
- Suggested problems for Section 6.6: 1, 2, 3, 4, 5, 6, 7, 8, 9, 14, 15, 16
-
Exercise 4 in Section 6.6 is a simple interesting problem. In this exercise we are given four data points
\[
( 2,3), \ \ (3,2), \ \ (5,1), \ \ (6,0),
\]
and we are asked to find the least-squares line that best fits the given data points. (We will call this line simply the least-squares line.)
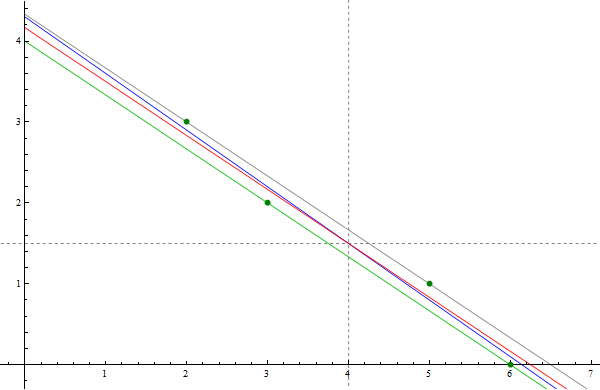
- Notice that these four points form a very narrow parallelogram. A characterizing property of a parallelogram is that its diagonals share the midpoint. For this parallelogram, the coordinates of the common midpoint of the diagonals are \[ \overline{x} = \frac{1}{4}(2+3+5+6) = 4, \quad \overline{y} = \frac{1}{4}(3+2+1+0) = 3/2. \] The long sides of this parallelogram are on the parallel lines $y = -2x/3 +4$ and $y = -2x/3 + 13/3.$ It is natural to guess that the least square line is the line which is parallel to these two lines and half-way between them. That is the line $y = -2x/3 + 25/6.$ This line is the red line in the picture below. Clearly this line goes through the point $(4,3/2),$ the intersection of the diagonals of the parallelogram. The only way to verify this guess is to calculate the least-squares line for these four points. We did that by finding the least-squares solution of the equation \[ \left[\begin{array}{cc} 1 & 2 \\ 1 & 3 \\ 1 & 5 \\ 1 & 6 \end{array} \right] \left[\begin{array}{c} \beta_0 \\ \beta_1 \end{array} \right] = \left[\begin{array}{c} 3 \\ 2 \\ 1 \\ 0 \end{array} \right]. \] The corresponding normal equation is \[ \left[\begin{array}{cc} 4 & 16 \\ 16 & 74 \end{array} \right] \left[\begin{array}{c} \beta_0 \\ \beta_1 \end{array} \right] = \left[\begin{array}{c} 6 \\ 17 \end{array} \right]. \] Since the inverse of the above $2\!\times\!2$ matrix is \[ \frac{1}{40} \left[\begin{array}{cc} 74 & -16 \\ -16 & 4 \end{array} \right], \] the least-squares line for the given data points is \[ y = -\frac{7}{10}x + \frac{43}{10}. \] This line is the blue line in the picture below. The picture below strongly indicates that the blue line also goes through the point $(4,3/2).$ This is easily confirmed: \[ \frac{3}{2} = -\frac{7}{10}4 + \frac{43}{10}. \]
In the image below the forest green points are the given data points. The red line is the line which I guessed could be the least-squares line. The blue line is the true least-squares line.
-
It is amazing that what we observed in the preceding example is universal:
Proposition. If the line $y = \beta_0 + \beta_1 x$ is the least-squares line for the data points \[ (x_1,y_1), \ldots, (x_n,y_n), \] then $\overline{y} = \beta_0 + \beta_1 \overline{x}$, where \[ \overline{x} = \frac{1}{n}(x_1+\cdots+x_n), \quad \overline{y} = \frac{1}{n}(y_1+\dots+y_n). \]
The above proposition is Exercise 14 in Section 6.6.Proof. Let \[ (x_1,y_1), \ldots, (x_n,y_n), \] be given data points and set \[ \overline{x} = \frac{1}{n}(x_1+\cdots+x_n), \quad \overline{y} = \frac{1}{n}(y_1+\dots+y_n). \] Let $y = \beta_0 + \beta_1 x$ be the least-squares line for the given data points. Then the vector $\left[\begin{array}{c} \beta_0 \\ \beta_1 \end{array} \right]$ satisfies the normal equation \[ \left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ x_1 & x_2 & \cdots & x_n \end{array} \right] \left[\begin{array}{cc} 1 & x_1 \\ 1 & x_2 \\ \vdots & \vdots \\ 1 & x_n \end{array} \right] \left[\begin{array}{c} \beta_0 \\ \beta_1 \end{array} \right] = \left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ x_1 & x_2 & \cdots & x_n \end{array} \right] \left[\begin{array}{c} y_1 \\ y_2 \\ \vdots \\ y_n \end{array} \right]. \] Multiplying the second matrix on the left-hand side and the third vector we get \[ \left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ x_1 & x_2 & \cdots & x_n \end{array} \right] \left[\begin{array}{c} \beta_0 + \beta_1 x_1 \\ \beta_0 + \beta_1 x_2 \\ \vdots \\ \beta_0 + \beta_1 x_n \end{array} \right] = \left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ x_1 & x_2 & \cdots & x_n \end{array} \right] \left[\begin{array}{c} y_1 \\ y_2 \\ \vdots \\ y_n \end{array} \right]. \] The above equality is an equality of vectors with two components. The top components of these vectors are equal: \[ (\beta_0 + \beta_1 x_1) + (\beta_0 + \beta_1 x_2) + \cdots + (\beta_0 + \beta_1 x_n) = y_1 + y_2 + \cdots + y_n. \] Therefore \[ n \beta_0 + \beta_1 (x_1+x_3 + \cdots + x_n) = y_1 + y_2 + \cdots + y_n. \] Dividing by $n$ we get \[ \beta_0 + \beta_1 \frac{1}{n} (x_1+x_3 + \cdots + x_n) = \frac{1}{n}( y_1 + y_2 + \cdots + y_n). \] Hence \[ \overline{y} = \beta_0 + \beta_1 \overline{x}. \] QED.
-
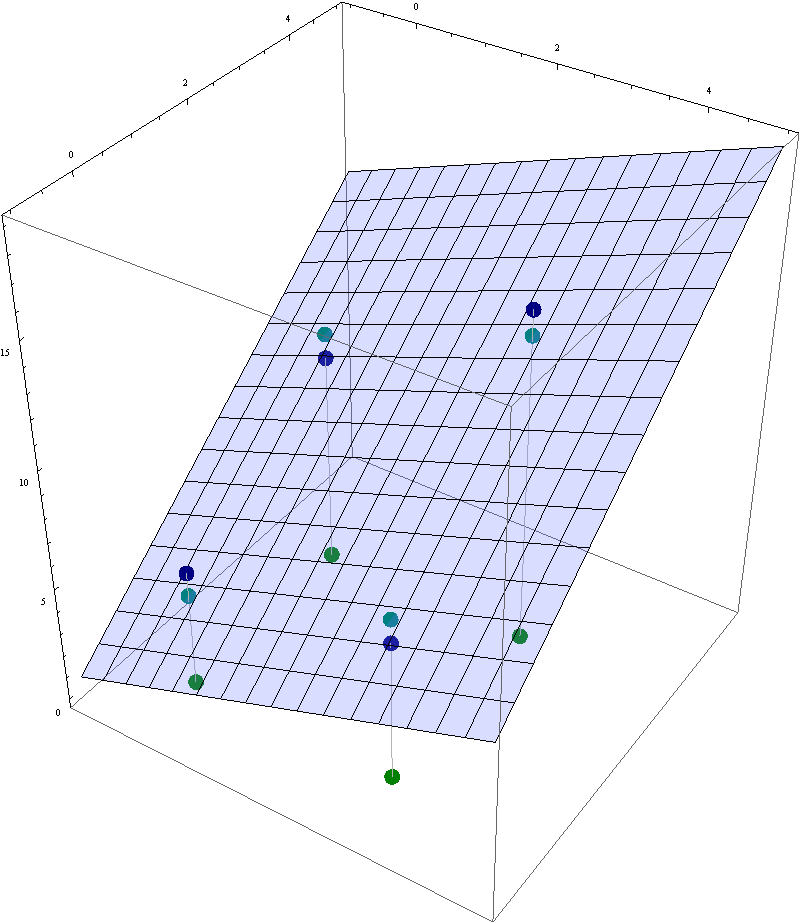
Do the following problem: Consider the following four data points
\[
( 0, 0, 5), \ \ (3, 0, 6), \ \ (3, 3, 14), \ \ (0, 3, 9).
\]
- Find the equation $z = \beta_0 + \beta_1 x +\beta_2 y$ of the least-squares plane that best fits the data points.
- Find the coordinates of the dark green points and the teal points in the picture below.
- Calculate the residual vector and the least-squares error.
- Find the equation of the plane through the data points \[ ( 0, 0, 5), \ \ (3, 0, 6), \ \ (0, 3, 9). \] Show that the least-squares error is larger for this plane than the error for the least-squares plane.
In this image the navy blue points are the given data points and the light blue plane is the least-squares plane that best fits these data points. The dark green points are their projections onto the $xy$-plane. The teal points are the corresponding points in the least-square plane.
- The equality $\operatorname{Nul}(A^\top\!\! A ) = \operatorname{Nul}(A)$ made an impression on me. One way to enjoy the feeling of being impressed by a mathematical fact is to think about slightly different circumstances in which similar fact holds.
-
I came up with the following slight variation of the "impressive" equality:
Theorem. Let $m,n,p \in \mathbb{N}.$ Let $A$ be an $n\!\times\!m$ matrix and let $B$ be an $p\!\times\!n$ matrix. Then $\operatorname{Nul}(B A) = \operatorname{Nul}(A)$ if and only if $\operatorname{Col}(A) \cap \operatorname{Nul}(B) = \{\mathbf{0}\}.$
- Suggested problems for Section 6.5: 1, 3, 6, 7, 9, 13, 16, 17, 19, 20, 21, 22
-
Exercise 19 in Section 6.5 is very important. In fact, Exercise 19 in Section 6.5 is the following theorem:
Theorem. Let $A$ be an $n\!\times\!m$ matrix. Then $\operatorname{Nul}(A^\top\!\! A ) = \operatorname{Nul}(A)$.
Proof. The set equality $\operatorname{Nul}(A^\top\!\! A ) = \operatorname{Nul}(A)$ means \[ \mathbf{x} \in \operatorname{Nul}(A^\top\!\! A ) \quad \text{if and only if} \quad \mathbf{x} \in \operatorname{Nul}(A). \] We will prove this equivalence. Assume that $\mathbf{x} \in \operatorname{Nul}(A)$. Then $A\mathbf{x} = \mathbf{0}$. Consequently, \[ (A^\top\!A)\mathbf{x} = A^\top ( \!A\mathbf{x}) = A^\top\mathbf{0} = \mathbf{0}. \] Hence, $(A^\top\!A)\mathbf{x}= \mathbf{0}$, and therefore $\mathbf{x} \in \operatorname{Nul}(A^\top\!\! A )$. Thus, we proved the implication \[ \mathbf{x} \in \operatorname{Nul}(A) \quad \Rightarrow \quad \mathbf{x} \in \operatorname{Nul}(A^\top\!\! A ). \] Now we prove the converse: \[ \tag{*} \mathbf{x} \in \operatorname{Nul}(A^\top\!\! A ) \quad \Rightarrow \quad \mathbf{x} \in \operatorname{Nul}(A). \] Assume, $\mathbf{x} \in \operatorname{Nul}(A^\top\!\! A )$. Then, $(A^\top\!\!A) \mathbf{x} = \mathbf{0}$. Multiplying the last equality by $\mathbf{x}^\top$ we get $\mathbf{x}^\top\! (A^\top\!\! A \mathbf{x}) = 0$. Using the associativity of the matrix multiplication we obtain $(\mathbf{x}^\top\!\! A^\top)A \mathbf{x} = 0$. Using the Linear Algebra with the transpose operation we get $(A \mathbf{x})^\top\!A \mathbf{x} = 0$. Now recall that for every vector $\mathbf{v}$ we have $\mathbf{v}^\top \mathbf{v} = \|\mathbf{v}\|^2$. Thus, we have proved that $\|A\mathbf{x}\|^2 = 0$. Now recall that the only vector whose norm is $0$ is the zero vector, to conclude that $A\mathbf{x} = \mathbf{0}$. This means $\mathbf{x} \in \operatorname{Nul}(A)$. This completes the proof of implication (*). The theorem is proved. □
Corollary 1. Let $A$ be an $n\!\times\!m$ matrix. The columns of $A$ are linearly independent if and only if the $m\!\times\!m$ matrix $A^\top\!\! A$ is invertible.
Corollary 2. Let $A$ be an $n\!\times\!m$ matrix. Then $\operatorname{Col}(A^\top\!\! A ) = \operatorname{Col}(A^\top)$.
Proof. The set equality $\operatorname{Col}(A^\top\!\! A ) = \operatorname{Col}(A^\top)$ means \[ \mathbf{x} \in \operatorname{Col}(A^\top\!\! A ) \quad \text{if and only if} \quad \mathbf{x} \in \operatorname{Col}(A^\top). \] We will prove this equivalence. Assume that $\mathbf{x} \in \operatorname{Col}(A^\top\!\!A).$ Then there exists $\mathbf{v} \in \mathbb{R}^m$ such that $\mathbf{x} = (A^\top\!\!A)\mathbf{v}.$ Since by the definition of matrix multiplication we have $(A^\top\!\!A)\mathbf{v} = A^\top\!(A\mathbf{v})$, we have $\mathbf{x} = A^\top\!(A\mathbf{v}).$ Consequently, $\mathbf{x} \in \operatorname{Col}(A^\top).$ Thus, we proved the implication \[ \mathbf{x} \in \operatorname{Col}(A^\top\!\!A) \quad \Rightarrow \quad \mathbf{x} \in \operatorname{Col}(A^\top). \] Now we prove the converse: \[ \mathbf{x} \in \operatorname{Col}(A^\top) \quad \Rightarrow \quad \mathbf{x} \in \operatorname{Col}(A^\top\!\!A). \] Assume, $\mathbf{x} \in \operatorname{Col}(A^\top).$ Let $\mathbf{y} \in \mathbb{R}^n$ be such that $\mathbf{x} = A^\top\!\mathbf{y}.$ Let $\widehat{\mathbf{y}}$ be the orthogonal projection of $\mathbf{y}$ onto $\operatorname{Col}(A).$ That is $\widehat{\mathbf{y}} \in \operatorname{Col}(A)$ and $\mathbf{y} - \widehat{\mathbf{y}} \in \bigl(\operatorname{Col}(A)\bigr)^{\perp}.$ Since $\widehat{\mathbf{y}} \in \operatorname{Col}(A),$ there exists $\mathbf{v} \in \mathbb{R}^m$ such that $\widehat{\mathbf{y}} = A\mathbf{v}.$ Since $\bigl(\operatorname{Col}(A)\bigr)^{\perp} = \operatorname{Nul}(A^\top),$ the relationship $\mathbf{y} - \widehat{\mathbf{y}} \in \bigl(\operatorname{Col}(A)\bigr)^{\perp}$ yields $A^\top\bigl(\mathbf{y} - \widehat{\mathbf{y}}\bigr) = \mathbf{0}.$ Consequently, since $\widehat{\mathbf{y}} = A\mathbf{v},$ we deduce $A^\top\bigl(\mathbf{y} - A\mathbf{v}\bigr) = \mathbf{0}.$ Hence \[ \mathbf{x} = A^\top\mathbf{y} = \bigl(A^\top\!\!A\bigr) \mathbf{v} \quad \text{with} \quad \mathbf{v} \in \mathbb{R}^m. \] This proves that $\mathbf{x} \in \operatorname{Col}(A^\top\!\!A).$ Thus, the implication \[ \mathbf{x} \in \operatorname{Col}(A^\top) \quad \Rightarrow \quad \mathbf{x} \in \operatorname{Col}(A^\top\!\!A) \] is proved. The corollary is proved. □
Corollary 3. Let $A$ be an $n\!\times\!m$ matrix. The matrices $A^\top$ and $A^\top\!\! A$ have the same rank.
- Corollary 1 in the previous item is stated in Exercises 20 and 21 in Section 6.5. Corollary 2 in the previous item is implicitly stated in Theorem 13 in Section 6.5. Corollary 2 can be proved using the above Theorem and the following facts: \begin{align*} \operatorname{Col}(A^\top\!\! A ) & = \operatorname{Row}(A^\top\!\! A ) = \bigl( \operatorname{Nul}(A^\top\!\! A ) \bigr)^\perp, \\ \operatorname{Col}(A^\top) & = \operatorname{Row}(A) = \bigl( \operatorname{Nul}(A) \bigr)^\perp \end{align*} Corollary 3 in the previous item is stated in Exercise 22 in Section 6.5. Corollary 3 is a simple consequence of Corollary 2. The hint given in Exercise 22 will result in a different proof of Corollary 3.
- We started Section 6.4: Gram-Schmidt Orthogonalization Algorithm today. I made up this name. It seems that it is an appropriate modern name. But, I think that mathematically the most fitting name would be: Gram-Schmidt Orthogonalization Recursion. It is a recursive formula. The formula for the next vector is given in terms of the all previously calculated vectors. Suggested problems for Section 6.4: 2, 3, 5, 7, 9, 13, 15, 17, 19, 20
- The presentation of the $QR$ factorization in the textbook somewhat obscures the direct connection between the Gram-Schmidt orthogonalization algorithm and the $QR$ factorization. Below I will demonstrate the connection.
- We went half-way through this today and we will finish it tomorrow. At the end of today's post there is a proof of the uniqueness of the $QR$ factorization. I wrote a formal proof based on the properties of the matrices $Q$ and $R.$ I hope you can learns something about proofs from how I wrote it.
- Let $\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_m$ be linearly independent vectors in $\mathbb{R}^n$. The Gram-Schmidt orthogonalization algorithm produces the mutually orthogonal vectors \begin{align*} \mathbf{v}_1 & = \mathbf{x}_1 \\ \mathbf{v}_2 & = \mathbf{x}_2 - \frac{\mathbf{x}_2\cdot \mathbf{v}_1}{\mathbf{v}_1 \cdot \mathbf{v}_1} \mathbf{v}_1 \\ \mathbf{v}_3 & = \mathbf{x}_3 - \frac{\mathbf{x}_3\cdot \mathbf{v}_1}{\mathbf{v}_1 \cdot \mathbf{v}_1} \mathbf{v}_1 - \frac{\mathbf{x}_3\cdot \mathbf{v}_2}{\mathbf{v}_2 \cdot \mathbf{v}_2} \mathbf{v}_2 \\ & \ \ \vdots \\ \mathbf{v}_m & = \mathbf{x}_m - \frac{\mathbf{x}_m\cdot \mathbf{v}_1}{\mathbf{v}_1 \cdot \mathbf{v}_1} \mathbf{v}_1 - \cdots - \frac{\mathbf{x}_m\cdot \mathbf{v}_{m-1}}{\mathbf{v}_{m-1} \cdot \mathbf{v}_{m-1}} \mathbf{v}_{m-1} \\ \end{align*} We can rewrite the above vector equations as \begin{align*} \mathbf{x}_1 & = \mathbf{v}_1 \\ \mathbf{x}_2 & = \frac{\mathbf{x}_2\cdot \mathbf{v}_{1}}{\mathbf{v}_{1} \cdot \mathbf{v}_{1}} \mathbf{v}_1 + \mathbf{v}_2 \\ \mathbf{x}_3 & = \frac{\mathbf{x}_3\cdot \mathbf{v}_{1}}{\mathbf{v}_{1} \cdot \mathbf{v}_{1}} \mathbf{v}_1 + \frac{\mathbf{x}_3\cdot \mathbf{v}_{2}}{\mathbf{v}_{2} \cdot \mathbf{v}_{2}} \mathbf{v}_2 + \mathbf{v}_3 \\ & \ \ \vdots \\ \mathbf{x}_m & = \frac{\mathbf{x}_m\cdot \mathbf{v}_{1}}{\mathbf{v}_{1} \cdot \mathbf{v}_{1}} \mathbf{v}_1 + \cdots + \frac{\mathbf{x}_m\cdot \mathbf{v}_{m-1}}{\mathbf{v}_{m-1} \cdot \mathbf{v}_{m-1}} \mathbf{v}_{m-1} + \mathbf{v}_m \\ \end{align*} Now set \[ \mathbf{u}_k = \frac{1}{\|\mathbf{v}_k\|} \mathbf{v}_k \quad \text{for} \quad k \in \{1,\ldots,m\} \] and use the fact that $\mathbf{v}_k \cdot \mathbf{v}_k = \|\mathbf{v}_k\|^2$ to rewrite the vectors $\mathbf{x}_1,\dots, \mathbf{x}_m$ in terms of the orthonormal vectors $\mathbf{u}_1,\ldots,\mathbf{u}_m$: \begin{align*} \mathbf{x}_1 & = \|\mathbf{v}_1\| \mathbf{u}_1 \\ \mathbf{x}_2 & = \frac{\mathbf{x}_2\cdot \mathbf{v}_{1}}{\|\mathbf{v}_1\|} \mathbf{u}_1 + \|\mathbf{v}_2\| \mathbf{u}_2 \\ \mathbf{x}_3 & = \frac{\mathbf{x}_3\cdot \mathbf{v}_{1}}{\|\mathbf{v}_1\|} \mathbf{u}_1 + \frac{\mathbf{x}_3\cdot \mathbf{v}_{2}}{\|\mathbf{v}_2\|} \mathbf{u}_2 + \|\mathbf{v}_3\| \mathbf{u}_3 \\ & \ \ \vdots \\ \mathbf{x}_m & = \frac{\mathbf{x}_m\cdot \mathbf{v}_{1}}{\|\mathbf{v}_1\|} \mathbf{u}_1 + \cdots + \frac{\mathbf{x}_m\cdot \mathbf{v}_{m-1}}{\|\mathbf{v}_{m-1}\|} \mathbf{u}_{m-1} + \|\mathbf{v}_m\| \mathbf{u}_m \end{align*} Now set \[ \alpha_{jk} = \frac{\mathbf{x}_k\cdot \mathbf{v}_{j}}{\|\mathbf{v}_j\|} = \mathbf{x}_k\cdot \mathbf{u}_{j} \quad \text{for} \quad j \in \{1,\ldots,k-1\}, \ \ k \in \{2,\ldots,m\} \] and the above equations can be rewritten as \begin{align*} \mathbf{x}_1 & = \|\mathbf{v}_1\| \mathbf{u}_1 \\ \mathbf{x}_2 & = \alpha_{1,2} \mathbf{u}_1 + \|\mathbf{v}_2\| \mathbf{u}_2 \\ \mathbf{x}_3 & = \alpha_{1,3} \mathbf{u}_1 + \alpha_{2,3} \mathbf{u}_2 + \|\mathbf{v}_3\| \mathbf{u}_3 \\ & \ \ \vdots \\ \mathbf{x}_m & = \alpha_{1,m} \mathbf{u}_1 + \cdots + \alpha_{m-1,m} \mathbf{u}_{m-1} + \|\mathbf{v}_m\| \mathbf{u}_m \\ \end{align*} These vector equations can be written in matrix form as \[ \left[\begin{array}{ccccc} \mathbf{x}_1 & \mathbf{x}_2 & \mathbf{x}_3 & \cdots & \mathbf{x}_m \end{array} \right] = \left[\begin{array}{ccccc} \mathbf{u}_1 & \mathbf{u}_2 & \mathbf{u}_3 & \cdots & \mathbf{u}_m \end{array} \right] \left[\begin{array}{ccccc} \|\mathbf{v}_1\| & \alpha_{1,2} & \alpha_{1,3} & \cdots & \alpha_{1,m} \\ 0 & \|\mathbf{v}_2\| & \alpha_{2,3} & \cdots & \alpha_{2,m} \\ 0 & 0 & \|\mathbf{v}_3\| & \cdots & \alpha_{3,m} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \cdots & \|\mathbf{v}_m\| \\ \end{array} \right] \] The above matrix equation is the $QR$ factorization \[ A = QR \] with \begin{align*} A & = \left[\begin{array}{ccccc} \mathbf{x}_1 & \mathbf{x}_2 & \mathbf{x}_3 & \cdots & \mathbf{x}_m \end{array} \right] \\ Q & = \left[\begin{array}{ccccc} \mathbf{u}_1 & \mathbf{u}_2 & \mathbf{u}_3 & \cdots & \mathbf{u}_m \end{array} \right] \end{align*} and the matrix $R$ is an upper triangular matrix with positive terms on the diagonal. Since the vectors $\mathbf{u}_1, \mathbf{u}_2,\ldots, \mathbf{u}_m$ are orthonormal, we have $Q^{\top} Q = I_m$. Therefore the $m\!\times\!m$ matrix $R$ can be calculated as $R = Q^{\top}A$.
-
Next I will state the $QR$ factorization of a matrix with linearly independent columns as a theorem.
Theorem. Every $n\times m$ matrix $A$ with linearly independent columns can be written as a product $A = QR$ where $Q$ is an $n\times m$ matrix whose columns form an orthonormal basis for the column space of $A$ and $R$ is an $m\times m$ upper triangular invertible matrix with positive entries on its diagonal.
- The $QR$ factorization of a matrix is just the Gram-Schmidt orthogonalization process for the columns of $A$ written in matrix form. The only difference is that a Gram-Schmidt orthogonalization process produces orthogonal vectors which we have to normalize to obtain the matrix $Q$ with orthonormal columns. A nice simple example is given by the $3\!\times\!2$ matrix \[ A = \left[ \begin{array}{rr} 1 & 1 \\[2pt] 2 & 4 \\[2pt] 2 & 3 \end{array}\right]. \] Denote the columns of $A$ by $\mathbf{a}_1$ and $\mathbf{a}_2$. The Gram-Schmidt orthogonalization of the vectors $\mathbf{a}_1$ and $\mathbf{a}_2$ leads to vectors \[ \mathbf{v}_1 = \left[ \begin{array}{r} 1 \\[2pt] 2 \\[2pt] 2 \end{array}\right], \quad \mathbf{v}_2 = \left[ \begin{array}{r} -2/3 \\[2pt] 2/3 \\[2pt] 1/3 \end{array}\right]. \] These vectors are calculated as \[ \tag{*} \mathbf{v}_1 = \mathbf{a}_1, \quad \mathbf{v}_2 = \mathbf{a}_2 - \frac{5}{3} \mathbf{v}_1. \] Next we normalize the vectors $\mathbf{v}_1$ and $\mathbf{v}_2$. The norm of vector $\mathbf{v}_1$ is $3$ and the norm of $\mathbf{v}_2$ is 1. Hence the following vectors are orthonormal: \[ \mathbf{u}_1 = \frac{1}{3} \left[ \begin{array}{r} 1 \\[2pt] 2 \\[2pt] 2 \end{array}\right], \quad \mathbf{u}_2 = \frac{1}{3} \left[ \begin{array}{r} -2 \\[2pt] 2 \\[2pt] 1 \end{array}\right]. \] We can rewrite equalities (*) using the vectors $\mathbf{u}_1$ and $\mathbf{u}_2$ as follows \[ \tag{**} \mathbf{a}_1 = 3\, \mathbf{u}_1 = 3\, \mathbf{u}_1 + 0\, \mathbf{u}_2, \quad \mathbf{a}_2 = \frac{5}{3} \, 3\, \mathbf{u}_1 + \mathbf{u}_2 = 5\,\mathbf{u}_1 + \mathbf{u}_2. \] In matrix form the equalities (**) can be written as \[ A = Q \left[ \begin{array}{rr} 3 & 5 \\[2pt] 0 & 1 \end{array}\right], \] where \[ Q = \frac{1}{3} \left[ \begin{array}{rr} 1 & -2 \\[2pt] 2 & 2 \\[2pt] 2 & 1 \end{array}\right] \] is a matrix with orthonormal columns and its column space is identical to the columns space of the matrix $A$. Here \[ R = \left[ \begin{array}{rr} 3 & 5 \\[2pt] 0 & 1 \end{array}\right]. \] Notice that on the diagonal of the matrix $R$ are the norms of the vectors $\mathbf{v}_1$ and $\mathbf{v}_2$ which we obtained by the Gram-Schmidt orthogonalization algorithm. Since the matrix $Q$ has orthonormal columns we have $Q^\top Q = I_2$. Therefore the matrix $R$ can be calculated as \[ R = Q^\top A. \] This might be simpler than making adjustments to the coefficients of the Gram-Schmidt orthogonalization algorithm as we did in this simple example. However, it is good to know that $R$ is closely related to those coefficients.
- The next proof is optional. I did not do it in class. I believe that you can understand it and that you will benefit from understanding the following items.
-
Next, I want to prove that $QR$ factorization of a matrix $A$ with linearly independent columns is unique. Here is a proof.
In the next proof I am experimenting with a new way of presenting a theorem and its proof. Each theorem consists of assumptions and a claim. In the theorem below I label the assumptions by green labels with two capital letters. In this theorem they are BA, AQ, AR and QR. These are short abbreviations of the content of the assumptions. Here they are, respectively, Basic Assumptions, Assumptions about $Q$, Assumptions about $R$, $QR$ factorizations are assumed. I label the claim of the theorem by two or three capital letters in red. Here it is QRU (standing for $QR$ is Unique). The logic for selecting green and red is that the assumptions are a pleasant part of a theorem and the claim is an unpleasant part since we have to struggle intellectually to prove the claim. Although this intellectual challenge should be a pleasant task, there is a certain level of uncertainty associated with it.
A vital part of each proof are facts that we know from previously proved theorems. These facts give a proof its flow. Here I list all such facts and label them with green labels since they are known and useful for our task at hand. Here they are UP (Upper trianglular Product), UI (Upper trianglular Inverse).
I introduced a blue label for a comment. Here UTP introduces a notation for Upper Triangular matrices with Positive terms on diagonal.
What is a proof?
A proof is a procedure which uses previously stated (assumed or known) green labeled facts and logic to produce new green labeled facts. The goal of a proof is to produce a sequence of green labeled facts that will terminate with the (red labeled) claim of the theorem. In terms of the colors, the goal of a proof is to greenify the red claim of a theorem.Theorem
Assumptions
- BA. $A$ is an $n\!\times\!m$ real matrix with linearly independent columns.
- AQ. Assume $Q_1, Q_2$ are $n\!\times\!m$ real matrices such that \[ Q_1^{\top} Q_1 = I_m \quad \text{and} \quad Q_2^{\top} Q_2 = I_m \]
- AR. Assume $R_1, R_2$ are $m\!\times\!m$ real upper triangular matrices with positive entries on the diagonals.
- QR. Assume $A = Q_1 R_1$ and $A = Q_2 R_2$
- QRU. Then $Q_1 = Q_2$ and $R_1 = R_2$.
In the proof ot the theorem we use the following facts that have been established elsewhere.- UP. The product of two upper triangular matrices with positive entries on the diagonals is an upper triangular matrix with positive entries on the diagonal.
- UI. The inverse of an upper triangular matrix with positive entries on the diagonal is an upper triangular matrix with positive entries on the diagonal.
- UTP. UP and UI show that the set of upper triangular matrices with positive entries on the diagonals forms a multiplicative group. Basically it behaves as the set of positive real numbers with respect to multiplication. We will use the abbreviation a "UTP matrix" for an "upper triangular matrix with positive entries on the diagonal."
The proof starts here.- NR. By UI and AR the matrix $R_2$ is invertible and $R_2^{-1}$ is a UTP matrix. By UP the matrix $R= R_1 R_2^{-1}$ is a UTP matrix. In particular, $R$ is invertible.
- RQ1. By QR and NR we have \[ \tag{RQ} Q_1 R_1 R_2^{-1} = Q_1 R = Q_2. \] Multiplying (RQ) from the left by $Q_1^{\top}$ and using AQ we get \[ R = Q_1^{\top} Q_2. \]
- RQ2. Multiplying (RQ) from the left by $Q_2^{\top}$ and using AQ we get \[ Q_2^{\top} Q_1 R = I_m. \] Thus, \[ R^{-1} = Q_2^{\top} Q_1. \]
- RI. Notice that from RQ1 and RQ2 we have \[ R^{\top} = \bigl( Q_1^{\top} Q_2 \bigr)^{\top} = Q_2^{\top} Q_1 = R^{-1}. \] The equlity $R^{\top} = R^{-1}$ is vital to this proof: by the definition of the transpose and AR $R^T$ is a lover triangular matrix with the same positive diagonal entries as $R,$ while, by NR and UI, $R^{-1}$ is an upper triangular matrix with the diagonal entries which are reciprocals of the diagonal entries of $R.$ Consequently, $R^{\top} = R^{-1}$ yields that $R^{\top} = R^{-1}$ is a diagonal matrix whose entries on the diagonal are positive real numbers which equal their reciprocals. Since the only positive real number which equals its reciprocal is the number $1$, we conclude that all the diagonal entries of $R^{\top} = R^{-1}$ are $1$. Thus \[ R = I_m. \] QRU. By RI and NR \[ R_1R_2^{-1} = R = I_m. \] Thus $R_1 = R_2$. By equation (RQ) in RQ1 and RI we get \[ Q_1 = Q_2. \]
- QED. Since the red QRU has been turn into green QRU the proof has been completed.
- Find $QR$ factorizations of the following matrices \[ \left[ \begin{array}{ccc} -1 & -1 & 3 \\ 1 & 5 & -1 \\ 1 & 1 & 3 \\ -1 & -5 & 7 \end{array} \right] \quad \left[ \begin{array}{ccc} 6 & 8 & 7 \\ 3 & 6 & 0 \\ 2 & 2 & 0 \end{array} \right] \quad \left[ \begin{array}{ccc} 2 & 2 & 1 \\ 1 & 2 & 8 \\ 2 & 3 & 1 \end{array} \right] \quad \left[ \begin{array}{ccc} 4 & -1 & -7 \\ 2 & 8 & 7 \\ 2 & 4 & -8 \\ 1 & 5 & 5 \end{array} \right] \] \[ \left[ \begin{array}{ccc} 2 & -6 & 4 \\ -5 & 9 & 1 \\ 4 & 4 & 9 \\ 2 & -4 & 5 \end{array} \right] \]
- Suggested problems for Section 6.3 are: 1, 2, 4, 5, 7, 10, 11, 13, 15, 16 17, 19, 20, 21, 23
- There are two important theorems in Section 6.3: The Best Approximation Theorem (Theorem 9) (we will do it on Monday) and Theorem 10 which I would call Standard Matrix of an Orthogonal Projection (we did it yesterday).
- We did Section 6.2 and started Section 6.3 today. Suggested problems for Section 6.2 are: 2, 3, 5, 8, 9, 11, 13, 15, 17, 19, 21, 23, 25, 26, 27, 29. Suggested problems for Section 6.3 are: 1, 2, 4, 5, 7, 10, 11, 13, 15, 16 17, 19, 20, 21, 23.
-
The main question in these sections is the following: Given a subspace $\mathcal W$ of $\mathbb{R}^n$ and a vector $\mathbf{y} \in \mathbb{R}^n$ find a vector $\mathbf{w} \in \mathcal W$ such that the vector $\mathbf{z} =\mathbf{y} -\mathbf{w}$ is orthogonal to $\mathcal{W}$. In other words, for a given $\mathbf{y} \in \mathbb{R}^n$ we seek $\mathbf{w} \in \mathcal W$ and $\mathbf{z} \in \mathcal W^\perp$ such that
\[
\mathbf{y} = \mathbf{w} + \mathbf{z}.
\]
Three important observations about this setting:
- Vectors $\mathbf{w}$ and $\mathbf{z}$ with desired properties are uniquely determined. The proof goes as follows: Assume that \[ \mathbf{y} = \mathbf{w}_1 + \mathbf{z}_1 \quad \text{and} \quad \mathbf{y} = \mathbf{w}_2 + \mathbf{z}_2 \] with \[ \mathbf{w}_1,\mathbf{w}_2 \in \mathcal W \quad \text{and} \quad \mathbf{z}_1, \mathbf{z}_2 \in \mathcal W^\perp. \] Subtracting the preceding two equalities we get \[ \mathbf{0} = \mathbf{w}_1 - \mathbf{w}_2 + \mathbf{z}_1 - \mathbf{z}_2. \] Since $\mathcal{W}$ and $\mathcal{W}^\perp$ are subspaces we have \[ \mathbf{w}_1 - \mathbf{w}_2 \in \mathcal W \quad \text{and} \quad \mathbf{z}_1 - \mathbf{z}_2 \in \mathcal W^\perp. \] Now dot product both sides of the last equality with the vector $\mathbf{w}_1 - \mathbf{w}_2$: \[ \mathbf{0} \cdot (\mathbf{w}_1 - \mathbf{w}_2) = (\mathbf{w}_1 - \mathbf{w}_2)\cdot (\mathbf{w}_1 - \mathbf{w}_2) + (\mathbf{z}_1 - \mathbf{z}_2)\cdot (\mathbf{w}_1 - \mathbf{w}_2). \] Since $\mathbf{w}_1 - \mathbf{w}_2$ and $\mathbf{z}_1 - \mathbf{z}_2$ are orthogonal vectors, the last equality simplifies to \[ (\mathbf{w}_1 - \mathbf{w}_2)\cdot (\mathbf{w}_1 - \mathbf{w}_2) = \| \mathbf{w}_1 - \mathbf{w}_2 \|^2 = 0. \] Since the only vector whose norm is $0$ is the zero vector $\mathbf{0}$ we conclude that \[ \mathbf{w}_1 = \mathbf{w}_2. \] Since we already know that \[ \mathbf{0} = \mathbf{w}_1 - \mathbf{w}_2 + \mathbf{z}_1 - \mathbf{z}_2. \] we deduce that \[ \mathbf{z}_1 = \mathbf{z}_2. \]
-
Definition Let $\mathcal{W}$ be a subspace of $\mathbb{R}^n$ and let $\mathbf{y} \in \mathbb{R}^n.$ The vector $\mathbf{w} \in \mathbb{R}^n$ is called the orthogonal projection of $\mathbf{y}$ onto $\mathcal{W}$ if $\mathbf{w}$ has the following two properties:
- $\mathbf{w} \in \mathcal{W},$
- $\mathbf{y} - \mathbf{w} \in \mathcal{W}^{\perp}.$
- Next I want to list three magic properties of the orthogonal sets of vectors. But, first the definition.
-
Definition A set of vectors $\{ \mathbf u_1, \ldots, \mathbf u_m \}$ in $\mathbb{R}^n$ is said to be an orthogonal set of vectors if it has the following two properties:
- For all $j,k \in \{1,\ldots,m\}$ such that $j\neq k$ we have $\mathbf u_j \cdot \mathbf u_k = 0$.
- For all $k \in \{1,\ldots,m\}$ we have $\mathbf u_k \cdot \mathbf u_k \gt 0$. (This in fact means that all the vectors in this set are nonzero vectors.)
-
Here we state three magic properties of orthogonal sets of vectors. Assume that $\{ \mathbf u_1, \ldots, \mathbf u_m \}$ is an orthogonal set of vectors in $\mathbb{R}^n.$
- The set $\{ \mathbf{u}_1, \ldots, \mathbf{u}_m \}$ is linearly independent.
- If $\mathbf{b} \in \operatorname{span} \{ \mathbf u_1, \ldots, \mathbf u_m \}$, then the solution of the vector equation \[ x_1 \mathbf{u}_1 + \cdots + x_m \mathbf{u}_m = \mathbf{b} \] is given by \[ \forall \mkern+1mu k\in \{1,\ldots,m\} \quad x_k = \frac{\mathbf{b}\cdot \mathbf{u}_k}{\mathbf{u}_k\cdot \mathbf{u}_k}. \] (This property I call "easy solving of a vector equation.")
- Let $\mathbf{y} \in \mathbb{R}^n$ and let \[ \mathcal W = \operatorname{span} \{ \mathbf u_1, \ldots, \mathbf u_m \}. \] Then \[ \operatorname{Proj}_{\mathcal W} \mathbf{y} = \frac{\mathbf{u}_1\!\cdot\!\mathbf{y}}{\mathbf{u}_1\!\cdot\!\mathbf{u}_1} \mathbf{u}_1 + \frac{\mathbf{u}_2\!\cdot\!\mathbf{y}}{\mathbf{u}_2\!\cdot\!\mathbf{u}_2} \mathbf{u}_2 + \cdots + \frac{\mathbf{u}_m\!\cdot\!\mathbf{y}}{\mathbf{u}_m\!\cdot\!\mathbf{u}_m} \mathbf{u}_m \] (This property I call "easy orthogonal projection.")
- I will prove the third magic property. Set \[ \mathbf{w} = \frac{\mathbf{u}_1\!\cdot\!\mathbf{y}}{\mathbf{u}_1\!\cdot\!\mathbf{u}_1} \mathbf{u}_1 + \frac{\mathbf{u}_2\!\cdot\!\mathbf{y}}{\mathbf{u}_2\!\cdot\!\mathbf{u}_2} \mathbf{u}_2 + \cdots + \frac{\mathbf{u}_m\!\cdot\!\mathbf{y}}{\mathbf{u}_m\!\cdot\!\mathbf{u}_m} \mathbf{u}_m. \] To prove that $\mathbf{w} = \operatorname{Proj}_{\mathcal W} \mathbf{y}$ we have to prove two properties for $\mathbf{w}$: \[ \mathbf{w} \in \mathcal{W} \qquad \text{and} \qquad (\mathbf{y} - \mathbf{w}) \perp \mathcal{W}. \] Since $\mathcal W$ is the span of the vectors $\mathbf u_1, \ldots, \mathbf u_m$ and $\mathbf{w}$ is a linear combination of the vectors $\mathbf u_1, \ldots, \mathbf u_m$ we have that $\mathbf{w} \in \mathcal{W}.$ To prove \[ (\mathbf{y} - \mathbf{w}) \perp \mathcal{W} \] we recall the equivalence \[ (\mathbf{y} - \mathbf{w}) \perp \mathcal{W} \qquad \Leftrightarrow \qquad \forall\mkern+1mu k\in\{1,\ldots,m\} \quad (\mathbf{y} - \mathbf{w})\cdot \mathbf{u}_k = 0. \] The proof of the right-hand side in the preceding equivalence follows. Let $k\in\{1,\ldots,m\}$ be arbitrary. We calculate \begin{align*} (\mathbf{y} - \mathbf{w})\cdot \mathbf{u}_k & = \mathbf{y}\cdot \mathbf{u}_k - \mathbf{w}\cdot \mathbf{u}_k \\ &= \mathbf{y}\cdot \mathbf{u}_k - \left( \sum_{j=1}^m \frac{\mathbf{u}_j\!\cdot\!\mathbf{y}}{\mathbf{u}_j\!\cdot\!\mathbf{u}_j} \mathbf{u}_1 \right)\cdot \mathbf{u}_k \\ & = \mathbf{y}\cdot \mathbf{u}_k - \sum_{j=1}^m \frac{\mathbf{u}_j\!\cdot\!\mathbf{y}}{\mathbf{u}_j\!\cdot\!\mathbf{u}_j} (\mathbf{u}_j\cdot \mathbf{u}_k) \\ & = \mathbf{y}\cdot \mathbf{u}_k - \mathbf{u}_k \cdot \mathbf{y} \\ & = 0. \end{align*}
- The above three magic properties become more transparent if we introduce matrix notation. Assume that $\{ \mathbf u_1, \ldots, \mathbf u_m \}$ is an orthogonal set of vectors in $\mathbb{R}^n$ and set \[ U = \bigl[\!\begin{array}{cccc} \mathbf{u}_1 & \mathbf{u}_2 & \cdots & \mathbf{u}_m \end{array}\!\!\bigr]. \] Notice that $U$ is an $n\!\times\!m$ matrix with orthogonal columns. Since by the first magic property the columns of $U$ are linearly independent we have $m\leq n$. (I call such matrices tall; their transposes I call wide.) Based on the matrix multiplication structure developed in the post on Tuesday we have \begin{align*} U^\top U & = \left[\!\begin{array}{c} \mathbf{u}_1^\top \\ \mathbf{u}_2^\top \\ \vdots \\ \mathbf{u}_m^\top \end{array}\!\!\right] \left[\!\begin{array}{cccc} \mathbf{u}_1 & \mathbf{u}_2 & \cdots & \mathbf{u}_m \end{array}\!\right] \\[10pt] &= \left[\!\begin{array}{cccc} \mathbf{u}_1\!\!\cdot\!\mathbf{u}_1 & \mathbf{u}_1\!\!\cdot\!\mathbf{u}_2 & \cdots & \mathbf{u}_1\!\!\cdot\!\mathbf{u}_m \\ \mathbf{u}_2\!\!\cdot\!\mathbf{u}_1 & \mathbf{u}_2\!\!\cdot\!\mathbf{u}_2 & \cdots & \mathbf{u}_2\!\!\cdot\!\mathbf{u}_m \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{u}_m\!\!\cdot\!\mathbf{u}_1 & \mathbf{u}_m\!\!\cdot\!\mathbf{u}_2 & \cdots & \mathbf{u}_m\!\!\cdot\!\mathbf{u}_m \end{array}\!\!\right] \\[10pt] &= \left[\!\begin{array}{cccc} \mathbf{u}_1\!\!\cdot\!\mathbf{u}_1 & 0 & \cdots & 0 \\ 0 & \mathbf{u}_2\!\!\cdot\!\mathbf{u}_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \mathbf{u}_m\!\!\cdot\!\mathbf{u}_m \end{array}\!\!\right]. \end{align*} Magic again, $U^TU$ is an $m\!\times\!m$ diagonal matrix with positive entries on the diagonal. Therefore, $U^TU$ is invertible and its inverse is the following diagonal matrix \[ \bigl(U^\top U \bigr)^{-1} = \left[\!\begin{array}{cccc} (\mathbf{u}_1\!\!\cdot\!\mathbf{u}_1)^{-1} & 0 & \cdots & 0 \\ 0 & (\mathbf{u}_2\!\!\cdot\!\mathbf{u}_2)^{-1} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & (\mathbf{u}_m\!\!\cdot\!\mathbf{u}_m)^{-1} \end{array}\!\!\right]. \]
- To prove the first two magic properties listed above we need to solve the matrix equation \[ U \mathbf{x} = \mathbf{b}, \] where $\mathbf{b} \in \mathbb{R}^n$ and $\mathbf{x} = \bigl[x_1 \ \cdots \ x_m\bigr]^\top \in \mathbf{R}^m.$ To solve this matrix equation apply $U^\top$ to both sides and we get \[ U^\top U \mathbf{x} = U^\top \mathbf{b}. \] Since $U^\top U$ is an invertible matrix the solution is \[ \mathbf{x} = \bigl(U^\top U\bigr)^{-1} U^\top \mathbf{b}. \] To get an explicit formula for the entries of $\mathbf{x}$ we calculate \[ U^\top \mathbf{b} = \left[\!\begin{array}{c} \mathbf{u}_1^\top \\ \mathbf{u}_2^\top \\ \vdots \\ \mathbf{u}_m^\top \end{array}\!\!\right] \mathbf{b} = \left[\! \begin{array}{c} \mathbf{u}_1\!\!\cdot\!\mathbf{b} \\ \mathbf{u}_2\!\!\cdot\!\mathbf{b} \\ \vdots \\ \mathbf{u}_m\!\!\cdot\!\mathbf{b} \end{array} \!\right] \] and consequently \[ \mathbf{x} = \bigl(U^\top U\bigr)^{-1} U^\top \mathbf{b} = \left[\!\begin{array}{cccc} (\mathbf{u}_1\!\!\cdot\!\mathbf{u}_1)^{-1} & 0 & \cdots & 0 \\ 0 & (\mathbf{u}_2\!\!\cdot\!\mathbf{u}_2)^{-1} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & (\mathbf{u}_m\!\!\cdot\!\mathbf{u}_m)^{-1} \end{array}\!\!\right] \left[\! \begin{array}{c} \mathbf{u}_1\!\!\cdot\!\mathbf{b} \\ \mathbf{u}_2\!\!\cdot\!\mathbf{b} \\ \vdots \\ \mathbf{u}_m\!\!\cdot\!\mathbf{b} \end{array} \!\right] = \left[\! \begin{array}{c} \frac{\mathbf{u}_1\cdot \mathbf{b}}{\mathbf{u}_1 \cdot \mathbf{u}_1} \\ \frac{\mathbf{u}_2 \cdot \mathbf{b}}{\mathbf{u}_2 \cdot \mathbf{u}_2} \\ \vdots \\ \frac{\mathbf{u}_m \cdot \mathbf{b}}{\mathbf{u}_m \cdot \mathbf{u}_m} \end{array} \!\right]. \]
- To prove the third magic property of the orthogonal set $\{ \mathbf u_1, \ldots, \mathbf u_m \}$ we assume $\mathbf{y} \in \mathbb{R}^n$ and based on the preceding displayed equality we have \[ \bigl(U^\top U\bigr)^{-1} U^\top \mathbf{y} = \left[\!\begin{array}{cccc} (\mathbf{u}_1\!\!\cdot\!\mathbf{u}_1)^{-1} & 0 & \cdots & 0 \\ 0 & (\mathbf{u}_2\!\!\cdot\!\mathbf{u}_2)^{-1} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & (\mathbf{u}_m\!\!\cdot\!\mathbf{u}_m)^{-1} \end{array}\!\!\right] \left[\! \begin{array}{c} \mathbf{u}_1\!\!\cdot\!\mathbf{y} \\ \mathbf{u}_2\!\!\cdot\!\mathbf{y} \\ \vdots \\ \mathbf{u}_m\!\!\cdot\!\mathbf{y} \end{array} \!\right] = \left[\! \begin{array}{c} \frac{\mathbf{u}_1\cdot \mathbf{y}}{\mathbf{u}_1 \cdot \mathbf{u}_1} \\ \frac{\mathbf{u}_2 \cdot \mathbf{y}}{\mathbf{u}_2 \cdot \mathbf{u}_2} \\ \vdots \\ \frac{\mathbf{u}_m \cdot \mathbf{y}}{\mathbf{u}_m \cdot \mathbf{u}_m} \end{array} \!\right]. \] Now applying $U$ to both sides of this equality we get \[ U \bigl(U^\top U\bigr)^{-1} U^\top \mathbf{y} = \bigl[\!\begin{array}{cccc} \mathbf{u}_1 & \mathbf{u}_2 & \cdots & \mathbf{u}_m \end{array}\!\!\bigr] \left[\! \begin{array}{c} \frac{\mathbf{u}_1\cdot \mathbf{y}}{\mathbf{u}_1 \cdot \mathbf{u}_1} \\ \frac{\mathbf{u}_2 \cdot \mathbf{y}}{\mathbf{u}_2 \cdot \mathbf{u}_2} \\ \vdots \\ \frac{\mathbf{u}_m \cdot \mathbf{y}}{\mathbf{u}_m \cdot \mathbf{u}_m} \end{array} \!\right] = \frac{\mathbf{u}_1\!\cdot\!\mathbf{y}}{\mathbf{u}_1\!\cdot\!\mathbf{u}_1} \mathbf{u}_1 + \frac{\mathbf{u}_2\!\cdot\!\mathbf{y}}{\mathbf{u}_2\!\cdot\!\mathbf{u}_2} \mathbf{u}_2 + \cdots + \frac{\mathbf{u}_m\!\cdot\!\mathbf{y}}{\mathbf{u}_m\!\cdot\!\mathbf{u}_m} \mathbf{u}_m. \] Notice that the right-hand side of the last equality is exactly the proposed expression for $\displaystyle \operatorname{Proj}_{\mathcal W} \mathbf{y}.$ Based on the last equalities, to prove the third magic property we need to prove two things \[ U \bigl(U^\top U\bigr)^{-1} U^\top \mathbf{y} \in \mathcal{W} \quad \text{and} \quad \bigl( \mathbf{y} - U \bigl(U^\top U\bigr)^{-1} U^\top \mathbf{y} \bigr) \perp \mathcal{W}. \] To prove these properties we notice that $\mathcal{W} = \operatorname{Col}(U)$ and $\mathbf{v} \in \operatorname{Col}(U)$ if and only if there exists $\mathbf{x} \in \mathbb{R}^m$ such that $\mathbf{v} = U\mathbf{x}.$
- We started Section 6.1 today. Suggested problems: 1, 5, 7, 8, 9-12, 13, 15-18, 20, 22, 24, 25, 26, 27, 28, 29, 30, 31, 32 (do this problem by hand), 33 (do this problem by hand).
- Here is a proof of the Law of Cosines and its connection to dot product.
- Here is a proof of the classical Pythagorean Theorem.
- I emphasized this after class during the office hour. It is important for you to internalize that we have been working with the dot product all along when multiplying matrices. Let $k,m$ and $n$ be positive integers and let $A$ be a $k\!\times\!m$ matrix and $B$ be a $m\!\times\!n$. Then $A$ has $k$ rows and each row of $A$ is a transpose of a vector in $\mathbb{R}^m$. Similarly, $B$ has $n$ columns and each column of $B$ is a vector in $\mathbb{R}^m$. Now introduce the notation: \[ \mathbf{r}_1, \mathbf{r}_2, \ldots, \mathbf{r}_k \in \mathbb{R}^m \quad \text{are the transposes of the rows of} \quad A \] \[ \mathbf{c}_1, \mathbf{c}_2, \ldots, \mathbf{c}_n \in \mathbb{R}^m \quad \text{are the columns of} \quad B \] So, I can write the matrices $A$ and $B$ as \[ A = \left[\!\begin{array}{c} \mathbf{r}_1^\top \\ \mathbf{r}_2^\top \\ \vdots \\ \mathbf{r}_k^\top \end{array}\!\!\right], \qquad B = \left[\!\begin{array}{cccc} \mathbf{c}_1 & \mathbf{c}_2 & \cdots & \mathbf{c}_n \end{array}\!\!\right]. \] Now we calculate the product of $A$ and $B$ as follows: \[ A B = \left[\!\begin{array}{c} \mathbf{r}_1^\top \\ \mathbf{r}_2^\top \\ \vdots \\ \mathbf{r}_k^\top \end{array}\!\!\right] \left[\!\begin{array}{cccc} \mathbf{c}_1 & \mathbf{c}_2 & \cdots & \mathbf{c}_n \end{array}\!\!\right] = \left[\!\begin{array}{cccc} \mathbf{r}_1\!\!\cdot\!\mathbf{c}_1 & \mathbf{r}_1\!\!\cdot\!\mathbf{c}_2 & \cdots & \mathbf{r}_1\!\!\cdot\!\mathbf{c}_n \\ \mathbf{r}_2\!\!\cdot\!\mathbf{c}_1 & \mathbf{r}_2\!\!\cdot\!\mathbf{c}_2 & \cdots & \mathbf{r}_2\!\!\cdot\!\mathbf{c}_n \\ \vdots & \vdots & \ddots & \vdots \\ \mathbf{r}_k\!\!\cdot\!\mathbf{c}_1 & \mathbf{r}_k\!\!\cdot\!\mathbf{c}_2 & \cdots & \mathbf{r}_k\!\!\cdot\!\mathbf{c}_n \end{array}\!\!\right] \]
- As an example, I will recall two important matrices that we multiplied on January 14 in a teal box: \[ \require{bbox} \bbox[#7FBFBF, 8px, border: 3px solid teal]{ \left[\! \begin{array}{rrr} 1 & 3 & 2 \\ 2 & 0 & 1 \\ 2 & 1 & 1 \\ 1 & 4 & 2 \end{array} \!\right] \left[\! \begin{array}{rrrrr} 1 & 0 & -1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 1 \\ 0 & 0 & 0 & 1 & -1 \\ \end{array} \!\right] = \left[\! \begin{array}{rrrrr} 1 & 3 & 2 & 2 & 2 \\ 2 & 0 & -2 & 1 & 1 \\ 2 & 1 & -1 & 1 & 2 \\ 1 & 4 & 3 & 2 & 3 \end{array} \!\right] }. \] Here $A$ is a $4\times\!3$ matrix with the rows: \[ \left[\! \begin{array}{r} 1 \\ 3 \\ 2 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 2 \\ 0 \\ 1 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 2 \\ 1 \\ 1 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 1 \\ 4 \\ 2 \end{array} \!\right], \] and $B$ is a $3\times\!5$ matrix with the columns: \[ \left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right], \qquad \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right]. \] It is useful to think of the multiplication as follows (as you read through the matrix-vector arithmetic below always look for dot products in different forms, always): \begin{align*} & \left[\! \begin{array}{r} \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr] \\ \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr] \\ \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr] \\ \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr] \end{array} \!\right] \left[\! \begin{array}{rrrrr} \left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \end{array} \!\right] \\ & = \left[\! \begin{array}{rrrrr} \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \end{array} \!\right] \\ & = \left[\! \begin{array}{ccccc} 1\!\cdot\!1 + 3\!\cdot\!0 + 2\!\cdot\!0 & 1\!\cdot\!0 + 3\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!(-1) + 3\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!0 + 3\!\cdot\!0 + 2\!\cdot\!1 & 1\!\cdot\!1 + 3\!\cdot\!1 + 2\!\cdot\!(-1) \\ 2\!\cdot\!1 + 0\!\cdot\!0 + 1\!\cdot\!0 & 2\!\cdot\!0 + 0\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!(-1) + 0\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!0 + 0\!\cdot\!0 + 1\!\cdot\!1 & 2\!\cdot\!1 + 0\!\cdot\!1 + 1\!\cdot\!(-1) \\ 2\!\cdot\!1 + 1\!\cdot\!0 + 1\!\cdot\!0 & 2\!\cdot\!0 + 1\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!(-1) + 1\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!0 + 1\!\cdot\!0 + 1\!\cdot\!1 & 2\!\cdot\!1 + 1\!\cdot\!1 + 1\!\cdot\!(-1) \\ 1\!\cdot\!1 + 4\!\cdot\!0 + 2\!\cdot\!0 & 1\!\cdot\!0 + 4\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!(-1) + 4\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!0 + 4\!\cdot\!0 + 2\!\cdot\!1 & 1\!\cdot\!1 + 4\!\cdot\!1 + 2\!\cdot\!(-1) \end{array} \!\right] \\ &= \left[\! \begin{array}{rrrrr} 1 & 3 & 2 & 2 & 2 \\ 2 & 0 & -2 & 1 & 1 \\ 2 & 1 & -1 & 1 & 2 \\ 1 & 4 & 3 & 2 & 3 \end{array} \!\right] \end{align*}
- Today we did Section 5.5. Suggested problems for Section 5.5: 1-6, 7-12, 13, 16, 17, 18, 21, 25, 26.
- A brief summary of Section 5.5 is as follows. Let $A$ be a real $n\!\times\!n$ matrix. Assume that $A$ has a complex eigenvalue $\lambda = a - i b$, where $a,b \in \mathbb{R}$ with $b\neq0$, and that a corresponding eigenvector is \[ \mathbf{w} = \mathbf{u} + i \mathbf{v} \quad \text{where} \quad \mathbf{u}, \mathbf{v} \in \mathbb{R}^2. \] That is we assume \[ A \mathbf{w} = \lambda \mathbf{w}, \quad \mathbf{w} \neq \mathbf{0}, \quad \operatorname{Im}(\lambda) = -b \neq 0. \] Recall that for $\alpha \in \mathbb{C}$ by $\overline{\alpha}$ we denote the complex conjugate of $\alpha;$ that is $\overline{\alpha}$ is the complex number such that $\operatorname{Re}(\overline{\alpha}) = \operatorname{Re}(\alpha)$ and $\operatorname{Im}(\overline{\alpha}) = -\operatorname{Im}(\alpha).$ A complex number $\alpha$ is real if and only if $\overline{\alpha} = \alpha.$ The algebraic properties of complex conjugation are as follows: for all $\alpha, \beta \mathbb{C}$ we have \[ \overline{\alpha+\beta} = \overline{\alpha} + \overline{\beta}, \quad \overline{\alpha\,\beta} = \overline{\alpha}\, \overline{\beta}. \] By $\overline{\mathbf{w}}$ we denote the vector whose entries are the complex conjugates of the entries of $\mathbf{w};$ that is $\overline{\mathbf{w}} = \mathbf{u} - i \mathbf{v}.$ Since the matrix $A$ is real we have $\overline{A} = A.$ Since $A \mathbf{w} = \lambda \mathbf{w}$ we have $\overline{A \mathbf{w}} = \overline{\lambda \mathbf{w}}.$ By algebraic properties of the complex conjugation we have \[ \overline{A \mathbf{w}} = \overline{A} \overline{\mathbf{w}} \quad \text{and} \quad \overline{\lambda \mathbf{w}} = \overline{\lambda} \overline{\mathbf{w}}. \] Therefore \[ A \overline{\mathbf{w}} = \overline{\lambda} \overline{\mathbf{w}}. \] This equality shows that $\overline{\lambda}$ is also an eigenvalue of $A$ and a corresponding eigenvector is $\overline{\mathbf{w}}.$
- Next we will show that the vectors $\mathbf{w}$ and $\overline{\mathbf{w}}$ are linearly independent. Let $\alpha, \beta \in\mathbb{C}$ and assume that \[ \alpha \mathbf{w} + \beta \overline{\mathbf{w}} = \mathbf{0}. \] Notice that \[ (A-\lambda I_n)\mathbf{w} = \mathbf{0} \quad \text{and} \quad (A-\lambda I_n)\overline{\mathbf{w}} = (\overline{\lambda} - \lambda) \overline{\mathbf{w}} \] and apply $A-\lambda I_n$ to both sides of the assumed linear combination equaling $\mathbf{0}$ to obtain \[ \beta (\overline{\lambda} - \lambda) \overline{\mathbf{w}} = \mathbf{0}. \] Since $\overline{\lambda} - \lambda = 2b i \neq 0$ and $\overline{\mathbf{w}} \neq \mathbf{0}$, we deduce that $\beta =0.$ Substituting $\beta = 0$ in $\alpha \mathbf{w} + \beta \overline{\mathbf{w}} = \mathbf{0}$ we get $\alpha \mathbf{w} = \mathbf{0},$ which implies $\alpha = 0,$ as $\mathbf{w} \neq \mathbf{0}$ being an eigenvector.
- Next we will prove that the vectors $\mathbf{u} = \operatorname{Re} \mathbf{w}$ and $\mathbf{v} = \operatorname{Im} \mathbf{w}$ are linearly independent. First observe that \[ \frac{1}{2} ( \mathbf{w} + \overline{\mathbf{w}} ) = \frac{1}{2}( \mathbf{u} + i \mathbf{v} + \mathbf{u} - i \mathbf{v}) = \mathbf{u}, \] and \[ \frac{1}{2i} ( \mathbf{w} - \overline{\mathbf{w}} ) = \frac{1}{2i}( \mathbf{u} + i \mathbf{v} - \mathbf{u} + i \mathbf{v}) = \mathbf{v}. \] To prove the linear independence of $\mathbf{u}$ and $\mathbf{v}$, let $\alpha, \beta \in\mathbb{C}$ and assume that \[ \alpha \mathbf{u} + \beta \overline{\mathbf{v}} = \mathbf{0}. \] Expressing $\mathbf{u}$ and $\mathbf{v}$ in terms of $\mathbf{w}$ and $\overline{\mathbf{w}}$ we get \[ \frac{\alpha}{2} (\mathbf{w} + \overline{\mathbf{w}}) + \frac{\beta}{2i} (\mathbf{w} - \overline{\mathbf{w}}) = \mathbf{0}. \] Simplifying the left hand side we get \[ \left( \frac{\alpha}{2} + \frac{\beta}{2i} \right) \mathbf{w} + \left( \frac{\alpha}{2} - \frac{\beta}{2i} \right) \overline{\mathbf{w}} = \mathbf{0}. \] Since the vectors $\mathbf{w}$ and $\overline{\mathbf{w}}$ are linearly independent, we deduce \[ \frac{\alpha}{2} + \frac{\beta}{2i} = 0, \quad \frac{\alpha}{2} - \frac{\beta}{2i} = 0. \] This is a system of linear equations with unknowns $\alpha$ and $\beta$ which can be written as a matrix equation (notice $1/i = -i$) \[ \frac{1}{2} \left[\! \begin{array}{cc} 1 & -i \\ 1 & i \end{array} \!\right] \left[\! \begin{array}{c} \alpha \\ \beta \end{array} \!\right] = \left[\! \begin{array}{c} 0 \\ 0 \end{array} \!\right]. \] Since the determinant of the preceding matrix is $2i \neq 0$ we deduce that $\alpha =0$ and $\beta = 0,$ proving that the vectors $\mathbf{u}$ and $\mathbf{v}$ are linearly independent.
- Now we go back to the fact that $\lambda = a -i b$ and $\mathbf{w} = \mathbf{u} + i \mathbf{v}$ are an eigenvalue and a corresponding eigenvector of the real matrix $A$: \[ A (\mathbf{u} + i \mathbf{v}) = (a-i b) (\mathbf{u} + i \mathbf{v}). \] Using the linearity of the matrix-vector multiplication and algebra with vectors we can rewrite the preceding equality as \[ A \mathbf{u} + i A \mathbf{v} = (a \mathbf{u} + b \mathbf{v}) + i (- b \mathbf{u} + a \mathbf{v}). \] Since the vectors $A \mathbf{u}$, $A \mathbf{v}$ and $a \mathbf{u} + b \mathbf{v}$, $- b \mathbf{u} + a \mathbf{v}$ are vectors with real entries the preceding equality implies that \begin{align*} A \mathbf{u} & = a \mathbf{u} + b \mathbf{v} \\ A \mathbf{v} & = - b \mathbf{u} + a \mathbf{v} . \end{align*} The last two vector equalities can be rewritten as one matrix equality \[ A \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] = \bigl[ A\mathbf{u} \ \ A\mathbf{v} \bigr] = \bigl[ a \mathbf{u} + b \mathbf{v} \ \ \ - b \mathbf{u} + a \mathbf{v} \bigr]. \] The last matrix can be factored as \[ \bigl[ a \mathbf{u} + b \mathbf{v} \ \ \ - b \mathbf{u} + a \mathbf{v} \bigr] = \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right]. \] Finally, the last two equalities yield \[ A \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] = \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right]. \] Notice that the matrices in the preceding equality are $n\!\times\!2$ matrices.
- Now assume that $A$ is a real $2\!\times\!2$ matrix. In this case, since the real vectors $\mathbf{u}$ and $\mathbf{v}$ are linearly independent, the $2\!\times\!2$ matrix $\bigl[ \mathbf{u} \ \ \mathbf{v} \bigr]$ is invertible. Therefore, the equality \[ A \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] = \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right] \] can be rewritten as \[ A = \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr] \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right] \bigl[ \mathbf{u} \ \ \mathbf{v} \bigr]^{-1}. \] The matrix \[ \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right] \] is a composition of a scaling and a rotation. To see that factor \[ \sqrt{a^2+b^2} \left[\! \begin{array}{rr} \frac{a}{\sqrt{a^2+b^2}} & -\frac{b}{\sqrt{a^2+b^2}} \\ \frac{b}{\sqrt{a^2+b^2}} & \frac{a}{\sqrt{a^2+b^2}} \end{array} \!\right]. \] Since \[ \left( \frac{a}{\sqrt{a^2+b^2}} \right)^2 + \left( \frac{b}{\sqrt{a^2+b^2}} \right)^2 = 1, \] there exists an angle $\theta \in (-\pi,\pi]$ such that \[ \cos \theta = \frac{a}{\sqrt{a^2+b^2}}, \quad \text{and} \quad \sin \theta = \frac{b}{\sqrt{a^2+b^2}} . \] Thus, with $\alpha = \sqrt{a^2+b^2}$ we have \[ \left[\! \begin{array}{rr} a & -b \\ b & a \end{array} \!\right] = \alpha \left[\! \begin{array}{rr} \cos\theta & -\sin \theta \\ \sin\theta & \cos\theta \end{array} \!\right]. \]
-
The above considerations are summarized in the following theorem which is called the Hidden Rotation-Dilation Theorem:
- Here is an example of the above procedure. Consider the matrix \[ \left[\! \begin{array}{rr} 1 & -3 \\ 6 & 7 \end{array} \!\right]. \] The eigenvalues of this matrix are \[ 4 - 3i \qquad \text{and} \qquad 4+3i. \] The corresponding eigenvectors are \[ \left[\! \begin{array}{r} 1 \\ -1 \end{array} \!\right] + i \left[\! \begin{array}{r} 0 \\ 1 \end{array} \!\right] \qquad \text{and} \qquad \left[\! \begin{array}{r} 1 \\ -1 \end{array} \!\right] - i \left[\! \begin{array}{r} 0 \\ 1 \end{array} \!\right] \] One of the identity for the matrix $\left[\! \begin{array}{rr} 1 & -3 \\ 6 & 7 \end{array} \!\right]$ that we established in the previous item is \[ \left[\! \begin{array}{rr} 1 & -3 \\ 6 & 7 \end{array} \!\right] \left[\! \begin{array}{rr} 1 & 0 \\ -1 & 1 \end{array} \!\right] = \left[\! \begin{array}{rr} 1 & 0 \\ -1 & 1 \end{array} \!\right] \left[\! \begin{array}{rr} 4 & -3 \\ 3 & 4 \end{array} \!\right]. \] Since $\sqrt{4^2+3^2} = 5$ we have \[ \left[\! \begin{array}{rr} 4 & -3 \\ 3 & 4 \end{array} \!\right] = 5 \left[\! \begin{array}{rr} \frac{4}{5} & -\frac{3}{5} \\ \frac{3}{5} & \frac{4}{5} \end{array} \!\right] = 5 \left[\! \begin{array}{rr} \cos\theta & -\sin \theta \\ \sin\theta & \cos\theta \end{array} \!\right], \quad \text{where} \quad \theta = \arccos \frac{4}{5} \approx 0.643501. \] Thus \[ \left[\! \begin{array}{rr} 1 & -3 \\ 6 & 7 \end{array} \!\right] = 5 \left[\! \begin{array}{rr} 1 & 0 \\ -1 & 1 \end{array} \!\right] \left[\! \begin{array}{rr} \frac{4}{5} & -\frac{3}{5} \\ \frac{3}{5} & \frac{4}{5} \end{array} \!\right] \left[\! \begin{array}{rr} 1 & 0 \\ 1 & 1 \end{array} \!\right] \]
- Here is another example of the above procedure. Consider the matrix \[ \left[\! \begin{array}{rr} -1 & 2 \\ -1 & 1 \end{array} \!\right]. \] For this matrix it is interesting to calculate its square \[ \left[\! \begin{array}{rr} -1 & 2 \\ -1 & 1 \end{array} \!\right] \left[\! \begin{array}{rr} -1 & 2 \\ -1 & 1 \end{array} \!\right] = \left[\! \begin{array}{rr} -1 & 0 \\ 0 & -1 \end{array} \!\right] \] and then \[ \left[\! \begin{array}{rr} -1 & 2 \\ -1 & 1 \end{array} \!\right]^4 = \left[\! \begin{array}{rr} -1 & 0 \\ 0 & -1 \end{array} \!\right] \left[\! \begin{array}{rr} -1 & 0 \\ 0 & -1 \end{array} \!\right] = \left[\! \begin{array}{rr} 1 & 0 \\ 0 & 1 \end{array} \!\right]. \] Explain why the fourth power of the given matrix is the identity matrix by using the method presented in this post.
- Today we started Section 5.5. We started with a review of Complex Numbers. This is discussed in Appendix B in the book. I wrote my own introduction to complex numbers. In this introduction I offer an explanation for Euler's identity without using infinite series. Instead, I use differentiation rules.
- Over the years of teaching and thinking about mathematics I developed an appreciation for reasoning from first principles. What this means in practice is that I will not consider a proof optimal if it uses "well-known" but, in undergraduate math, rarely proved theorems. I am trying to write a proof of Euler's Identity which will use only the definition of a limit of a sequence and algebra of complex numbers and everything else that is needed will be included in my notes. Here is my current version of a proof of Euler's Identity from first principles. It is missing two short proofs, which I will add soon.
- Today we started Section 5.4. Suggested problems are: 1, 3 - 13, 17, 19 - 23, 27, 28.
- The content of Section 5.4 can be used to provide an alternative way to obtain the matrix of a reflection in the picture below.
-
In the picture below we show the reflection across the green line. The unit vector along the green line and a vector orthogonal to it are colored teal:
\[
\color{teal}{\mathbf{u}_1} = \color{teal}{\left[\!
\begin{array}{c}
\cos \theta \\
\sin \theta
\end{array}
\!\right]},
\
\color{teal}{\mathbf{u}_2} = \color{teal}{\left[\!
\begin{array}{r}
- \sin \theta \\
\cos \theta
\end{array}
\!\right]}.
\]
In the picture below we denote the reflection of a vector $\color{purple}{\mathbf{v}}$ by $T\color{purple}{\mathbf{v}}$.
An illustration of a Reflection across the green line
- Let \[ \color{teal}{\mathcal B} = \bigl\{ \color{teal}{\mathbf{u}_1}, \color{teal}{\mathbf{u}_2} \bigr\} \quad \text{and} \quad \mathcal E = \bigl\{ \mathbf{e}_1 , \mathbf{e}_2 \bigr\}. \] As we learned in Chapter 4 the change of coordinate matrices are \[ \underset{\mathcal{E}\leftarrow\mathcal{B}}{P} = \left[\! \begin{array}{rr} \cos \theta & - \sin \theta \\ \sin \theta & \cos \theta \end{array} \!\right] \quad \text{and} \quad \underset{\mathcal{B}\leftarrow\mathcal{E}}{P} = \left[\! \begin{array}{rr} \cos \theta & \sin \theta \\ - \sin \theta & \cos \theta \end{array} \!\right] \]
- It is clear that the matrix of the reflection $T$ relative to the teal basis $\color{teal}{\mathcal B}$ is \[ \bigl[ T \bigr]_{\color{teal}{\mathcal B}} = \left[\! \begin{array}{rr} 1 & 0 \\ 0 & -1 \end{array} \!\right]. \] This means that if we have the coordinates of a vector $\color{purple}{\mathbf{v}}$ relative to the teal basis $\color{teal}{\mathcal B}$ then we can easily calculate the coordinates of its reflection $T\color{purple}{\mathbf{v}}$ relative to the teal basis $\color{teal}{\mathcal B}:$ \[ \bigl[ T \color{purple}{\mathbf{v}} \bigr]_{\color{teal}{\mathcal B}} = \left[\! \begin{array}{rr} 1 & 0 \\ 0 & -1 \end{array} \!\right] \bigl[ \color{purple}{\mathbf{v}} \bigr]_{\color{teal}{\mathcal B}}. \]
- Now recall the power of the change of coordinates matrix: \[ \bigl[ \color{purple}{\mathbf{v}} \bigr]_{\color{teal}{\mathcal B}} = \underset{\mathcal{B}\leftarrow\mathcal{E}}{P} \bigl[ \color{purple}{\mathbf{v}} \bigr]_{\mathcal E} = \underset{\mathcal{B}\leftarrow\mathcal{E}}{P} \color{purple}{\mathbf{v}} \] and that \[ T \color{purple}{\mathbf{v}} = \bigl[ T \color{purple}{\mathbf{v}} \bigr]_{\mathcal E} = \underset{\mathcal{E}\leftarrow\mathcal{B}}{P} \bigl[ T \color{purple}{\mathbf{v}} \bigr]_{\color{teal}{\mathcal B}} \]
- Now put together the preceding three displayed relations: \[ T \color{purple}{\mathbf{v}} = \underset{\mathcal{E}\leftarrow\mathcal{B}}{P} \bigl[ T \color{purple}{\mathbf{v}} \bigr]_{\color{teal}{\mathcal B}} = \underset{\mathcal{E}\leftarrow\mathcal{B}}{P}\left[\! \begin{array}{rr} 1 & 0 \\ 0 & -1 \end{array} \!\right] \bigl[ \color{purple}{\mathbf{v}} \bigr]_{\color{teal}{\mathcal B}} = \underset{\mathcal{E}\leftarrow\mathcal{B}}{P}\left[\! \begin{array}{rr} 1 & 0 \\ 0 & -1 \end{array} \!\right] \underset{\mathcal{B}\leftarrow\mathcal{E}}{P} \color{purple}{\mathbf{v}}. \] Thus, the matrix of the reflection is \begin{align*} \underset{\mathcal{E}\leftarrow\mathcal{B}}{P}\left[\! \begin{array}{rr} 1 & 0 \\ 0 & -1 \end{array} \!\right] \underset{\mathcal{B}\leftarrow\mathcal{E}}{P} &= \left[\! \begin{array}{rr} \cos \theta & - \sin \theta \\ \sin \theta & \cos \theta \end{array} \!\right] \left[\! \begin{array}{rr} 1 & 0 \\ 0 & -1 \end{array} \!\right] \left[\! \begin{array}{rr} \cos \theta & \sin \theta \\ -\sin \theta & \cos \theta \end{array} \!\right] \\ & = \left[\! \begin{array}{rr} \cos \theta & - \sin \theta \\ \sin \theta & \cos \theta \end{array} \!\right] \left[\! \begin{array}{rr} \cos \theta & \sin \theta \\ \sin \theta & -\cos \theta \end{array} \!\right] \\ & = \left[\! \begin{array}{cc} (\cos \theta)^2 - (\sin\theta)^2 & 2 (\sin \theta)(\cos\theta) \\ 2 (\sin \theta)(\cos\theta) & (\sin\theta)^2 - (\cos \theta)^2 \end{array} \!\right] \\ & = \color{blue}{\left[\! \begin{array}{rr} \cos(2\theta) & \sin(2\theta) \\ \sin(2\theta) & -\cos(2\theta) \end{array} \!\right]} \end{align*}
- As an exercise consider a similar setting in $\mathbb{R}^3.$ Consider the plane in $\mathbb{R}^3$ given as \[ \operatorname{Span} \left\{ \left[\! \begin{array}{r} 1 \\ - 1 \\ 0 \end{array} \!\right], \left[\! \begin{array}{r} 0 \\ 1 \\ -1 \end{array} \!\right] \right\}. \] Your task is to find the matrix of the reflection in $\mathbb R^3$ across this plane. To help you out I will point out that the vector \[ \left[\! \begin{array}{c} 1 \\ 1 \\ 1 \end{array} \!\right] \] is orthogonal to the given plane.
-
Here I will present some interesting linear transformations of the vector space $\mathbb{P}_4$ of polynomials of degree $\leq 4$. In these examples I always calculate the matrix of a linear transformation with respect to the basis of this space which consists of monomials:
\[
\mathcal{M} =\bigl\{1, t, t^2, t^3,t^4 \bigr\}.
\]
Notice that this basis has 5 elements, so the space $\mathbb{P}_4$ is a five-dimensional vector space. Sometimes it is convenient to introduce notation for monomials: We set
\[
\phi_0(t) = 1, \quad \phi_1(t) = t, \quad \phi_2(t) = t^2, \quad \phi_3(t) = t^3, \quad \phi_4(t) = t^4.
\]
- Let $D: \mathbb P_4 \to \mathbb P_4$ be the linear transformation of taking the derivative with respect to $t$. That is, for every $p(t) \in \mathbb P_n$ we set $(Dp)(t) = p'(t).$ Then the matrix representation of $D$ relative to $\mathcal M$ is the following $5\!\times\!5$ matrix \[ \left[\! \begin{array}{ccccc} 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 2 & 0 & 0 \\ 0 & 0 & 0 & 3 & 0 \\ 0 & 0 & 0 & 0 & 4 \\ 0 & 0 & 0 & 0 & 0 \\ \end{array}\!\right]. \]
- Let $R: \mathbb P_4 \to \mathbb P_4$ be the linear transformation defined for every $p(t) \in \mathbb P_4$ by \[ (Rp)(t) = t^4 p(1/t). \] Then the matrix representation of $R$ relative to $\mathcal M$ is the following $5\!\times\!5$ matrix \[ Z_{5} = \left[\! \begin{array}{ccccc} 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 1 & 0 \\ 0 & 0 & 1 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 \\ 1 & 0 & 0 & 0 & 0 \\ \end{array}\!\right]. \]
-
Let $T: \mathbb P_4 \to \mathbb P_4$ be the linear transformation defined for every $p(t) \in \mathbb P_4$ by
\[
(Tp)(t) = (1-t^2)p''(t) - tp'(t).
\]
Then the matrix representation of $T$ relative to $\mathcal M$ is the following $5\!\times\!5$ matrix
\[
\left[
\begin{array}{rrrrr}
0 & 0 & 2 & 0 & 0 \\
0 & -1 & 0 & 6 & 0 \\
0 & 0 & -4 & 0 & 12 \\
0 & 0 & 0 & -9 & 0 \\
0 & 0 & 0 & 0 & -16
\end{array}
\right].
\]
The linear transformation introduced here is related to the Chebyshev differential equation and Chebyshev polynomials of the first kind, see my web-page about this topic using linear algebra.
- Assigned exercises for Section 5.3 are 2, 3, 5, 8, 9, 12, 13, 16, 18, 20, 23, 24.
- For Section 5.2 do 3, 5, 7, 11, 14, 15, (in all these problems you can find eigenvectors as well) 18 (this is a must do problem; notice that in this problem we are finding $h$ for which the given matrix is diagonalizable), 19, 20, 21, 24, 25.
-
In this item I will illustrate how to calculate eigenvalues and the corresponding eigenspaces of a specific $3\!\times\!3$ matrix. Consider the matrix
\[
A = \left[\!
\begin{array}{rrr}
3 & 1 & -1 \\
1 & 3 & -1 \\
3 & 3 & -1
\end{array}
\!\right] .
\]
- First we find the characteristic polynomial of this matrix. The characteristic polynomial is the determinant of the following matrix: \[ A - \lambda I_3 = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] - \left[\! \begin{array}{rrr} \lambda & 0 & 0 \\ 0 & \lambda & 0 \\ 0 & 0 & \lambda \end{array} \!\right] = \left[\! \begin{array}{ccc} 3-\lambda & 1 & -1 \\ 1 & 3-\lambda & -1 \\ 3 & 3 & -1-\lambda \end{array} \!\right] \] Next we calculate this determinant: \begin{align*} \left|\! \begin{array}{ccc} 3-\lambda & 1 & -1 \\ 1 & 3-\lambda & -1 \\ 3 & 3 & -1-\lambda \end{array} \!\right| &= \left|\! \begin{array}{ccc} 2-\lambda & -2+\lambda & 0 \\ 1 & 3-\lambda & -1 \\ 3 & 3 & -1-\lambda \end{array} \!\right| \\ &= \left|\! \begin{array}{ccc} 2-\lambda & 0 & 0 \\ 1 & 4-\lambda & -1 \\ 3 & 6 & -1-\lambda \end{array} \!\right| \\ &= (2-\lambda) \bigl( (4-\lambda)(-1-\lambda) + 6 \bigr) \\ & = (2-\lambda)\bigl(\lambda^2 - 3 \lambda + 2\bigr) \\ & = -(\lambda - 2)^2 ( \lambda - 1) \end{align*} (At the first equality sign, we subtracted the second row from the first. At the second equality sign, we added the first column to the second. These operations do not change the value of a determinant.)
- Thus the eigenvalues of the matrix $A$ are $1$ and $2.$
- Next we will find the eigenspace corresponding to the eigenvalue $1.$ For that we need to find the nullspace of the matrix \[ A - 1 I_3 = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] - \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{ccc} 2 & 1 & -1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right]. \] So, we row reduce this matrix: \[ \left[\! \begin{array}{ccc} 2 & 1 & -1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] \sim \left[\! \begin{array}{ccc} 1 & 2 & -1 \\ 0 & 3 & -1 \\ 0 & 3 & -1 \end{array} \!\right] \sim \left[\! \begin{array}{ccc} 1 & 2 & -1 \\ 0 & 1 & -1/3 \\ 0 & 0 & 0 \end{array} \!\right] \sim \left[\! \begin{array}{ccc} 1 & 0 & -1/3 \\ 0 & 1 & -1/3 \\ 0 & 0 & 0 \end{array} \!\right]. \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} s/3 \\ s/3 \\ s \end{array} \!\right] \ : \ s \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] \right\}. \] Hence one eigenvector is $\left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right].$
- Next we will find the eigenspace corresponding to the eigenvalue $2.$ For that we need to find the nullspace of the matrix \[ A - 2 I_3 = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] - \left[\! \begin{array}{rrr} 2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & 1 & -1 \\ 1 & 1 & -1 \\ 3 & 3 & -3 \end{array} \!\right]. \] So, we row reduce this matrix: \[ \left[\! \begin{array}{rrr} 1 & 1 & -1 \\ 1 & 1 & -1 \\ 3 & 3 & -3 \end{array} \!\right] \sim \left[\! \begin{array}{rrr} 1 & 1 & -1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array} \!\right]. \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} -s + t \\ s \\ t \end{array} \!\right] \ : \ s, t \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{c} -1 \\ 1 \\ 0 \end{array} \!\right], \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] \right\}. \] Hence two linearly independent eigenvectors corresponding to the eigenvalue $2$ are $\left[\! \begin{array}{c} -1 \\ 1 \\ 0 \end{array} \!\right]$ and $\left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right].$
- The magic of what we found by now is that we found a basis of $\mathbb{R}^3$ which consists of eigenvectors of $A:$ \[ \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right], \quad \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \quad \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right]. \] Consequently the matrix $A$ is diagonalizable. We we diagonalize it below.
- Before continuing, we verify whether these are really eigenvectors: \begin{align*} \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] & = 1 \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right], \\ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & = 2 \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \\ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right]\left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] & = 2 \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right]. \end{align*}
- The preceding three vector equations can be written as one matrix equation: \[ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{crc} 1 & -1 & 1\\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{crc} 1 & -1 & 1\\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{crc} 1 & 0 & 0\\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] \]
- Next we calculate the inverse of \[ \left[\! \begin{array}{crc} 1 & -1 & 1\\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right]^{-1} = \left[\!\begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] \] The inverse is calculated using technology, or by finding reduced row echelon form of the following matrix \[ \left[\! \begin{array}{crc|ccc} 1 & -1 & 1 & 1 & 0 & 0\\ 1 & 1 & 0 & 0 & 1 & 0 \\ 3 & 0 & 1 & 0 & 0 & 1 \end{array} \!\right] \sim \cdots \sim \left[\! \begin{array}{ccc|rrc} 1 & 0 & 0 & -1 & -1 & 1\\ 0 & 1 & 0 & 1 & 2 & -1 \\ 0 & 0 & 1 & 3 & 3 & -2 \end{array} \!\right]. \] It is always a good idea to verify whether technology or our patience found the correct inverse: \[ \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right]. \]
- Finally we can write a diagonalization of $A$. We multiply the matrix equality which stated that we found eigenvectors \[ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{crc} 1 & -1 & 1\\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{crc} 1 & -1 & 1\\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{crc} 1 & 0 & 0\\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] \] by the inverse that we just found \[ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] . \] The preceding equality is called a diagonalization of $A.$ As in the example of yesterday, having a diagonalization at hand we can calculate integer powers of $A$ and other functions of $A.$
- A diagonalization of $A$ enables us to define functions of $A.$ The most important such function is \[ e^{At} \quad \text{where} \quad t \in \mathbb{R}. \] To explain how this formula works we need to rewrite the diagonalization as follows: \begin{align*} \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] & = \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] \\ & = \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left( \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array} \!\right] + 2 \left[\! \begin{array}{rrr} 0 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right] \right) \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] \\ % new line % & = \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] + 2 \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} 0 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] \\ & = \left[\!\begin{array}{rrr} -1 & -1 & 1 \\ -1 & -1 & 1 \\ -3 & -3 & 3 \end{array} \!\right] + 2 \left[\!\begin{array}{ccr} 2 & 1 & -1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] \end{align*}
- Two matrices that we constructed at the end of the previous item, that is, \[ P_1= \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] = \left[\!\begin{array}{rrr} -1 & -1 & 1 \\ -1 & -1 & 1 \\ -3 & -3 & 3 \end{array} \!\right] \] and \[ P_2 = \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} 0 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] = \left[\!\begin{array}{ccr} 2 & 1 & -1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] \] are very special. If you look carefully how $P_1$ and $P_2$ are constructed you will see that \[ \operatorname{Col}(P_1) = \operatorname{Nul}(A- I_3) \quad \text{and} \quad \operatorname{Col}(P_2) = \operatorname{Nul}(A- 2 I_3). \] That is, $\operatorname{Col}(P_1)$ is the eigenspace corresponding to the eigenvalues $1$ and $\operatorname{Col}(P_2)$ is the eigenspace corresponding to the eigenvalues $2.$ In my free language, I would describe this as: $\operatorname{Col}(P_1)$ is a one-dimensional space of simple action for $A$ ($A$ acts as identity on this space) and $\operatorname{Col}(P_2)$ is a two-dimensional space of simple action for $A$ ($A$ acts as scaling by $2$on this space).
- Moreover, the matrices $P_1$ and $P_2$ have the following four important properties: \[ P_1+P_2 = I_3, \quad P_1P_2 = P_2P_1 = 0, \quad P_1^2 = P_1,\quad P_2^2= P_2. \] Because of these four special properties $P_1$ and $P_2$ are called complementary projections. Recall that a diagonalization of $A$ that we found can now be written as \[ A = P_1 + 2 P_2. \]
- Since $A$ acts on $\operatorname{Col}(P_1)$ as identity, that is scaling by $1$, it makes sense to pronounce that $e^{At}$ acts on $\operatorname{Col}(P_1)$ as scaling by $e^t$. Similarly, since $A$ acts on $\operatorname{Col}(P_2)$ as scaling by $2$, it makes sense to pronounce that $e^{At}$ acts on $\operatorname{Col}(P_2)$ as scaling by $e^{2t}$. Therefore we set \[ e^{At} = e^t P_1 + e^{2t} P_2. \] Written as a matrix we have \[ e^{At} = \left[\!\begin{array}{ccc} -e^t+2 e^{2 t} & -e^t+e^{2 t} & e^t-e^{2 t} \\ -e^t+e^{2 t} & -e^t+2 e^{2 t} & e^t-e^{2 t} \\ -3 e^t+3 e^{2 t} & -3 e^t+3 e^{2 t} & 3 e^t-2 e^{2 t} \end{array} \!\right] \]
- Similar problems are studied in Math 331. Given a $3\times3$ matrix $A$ find the matrix valued function $Y(t)$ such that \[ Y'(t) = A Y(t) \quad \text{and} \quad Y(0) = I_3. \] We could certainly find the derivative \[ \frac{d}{dt} \left[\!\begin{array}{ccc} -e^t+2 e^{2 t} & -e^t+e^{2 t} & e^t-e^{2 t} \\ -e^t+e^{2 t} & -e^t+2 e^{2 t} & e^t-e^{2 t} \\ -3 e^t+3 e^{2 t} & -3 e^t+3 e^{2 t} & 3 e^t-2 e^{2 t} \end{array} \!\right] = \left[\!\begin{array}{ccc} -e^t+4 e^{2 t} & -e^t+2 e^{2 t} & e^t-2 e^{2 t} \\ -e^t+2 e^{2 t} & -e^t+4 e^{2 t} & e^t-2 e^{2 t} \\ -3 e^t+6 e^{2 t} & -3 e^t+6 e^{2 t} & 3 e^t-4 e^{2 t} \end{array} \!\right] \] and confirm that this expression is identical to \[ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\!\begin{array}{ccc} -e^t+2 e^{2 t} & -e^t+e^{2 t} & e^t-e^{2 t} \\ -e^t+e^{2 t} & -e^t+2 e^{2 t} & e^t-e^{2 t} \\ -3 e^t+3 e^{2 t} & -3 e^t+3 e^{2 t} & 3 e^t-2 e^{2 t} \end{array} \!\right]. \]
- However, it is much easier to verify that $Y(t) = e^{At}$ solves the given differential equation by using \[ e^{At} = e^t P_1 + e^{2t} P_2 \] and the properties of $P_1$ and $P_2$: \[ \frac{d}{dt} e^{At} = e^t P_1 + 2 e^{2t} P_2 \] and \begin{align*} A e^{At} & = \bigl(P_1 + 2 P_2 \bigr) \bigl( e^t P_1 + e^{2t} P_2 \bigr) \\ & = e^t P_1 P_1 + 2 e^t P_2 P_1 + e^{2t} P_1P_2 + 2 e^{2t} P_2 P_2 \\ & = e^t P_1 P_1 + 2 e^{2t} P_2 = \frac{d}{dt} e^{At}. \end{align*}
- I talked about this during the office hour, so I had to explain it properly. The explanation is few steps removed from the diagonalization, but not too much. This method is universal; it works for every diagonalizatble matrix. The method can be adopted for matrices that are not diagonalizable, but the definition of the exponential function for such matrices is more complicated. For $2\times2$ matrices it is probably done in Math 331.
-
In this item I will illustrate how to calculate eigenvalues and the corresponding eigenspaces of a specific $4\!\times\!4$ matrix. The purpose is to demonstrate a matrix that is not diagonalizable. Consider the matrix
\[
A = \left[\!
\begin{array}{rrrr}
0 & 0 & -1 & -1 \\
-1 & 0 & 0 & 0 \\
2 & 1 & 2 & 1 \\
-2 & -1 & -1 & 0
\end{array}
\!\right] .
\]
- First we find the characteristic polynomial of this matrix. The characteristic polynomial is the determinant of the following matrix: \[ A - \lambda I_4 = \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] - \left[\! \begin{array}{rrrr} \lambda & 0 &0 & 0 \\ 0 & \lambda & 0 & 0 \\ 0 & 0 & \lambda & 0 \\ 0 & 0 & 0 & \lambda \end{array} \!\right] = \left[\! \begin{array}{cccc} -\lambda & 0 & -1 & -1 \\ -1 & -\lambda & 0 & 0 \\ 2 & 1 & 2-\lambda & 1 \\ -2 & -1 & -1 & -\lambda \end{array} \!\right] \] Next we calculate the determinant of the preceding matrix: \begin{align*} \left|\! \begin{array}{cccc} -\lambda & 0 & -1 & -1 \\ -1 & -\lambda & 0 & 0 \\ 2 & 1 & 2-\lambda & 1 \\ -2 & -1 & -1 & -\lambda \end{array} \!\right| & = -\lambda \left|\begin{array}{ccc} -\lambda & 0 & 0 \\ 1 & 2-\lambda & 1 \\ -1 & -1 & -\lambda \end{array} \right| - \left| \begin{array}{ccc} -1 & -\lambda & 0 \\ 2 & 1 & 1 \\ -2 & -1 & -\lambda \end{array} \right| + \left| \begin{array}{ccc} -1 & -\lambda & 0 \\ 2 & 1 & 2-\lambda \\ -2 & -1 & -1 \end{array} \right| \\ & = \lambda^2 ( \lambda^2 -2 \lambda + 1 ) - \bigl( \lambda -1 +2 \lambda - 2 \lambda^2 \bigr) + \bigl( \lambda - 1 + 2 \lambda - 2 \lambda^2 \bigr) \\ & = \lambda^2 ( \lambda^2 -2 \lambda + 1 ) \\ & = \lambda^2 ( \lambda - 1 )^2 \end{align*}
- Thus the eigenvalues of the matrix $A$ are $0$ and $1.$ The algebraic multiplicities of both eigenvalues is $2.$ Next we will calculate the geometric multiplicities of these eigenvalues.
- Next we will find the eigenspace corresponding to the eigenvalue $0.$ For that we need to find the nullspace of the matrix \[ A - 0 I_4 = \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] \]
- So, we row reduce the matrix $A:$ \[ \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] \sim \cdots \sim \left[\! \begin{array}{rrrr} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & -1 \\ 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 0 \end{array} \!\right] \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} 0 \\ s \\ -s \\ s \end{array} \!\right] \ : \ s \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{r} 0 \\ 1 \\ -1 \\ 1 \end{array} \!\right] \right\}. \]
- Thus, the geometric multiplicity of $0$ as an eigenvalue of $A$ is $1.$ Since $1\lt 2$ we can conclude that the matrix $A$ is not diagonalizable. We need the geometric multiplicity of each eigenvalue to be identical to their algebraic multiplicity.
- Next we will find the eigenspace corresponding to the eigenvalue $1.$ For that we need to find the nullspace of the matrix \[ A - 1 I_4 = \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] - \left[\! \begin{array}{rrrr} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{rrrr} -1 & 0 & -1 & -1 \\ -1 & -1 & 0 & 0 \\ 2 & 1 & 1 & 1 \\ -2 & -1 & -1 & -1 \end{array} \!\right] \]
- So, we row reduce the last matrix: \[ \left[\! \begin{array}{rrrr} -1 & 0 & -1 & -1 \\ -1 & -1 & 0 & 0 \\ 2 & 1 & 1 & 1 \\ -2 & -1 & -1 & -1 \end{array} \!\right] \sim \cdots \sim \left[\! \begin{array}{rrrr} 1 & 0 & 1 & 1 \\ 0 & 1 & -1 & -1 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{array} \!\right] \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} -s-t \\ s+t \\ s \\ t \end{array} \!\right] \ : \ s, t \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{r} -1 \\ 1 \\ 1 \\ 0 \end{array} \!\right], \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \\ 1 \end{array} \!\right] \right\}. \]
- Thus, the geometric multiplicity of $2$ as an eigenvalue of $A$ is $2,$ same as its algebraic multiplicity.
- Since we found all eigenspaces of the $4\!\times\!4$ matrix $A$ and these eigenspaces have dimensions $1$ and $2$, we conclude that we can have at most three linearly independent eigenvectors. Consequently, we can not have a basis for $\mathbb R^4$ which consists of eigenvectors of $A.$ This shows directly that the matrix $A$ is not diagonalizable.
- For Section 5.2 do 1-8, 11, 12, 14, 15, (in all these problems you can find eigenvectors as well) 9, 13, 18, 19, 20, 21, 24, 25, 27.
- Proofs are important aspect of mathematics. One proof that you need to understand and be able to demonstrate your understanding is Theorem 2 in Section 5.1. Since the proof of this theorem in the book is somewhat cryptic, I present a different proof of this theorem here.
-
In this item I will illustrate one application of linear independence of eigenvectors of a $2\times 2$ matrix. Consider the matrix
\[
A = \frac{1}{10} \left[\!\begin{array}{rr} 8& 3 \\ 2 & 7 \end{array}\!\right] = \left[\!\begin{array}{rr} 4/5 & 3/10 \\ 1/5 & 7/10 \end{array}\!\right].
\]
For this matrix answer the following questions: (a) Find a basis of $\mathbb{R}^2$ which consists of eigenvectors of $A$. (b) Let $n$ be a positive integer. Find the formula for $A^n.$ (c) Calculate $\displaystyle \lim_{n\to\infty} A^n.$ (d) Express vector $\mathbf{x}_0 = \left[\!\begin{array}{r} 1 \\ 9 \end{array}\!\right]$ as a linear combination of the basis vectors from (a). (e) Use (d) to find $\displaystyle \lim_{n\to\infty} A^n\mathbf{x}_0.$
- First we find the characteristic polynomial of $A$. The characteristic polynomial is the determinant of the following matrix: \[ A - \lambda I_2 = \frac{1}{10} \left[\!\begin{array}{rr} 8& 3 \\ 2 & 7 \end{array}\!\right] - \left[\! \begin{array}{rrr} \lambda & 0 \\ 0 & \lambda \end{array} \!\right] = \left[\! \begin{array}{ccc} 4/5 -\lambda & 3/10 \\ 1/5 & 7/10 - \lambda \end{array} \!\right] \] The determinant of this matrix, that is the characteristic polynomial of $A$ is \begin{equation*} \lambda^2 - \frac{3}{2} \lambda + \frac{1}{2} \end{equation*}
- The roots of the characteristic polynomial of $A$ are $1$ and $1/2$. These are the eigenvalues of the matrix $A.$
- An eigenvector corresponding to the eigenvalue $1$ is $\left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right]$ and an eigenvector corresponding to the eigenvalue $1/2$ is $\left[\!\begin{array}{r} 1 \\ -1\end{array}\!\right]$: \[ \frac{1}{10} \left[\!\begin{array}{rr} 8& 3 \\ 2 & 7 \end{array}\!\right]\left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right] = \left[\!\begin{array}{r} 3 \\ 2 \end{array}\!\right], \quad \frac{1}{10} \left[\!\begin{array}{rr} 8& 3 \\ 2 & 7 \end{array}\!\right]\left[\!\begin{array}{r} 1 \\ -1\end{array}\!\right] = \frac{1}{2} \left[\!\begin{array}{r} 1 \\ -1\end{array}\!\right] \]
- The vectors $\left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right]$ and $\left[\!\begin{array}{r} 1 \\ -1\end{array}\!\right]$ are linearly independent since \[ \det \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right] = - 5 \] Notice that \[ \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right]^{-1} = \frac{1}{5} \left[\!\begin{array}{rr} 1 & 1 \\ 2 & -3 \end{array}\!\right] \]
- The fact that the vectors $\left[\!\begin{array}{c} 3 \\ 2\end{array}\!\right]$ and $\left[\!\begin{array}{r} 1 \\ -1\end{array}\!\right]$ are eigenvectors of $A$ can be written as \[ \frac{1}{10} \left[\!\begin{array}{rr} 8& 3 \\ 2 & 7 \end{array}\!\right] \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right] = \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right] \left[\!\begin{array}{rc} 1 & 0 \\ 0 & 1/2 \end{array}\!\right], \] or, equivalently \[ A = \frac{1}{10} \left[\!\begin{array}{rr} 8& 3 \\ 2 & 7 \end{array}\!\right] = \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right] \left[\!\begin{array}{rc} 1 & 0 \\ 0 & 1/2 \end{array}\!\right]\left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right]^{-1} . \] The preceding formula is called a diagonalization of $A.$
- A diagonalization of $A$ is very convenient to raise $A$ to integer powers. Let $n$ be a positive integer. Then \[ A^n = \left[\!\begin{array}{rr} 4/5 & 3/10 \\ 1/5 & 7/10 \end{array}\!\right]^n = \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right] \left[\!\begin{array}{rc} 1^n & 0 \\ 0 & 1/(2^n) \end{array}\!\right]\left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right]^{-1} = \frac{1}{5} \left[\!\begin{array}{rr} 3 & 3 \\ 2 & 2 \end{array}\!\right] + \frac{1}{5\, 2^n} \left[\!\begin{array}{rr} 2 & -3 \\ -2 & 3 \end{array}\!\right]. \] Letting $n\to\infty$ in the preceding formula we obtain \begin{align*} \lim_{n\to\infty} \left[\!\begin{array}{rr} 4/5 & 3/10 \\ 1/5 & 7/10 \end{array}\!\right]^n & = \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right] \lim_{n\to\infty} \left[\!\begin{array}{rc} 1 & 0 \\ 0 & 1/(2^n) \end{array}\!\right] \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right]^{-1} \\ & = \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right] \left[\!\begin{array}{rc} 1 & 0 \\ 0 & 0 \end{array}\!\right]\left[\!\begin{array}{rr} 1/5 & 1/5 \\ 2/5 & -3/5 \end{array}\!\right] \\ & = \frac{1}{5} \left[\!\begin{array}{rr} 3 & 3 \\ 2 & 2 \end{array}\!\right] \end{align*}
- A diagonalization of $A$ can be used to define other functions of $A$. For example, the following definition makes sense \[ e^A = e^{\left[\!\begin{array}{rr} 4/5 & 3/10 \\ 1/5 & 7/10 \end{array}\!\right]} = \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right] \left[\!\begin{array}{rc} e^1 & 0 \\ 0 & e^{1/2} \end{array}\!\right]\left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right]^{-1} = \frac{e}{5} \left[\!\begin{array}{rr} 3 & 3 \\ 2 & 2 \end{array}\!\right] + \frac{\sqrt{e}}{5} \left[\!\begin{array}{rr} 2 & -3 \\ -2 & 3 \end{array}\!\right]. \]
- We could use the previous results about the powers of $A^n$ to answer part (e). However, we will demonstrate a different simpler method which uses (d).
- Let $\lambda$ be an eigenvalue of $A$ and let $\mathbf{v}$ be a corresponding eigenvector. That is, \[ A\mathbf{v} = \lambda \mathbf{v}. \] Applying $A$ to both sides of the preceding equality and using linearity of matrix-vector multiplication we get \[ A^2 \mathbf{v} = A(\lambda \mathbf{v}) = \lambda A\mathbf{v} = \lambda^2 \mathbf{v}. \] We can repeat this process many, many times. For a positive integer $n$ we have \[ A^{n} \mathbf{v} = \lambda^{n} \mathbf{v}. \]
- To utilize the observation in the preceding item we address part (b) and write \[ \mathbf{x}_0 = \left[\!\begin{array}{r} 1\\ 9\end{array}\!\right] = \alpha_1 \left[\!\begin{array}{c} 3 \\ 2\end{array}\!\right]+ \alpha_2 \left[\!\begin{array}{r} 1 \\ -1\end{array}\!\right] = \left[\!\begin{array}{cr} 3 & 1 \\ 2 & -1 \end{array}\!\right] \left[\!\begin{array}{r} \alpha_1 \\ \alpha_2\end{array}\!\right]. \] Hence, \[ \left[\!\begin{array}{r} \alpha_1 \\ \alpha_2\end{array}\!\right] = \frac{1}{5} \left[\!\begin{array}{rr} 1 & 1 \\ 2 & -3 \end{array}\!\right] \left[\!\begin{array}{r} 1 \\ 9 \end{array}\!\right] = \left[\!\begin{array}{r} 2 \\ -5\end{array}\!\right] \] and therefore \[ \left[\!\begin{array}{r} 1 \\ 9 \end{array}\!\right] = 2 \left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right] - 5 \left[\!\begin{array}{r} 1 \\ -1\end{array}\!\right]. \] This answers (d).
- Applying $A^n$ to the preceding formula we get \begin{align*} A^n \left[\!\begin{array}{r} 1 \\ 9 \end{array}\!\right] & = 2 A^n \left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right] - 5 A^n \left[\!\begin{array}{r} 1 \\ -1\end{array}\!\right] \\ & = 2 \cdot 1^n \left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right] - 5 \frac{1}{2^n} \left[\!\begin{array}{r} 1 \\ -1\end{array}\!\right] \\ & = \left[\!\begin{array}{c} 6 \\ 4 \end{array}\!\right] + \frac{1}{2^n} \left[\!\begin{array}{r} -5 \\ 5 \end{array}\!\right] \end{align*} This result is the same as applying $A^n$ which we calculated above to the vector $\mathbf{x}_0$: \[ \left(\frac{1}{5} \left[\!\begin{array}{rr} 3 & 3 \\ 2 & 2 \end{array}\!\right] + \frac{1}{5\, 2^n} \left[\!\begin{array}{rr} 2 & -3 \\ -2 & 3 \end{array}\!\right]\right)\left[\!\begin{array}{r} 1 \\ 9 \end{array}\!\right] = \left[\!\begin{array}{c} 6 \\ 4 \end{array}\!\right] + \frac{1}{2^n} \left[\!\begin{array}{r} -5 \\ 5 \end{array}\!\right]. \]
- Now it is easy to calculate the limit \[ \lim_{n\to\infty} A^n \left[\!\begin{array}{r} 1 \\ 9 \end{array}\!\right] = \left[\!\begin{array}{c} 6 \\ 4 \end{array}\!\right]. \] And this result is the same as applying the previously calculated limit of $A^n$ to $\mathbf{x}_0$: \[ \frac{1}{5} \left[\!\begin{array}{rr} 3 & 3 \\ 2 & 2 \end{array}\!\right] \left[\!\begin{array}{r} 1 \\ 9 \end{array}\!\right] = \left[\!\begin{array}{c} 6 \\ 4 \end{array}\!\right]. \]
- Read Section 5.1. Suggested problems for Section 5.1: 1, 3, 4, 5, 6, 8, 11, 15, 16, 17, 19, 20, 24-27, 29, 30, 31.
- A related Wikipedia link: Eigenvalue, eigenvector and eigenspace.
- Below are animations of different matrices in action. In each scene the navy blue vector is the image of the sea green vector under the multiplication by a matrix $A$. For easier visualization of the action the heads of vectors leave traces.
- Just looking at the movies you can guess what the eigenvalues and eigenvectors of the featured matrix are. In particular it is easy to see whether an eigenvalue is positive, negative, zero, or complex, ...
-
Moreover, looking at the movies, you can also SEE what the matrix used in each movie is. This is done by using, what I called "matrix surgery":
(n-by-n matrix M) (k-th column of the n-by-n identity matrix) = (k-th column of the n-by-n matrix M).
Place the cursor over the image to start the animation.
|
|
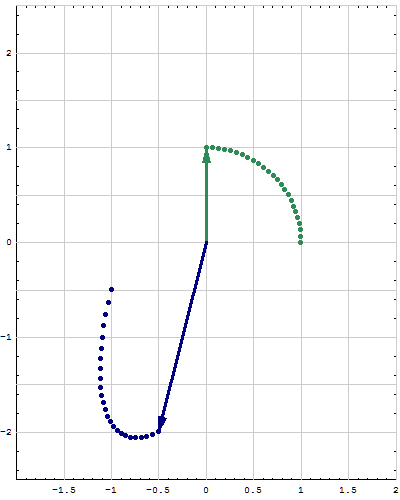
|
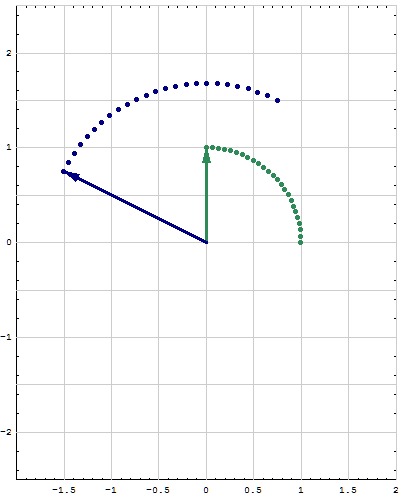
|
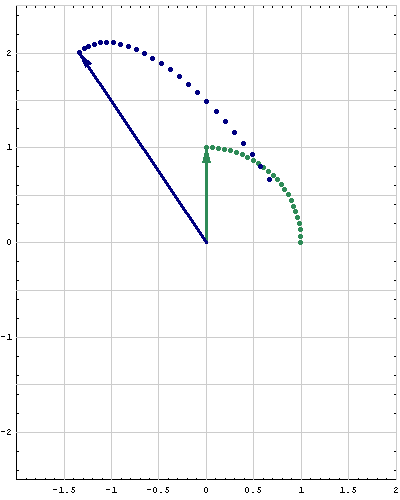
|
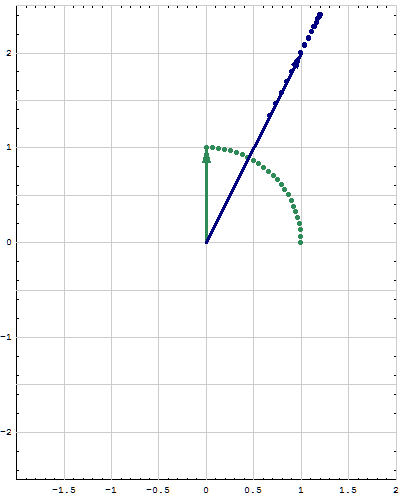
|
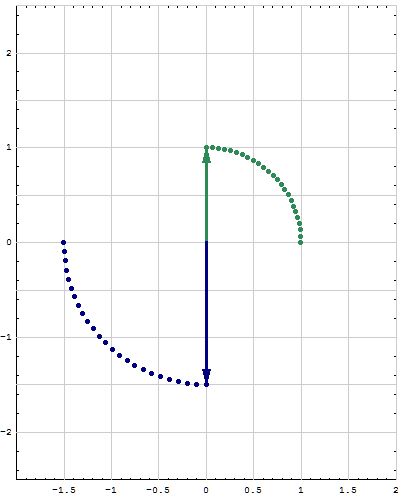
|
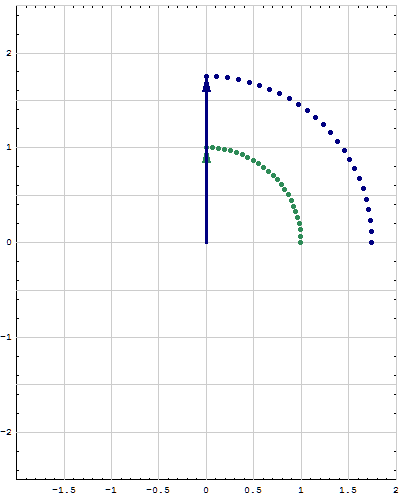
|
- In Discussions on Canvas I commented on Shao-Peng's and Acamaro's writing trying to suggest improvements in presentation. But, combining the original writing and my suggestions might be a confusing task for other students. Therefore, below I present a direct proof of what was discussed.
-
Proposition. Let \(\mathbb{P}_2\) be the vector space of all polynomials with real coefficients whose degree is less or equal two. That is, \[ \mathbb{P}_2 = \bigl\{ a_0 + a_1 x + a_2 x^2 \, : \, a_0, a_1, a_2 \in \mathbb{R} \bigr\}. \] Let \[ \mathcal{Z}_1 = \bigl\{ f(x) \in \mathbb{P}_2 \, : \, f(1) = 0 \bigr\}. \] Then the polynomials $x-1$ and $x^2-1$ form a basis for $\mathcal{Z}_1.$
-
Proof. Part I. We will first prove that \[ \mathcal{Z}_1 = \operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\}. \] The proof consists of two parts.
Part Ia. Here we prove \[ \operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\} \subseteq \mathcal{Z}_1. \] Assume that \[ f(x) \in \operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\}. \] Then there exist \(\alpha_1, \alpha_2 \in \mathbb{R} \) such that \[ f(x) = \alpha_1 (x-1) + \alpha_2 (x^2-1). \] Therefore \[ f(1) = \alpha_1 (1-1) + \alpha_2 (1^2-1) = 0. \] Hence \(f(x) \in \mathcal{Z}_1\). Thus we proved that each polynomial which is in $\operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\}$ must also be in $\mathcal{Z}_1.$ In other words, we proved \[ \operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\} \subseteq \mathcal{Z}_1. \] This is the end of Part Ia of the proof.
Part Ib. Here we prove \[ \mathcal{Z}_1 \subseteq \operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\}. \] Assume that \( f(x) \in \mathcal{Z}_1\). Then, since $f\in \mathbb{P}_2$, we have \[ f(x) = a_0 + a_1 x+a_2 x^2 \] for some $a_0, a_1, a_2 \in \mathbb{R}$. Since \( f(x) \in \mathcal{Z}_1\), we have \(f(1) = a_0 + a_1+a_2=0.\) Consequently, \(a_0 = -a_1-a_2,\) and therefore \[ f(x) = -a_1-a_2 + a_1 x+a_2 x^2 = a_1 (x-1) + a_2 (x^2 - 1). \] The last formula shows that the polynomial $f(x)$ is a linear combination of the polynomials $x-1$ and $x^2-1.$ That is, \( f(x) \in \operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\}.\) Thus we proved that each polynomial which is in $\mathcal{Z}_1$ must also be in $\operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\}.$ In other words, we proved \[ \mathcal{Z}_1 \subseteq \operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\}. \] This is the end of Part Ib of the proof.
Part Ic. It remains to state that based on Part Ia and Part Ib of the proof we have proved \[ \mathcal{Z}_1 = \operatorname{Span}\bigl\{ x-1, x^2-1 \bigr\}. \] This completes Part I of the proof.
Part II. Here we will prove that the polynomials $x-1$ and $x^2-1$ are linearly independent. To prove this we will use the coordinate mapping \[ \bigl( a_0 + a_1 x + a_2 x^2 \bigr) \mapsto \bigl[ a_0 + a_1 x + a_2 x^2 \bigr]_{\mathcal M} = \begin{bmatrix} a_0 \\ a_1 \\ a_2 \end{bmatrix}, \] which is an isomorphism between vector spaces $\mathbb{P}_2$ and $\mathbb{R}^3.$ Here $\mathcal{M} = \bigl\{1, x, x^2 \bigr\}$ is the standard basis of $\mathbb{P}_2$ consisting of monomials. Since the coordinate mapping is isomorphism, the polynomials $x-1$ and $x^2-1$ are linearly independent if and only if the vectors \[ \bigl[ x-1 \bigr]_{\mathcal M} = \begin{bmatrix} -1 \\ 1 \\ 0 \end{bmatrix}, \quad \bigl[ x^2 -1 \bigr]_{\mathcal M} = \begin{bmatrix} -1 \\ 0 \\ 1 \end{bmatrix} \] are linearly independent. To prove the linear independence of the preceding two vectors, let $\alpha_1, \alpha_2 \in \mathbb{R}$ be such that \[ \alpha_1 \begin{bmatrix} -1 \\ 1 \\ 0 \end{bmatrix} + \alpha_2 \begin{bmatrix} -1 \\ 0 \\ 1 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix}. \] Simplifying the left-hand side of the preceding equality we get \[ \begin{bmatrix} -\alpha_1 - \alpha_2 \\ \alpha_1 \\ \alpha_2 \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix}. \] The last equality implies that $\alpha_1 = 0$ and $\alpha_2 = 0.$ This proves that the polynomials $x-1$ and $x^2-1$ are linearly independent. This completes Part II of the proof.
Part III. It remains to state that based on Part I and Part II of the proof we deduce that the polynomials $x-1$ and $x^2-1$ form a basis for the space $\mathcal{Z}_1.$ This completes the proof. QED
- I have gone into too many details of this proof. But, always better provide more details than less. In your presentations you can shorten the arguments, but the essential parts should be there. For example, Acamaro's proof of linear independence in Discussions is fine, except that it did not mention isomorphism, which is the essential part in the reasoning. Compare Acamaro's proof of Part II to mine; Acamaro's proof is shorter and it would have been complete if it mentioned the isomorphism.
- It is important to explore the concepts of a subspace and a basis in the context of an $m\!\times\!n$ matrix \[ A = \left[\! \begin{array}{cccc} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \\ \end{array} \!\right] . \] Together with the $m\!\times\!n$ matrix $A$ it is always useful to consider its transpose the $n\!\times\!m$ matrix $A^\top$: \[ A^\top = \left[\! \begin{array}{cccc} a_{11} & a_{21} & \cdots & a_{m1} \\ a_{12} & a_{22} & \cdots & a_{m2} \\ \vdots & \vdots & \ddots & \vdots \\ a_{1n} & a_{2n} & \cdots & a_{mn} \\ \end{array} \!\right] . \] Notice that the matrix $A$ has $n$ columns which are vectors in $\mathbb{R}^m$ and that these vectors are exactly the rows of the matrix $A^\top$: \[ \left[\! \begin{array}{c} a_{11} \\ a_{21} \\ \vdots \\ a_{m1} \end{array} \!\right] , \left[\! \begin{array}{c} a_{12} \\ a_{22} \\ \vdots \\ a_{m2} \end{array} \!\right] , \cdots, \left[\! \begin{array}{c} a_{1n} \\ a_{2n} \\ \vdots \\ a_{mn} \end{array} \!\right] \in \mathbb{R}^m. \] Notice that the the matrix $A$ has $m$ rows which are vectors in $\mathbb{R}^n$ and that these vectors are exactly the columns of the matrix $A^\top$: \[ \left[\! \begin{array}{c} a_{11} \\ a_{12} \\ \vdots \\ a_{1n} \end{array} \!\right] , \left[\! \begin{array}{c} a_{21} \\ a_{22} \\ \vdots \\ a_{2n} \end{array} \!\right] , \cdots, \left[\! \begin{array}{c} a_{m1} \\ a_{m2} \\ \vdots \\ a_{mn} \end{array} \!\right] \in \mathbb{R}^n. \] There are four fundamental fundamental subspaces associated with the matrices $A$ and $A^\top.$ They are \begin{align*} \operatorname{Col} A &= \operatorname{Row}(A^\top) = \operatorname{Span}\left\{ \left[\! \begin{array}{c} a_{11} \\ a_{21} \\ \vdots \\ a_{m1} \end{array} \!\right] , \left[\! \begin{array}{c} a_{12} \\ a_{22} \\ \vdots \\ a_{m2} \end{array} \!\right] , \cdots, \left[\! \begin{array}{c} a_{1n} \\ a_{2n} \\ \vdots \\ a_{mn} \end{array} \!\right] \right\} \subseteq \mathbb{R}^m, \\ \operatorname{Raw} A &= \operatorname{Col}(A^\top) = \operatorname{Span}\left\{ \left[\! \begin{array}{c} a_{11} \\ a_{12} \\ \vdots \\ a_{1n} \end{array} \!\right] , \left[\! \begin{array}{c} a_{21} \\ a_{22} \\ \vdots \\ a_{2n} \end{array} \!\right] , \cdots, \left[\! \begin{array}{c} a_{m1} \\ a_{m2} \\ \vdots \\ a_{mn} \end{array} \!\right] \right\} \subseteq \mathbb{R}^n, \\ \operatorname{Nul} A & = \bigl\{ \mathbf{x} \in \mathbb{R}^n \, : \, A \mathbf{x} = \mathbf{0} \, \bigr\} \subseteq \mathbb{R}^n, \\ \operatorname{Nul}(A^\top) & = \bigl\{ \mathbf{y} \in \mathbb{R}^m \, : \, A^\top \mathbf{y} = \mathbf{0} \, \bigr\} \subseteq \mathbb{R}^m . \end{align*}
- For a specific matrix, its reduced row echelon form (RREF) is the key to finding bases for the above subspaces, see Bases for $\operatorname{Nul} A$ and $\operatorname{Col} A$ on page 213.
-
Consider the specific matrix $A$ and its reduced row echelon form (RREF) given below.
\[
A = \left[\! \begin{array}{rrrrr}
1 & 3 & 2 & 2 & 2 \\
2 & 0 & -2 & 1 & 1 \\
2 & 1 & -1 & 1 & 2 \\
1 & 4 & 3 & 2 & 3
\end{array} \!\right] \sim \cdots \sim \left[\!
\begin{array}{rrrrr}
1 & 0 & -1 & 0 & 1 \\
0 & 1 & 1 & 0 & 1 \\
0 & 0 & 0 & 1 & -1 \\
0 & 0 & 0 & 0 & 0
\end{array}
\!\right].
\]
The reduced row echelon form of the matrix $A$ provides a treasure trove of information about matrix $A.$
- Since the matrix $A$ and its reduced row echelon form have the same row space, the nonzero rows of the reduced row echelon form (nonzero rows of RREF) form a basis for the row space of $A$: \[ \operatorname{Raw} A = \operatorname{Span}\left\{ \left[\! \begin{array}{r} 1 \\ 0 \\ -1 \\ 0 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 1 \\ 1 \\ 0 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 0 \\ 0 \\ 1 \\ -1 \end{array} \!\right] \right\} \subseteq \mathbb{R}^5. \] Denote by $\mathcal{B}$ the basis in the above formula for $\operatorname{Row} A.$ Thus, the reduced row form of $A$ provides us with a basis for the subspace $\operatorname{Row} A = \operatorname{Col}(A^\top).$
- The essence of the reduced row echelon form of the matrix $A$ is the following equivalence of the corresponding homogeneous vector equations: \begin{multline*} x_ 1\!\! \left[\! \begin{array}{c} 1 \\ 2 \\ 2 \\ 1 \end{array} \!\right]\!\!+\! x_2\!\! \left[\! \begin{array}{c} 3 \\ 0 \\ 1 \\ 4 \end{array} \!\right]\!\!+\! x_3\!\! \left[\! \begin{array}{r} 2 \\ -2 \\ -1 \\ 3 \end{array} \!\right]\!\!+\! x_4\!\! \left[\! \begin{array}{c} 2 \\ 1 \\ 1 \\ 2 \end{array} \!\right]\!\!+\! x_5\!\! \left[\! \begin{array}{c} 2 \\ 1 \\ 2 \\ 3 \end{array} \!\right]\!=\!\left[\! \begin{array}{c} 0 \\ 0 \\ 0 \\ 0 \end{array} \!\right] \\ \text{if and only if} \ \ x_ 1\!\! \left[\! \begin{array}{c} 1 \\ 0 \\ 0 \\ 0 \end{array} \!\right]\!\!+\! x_2\!\! \left[\! \begin{array}{c} 0 \\ 1 \\ 0 \\ 0 \end{array} \!\right]\!\!+\! x_3\!\! \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \\ 0 \end{array} \!\right]\!\!+\! x_4\!\! \left[\! \begin{array}{c} 0 \\ 0 \\ 1 \\ 0 \end{array} \!\right]\!\!+\! x_5\!\! \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \\ 0 \end{array} \!\right]\!=\!\left[\! \begin{array}{c} 0 \\ 0 \\ 0 \\ 0 \end{array} \!\right] \end{multline*}
- By setting $x_3 = x_5=0$ in the above equivalence we see that the first, the second and the fourth column of $A$ are linearly independent. Setting $x_1 = -1,$ $x_2 = 1,$ $x_3 = -1,$ $x_4=0,$ and $x_5 = 0$ in the right-hand side of the above equivalence we get a vector identity. Therefore, the third column of $A$ is a linear combination of the first and the second column of $A$. Similarly, setting $x_1 = 1,$ $x_2 = 1,$ $x_3 = 0,$ $x_4=-1,$ and $x_5 = -1$ in the right-hand side of the above equivalence we get a vector identity. Therefore, the fifth column of $A$ is a linear combination of the first, the second and the fourth column of $A$. Therefore, the set of the first, the second and the fourth column of $A$ forms a basis for $\operatorname{Col} A$. That is \[ \operatorname{Col} A = \operatorname{Span}\left\{ \left[\! \begin{array}{c} 1 \\ 2 \\ 2 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{c} 3 \\ 0 \\ 1 \\ 4 \end{array} \!\right] , \left[\! \begin{array}{c} 2 \\ 1 \\ 1 \\ 2 \end{array} \!\right] \right\} \subseteq \mathbb{R}^4. \] Denote by $\mathcal{C}$ the basis in the above formula for the subspace $\operatorname{Col} A = \operatorname{Row}(A^\top).$
- Finally, we use the RREF of $A$ to determine a basis for $\operatorname{Nul} A.$ The homogeneous system of linear equations that corresponds to the RREF of $A$ is equivalent to the matrix equation $A\mathbf{x} = \mathbf{0}.$ Next we solve that system: \begin{alignat*}{6} & x_1 \phantom{+} & \phantom{x_2} - & x_3 \phantom{+} & \phantom{x_4} + & x_5 & = & 0 \\ & & x_2 + & x_3 & + & x_5 & = & 0 \\ & & & & x_4 - & x_5 & = & 0 \\ \end{alignat*} In this system variables $x_3 = s$ and $x_5 = t$ are free and the variables are given as $x_1 = s-t$, $x_2 =-s-t$, $x_4 = t$. In vector form the solution is given by \[ \mathbf{x} = \left[\! \begin{array}{c} s-t \\ -s-t \\ s \\ t \\ t \end{array} \!\right] = s \left[\! \begin{array}{r} 1 \\ -1 \\ 1 \\ 0 \\ 0 \end{array} \!\right] + t \left[\! \begin{array}{r} -1 \\ -1 \\ 0 \\ 1 \\ 1 \end{array} \!\right]. \] Since $s$ and $t$ are arbitrary real numbers it follows that \[ \operatorname{Nul} A = \operatorname{Span}\left\{ \left[\! \begin{array}{r} 1 \\ -1 \\ 1 \\ 0 \\ 0 \end{array} \!\right] , \left[\! \begin{array}{r} -1 \\ -1 \\ 0 \\ 1 \\ 1\end{array} \!\right] \right\} \subseteq \mathbb{R}^5. \]
- Whenever the reduced row echelon form (RREF) is found we should observe the following remarkable identity: The matrix product of the matrix consisting of the pivot columns of $A$ and the matrix consisting of the nonzero rows of the RREF of $A$ results in the matrix $A$ \[ \require{bbox} \bbox[#7FBFBF, 8px, border: 3px solid teal]{ \left[\! \begin{array}{rrr} 1 & 3 & 2 \\ 2 & 0 & 1 \\ 2 & 1 & 1 \\ 1 & 4 & 2 \end{array} \!\right] \left[\! \begin{array}{rrrrr} 1 & 0 & -1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 1 \\ 0 & 0 & 0 & 1 & -1 \\ \end{array} \!\right] = \left[\! \begin{array}{rrrrr} 1 & 3 & 2 & 2 & 2 \\ 2 & 0 & -2 & 1 & 1 \\ 2 & 1 & -1 & 1 & 2 \\ 1 & 4 & 3 & 2 & 3 \end{array} \!\right] = A }. \] I decided to color this identity in teal since it is beauteaful.
-
Notice that the columns in the $4\!\times\!3$ matrix in the teal identity are the basis vectors in the basis $\mathcal{C}$.
Similarly, the rows in the $3\!\times\!5$ matrix in the teal identity are the basis vectors in the basis $\mathcal{B}$.
By the rules of the matrix multiplication the teal identity tells us that the columns of the matrix $A$ are linear combinations of the columns of the $4\!\times\!3$ matrix in the teal identity. The coefficients in these linear combinations are the columns of $3\!\times\!5$ matrix in the teal identity. This can be expressed using coordinate vectors relative to the basis $\mathcal{C}:$ \[ \left[\left[\! \begin{array}{r} 2 \\ -2 \\ -1 \\ 3 \end{array} \!\right]\right]_{\mathcal{C}} = \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \qquad \left[\left[\! \begin{array}{r} 2 \\ 1 \\ 2 \\ 3 \end{array} \!\right]\right]_{\mathcal{C}} = \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \] - By the rules of the matrix multiplication the teal identity tells us that the rows of the matrix $A$ are linear combinations of the rows of the $3\!\times\!5$ matrix in the teal identity. The coefficients in these linear combinations are the rows of $4\!\times\!3$ matrix in the teal identity. This can be expressed using coordinate vectors relative to the basis $\mathcal{B}:$ \[ \left[\left[\! \begin{array}{r} 1 \\ 3 \\ 2 \\ 2 \\ 2 \end{array} \!\right]\right]_{\mathcal{B}} = \left[\! \begin{array}{r} 1 \\ 3 \\ 2 \end{array} \!\right], \quad \left[\left[\! \begin{array}{r} 2 \\ 0 \\ -2 \\ 1 \\ 1 \end{array} \!\right]\right]_{\mathcal{B}} = \left[\! \begin{array}{r} 2 \\ 0 \\ 1 \end{array} \!\right], \quad \left[\left[\! \begin{array}{r} 2 \\ 1 \\ -1 \\ 1 \\ 2 \end{array} \!\right]\right]_{\mathcal{B}} = \left[\! \begin{array}{r} 2 \\ 1 \\ 1 \end{array} \!\right], \quad \left[\left[\! \begin{array}{r} 1 \\ 4 \\ 3 \\ 2 \\ 3 \end{array} \!\right]\right]_{\mathcal{B}} = \left[\! \begin{array}{r} 1 \\ 4 \\ 2 \end{array} \!\right]. \]
-
Additional information about the subspaces $\operatorname{Raw} A = \operatorname{Col}(A^\top)$ and $\operatorname{Col} A = \operatorname{Raw}(A^\top)$ can be obtained from the reduced row echelon form of $A^\top:$
\[
A^{\top} = \left[\! \begin{array}{rrrr}
1 & 2 & 2 & 1 \\
3 & 0 & 1 & 4 \\
2 & -2 & -1 & 3 \\
2 & 1 & 1 & 2 \\
2 & 1 & 2 & 3
\end{array} \!\right] \sim \cdots \sim \left[\!
\begin{array}{rrrr}
1 & 0 & 0 & 1 \\
0 & 1 & 0 & -1 \\
0 & 0 & 1 & 1 \\
0 & 0 & 0 & 0 \\
0 & 0 &0 & 0
\end{array}
\!\right].
\]
The reduced row echelon form of the matrix $A^\top$ provides additional treasure trove of information about matrix $A.$
- Since the matrix $A^\top$ and its reduced row echelon form have the same row space, the nonzero rows of the reduced row echelon form of $A^\top$ form a basis for $\operatorname{Col} A = \operatorname{Raw}(A^\top):$ \[ \operatorname{Col} A = \operatorname{Raw}(A^\top) = \operatorname{Span}\left\{ \left[\! \begin{array}{r} 1 \\ 0 \\ 0 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 1 \\ 0 \\ -1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \\1 \end{array} \!\right] \right\} \subseteq \mathbb{R}^4. \] Denote by $\mathcal{D}$ the basis in the above formula for $\operatorname{Col} A = \operatorname{Raw}(A^\top).$
- The pivot columns of $A^\top$ form a basis for the row space of $A$ \[ \operatorname{Raw} A = \operatorname{Col}(A^\top) = \operatorname{Span}\left\{ \left[\! \begin{array}{c} 1 \\ 3 \\ 2 \\ 2 \\ 2 \end{array} \!\right] , \left[\! \begin{array}{r} 2 \\ 0 \\ -2 \\ 1 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 2 \\ 1 \\ -1 \\ 1 \\ 2 \end{array} \!\right] \right\} \subseteq \mathbb{R}^5. \] Denote by $\mathcal{A}$ the basis in the above formula for the subspace $\operatorname{Raw} A = \operatorname{Col}(A^\top).$
- Finally, we use the RREF of $A^\top$ to determine a basis for $\operatorname{Nul} A.$ The homogeneous system of linear equations that corresponds to the RREF of $A$ is equivalent to the matrix equation $A\mathbf{x} = \mathbf{0}.$ Next we solve that system: \begin{alignat*}{5} &x_1 && && &&+x_4 &&= 0 \\ & &&\phantom{+}x_2 && &&-x_4 &&= 0 \\ & && &&\phantom{+}x_3 &&+x_4 &&= 0 \\ \end{alignat*} In this system variables $x_4 = s$ is free and the variables are given as $x_1 = -s$, $x_2 =s$, $x_3 = -s$. In vector form the solution is given by \[ \mathbf{x} = \left[\! \begin{array}{r} -s \\ s \\ -s \\ s \end{array} \!\right] = s \left[\! \begin{array}{r} -1 \\ 1 \\ -1 \\ 1 \end{array} \!\right]. \] Since $s$ is arbitrary real number it follows that \[ \operatorname{Nul}(A^\top) = \operatorname{Span}\left\{ \left[\! \begin{array}{r} -1 \\ 1 \\ -1 \\ 1 \end{array} \!\right] \right\} \subseteq \mathbb{R}^4. \]
- Now we have two bases for the subspace \[ \operatorname{Raw} A = \operatorname{Col}(A^\top)= \operatorname{Span} \underbrace{\left\{ \left[\! \begin{array}{r} 1 \\ 0 \\ -1 \\ 0 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 1 \\ 1 \\ 0 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 0 \\ 0 \\ 1 \\ -1 \end{array} \!\right] \right\}}_{\text{basis}\,\mathcal{B}} = \operatorname{Span} \underbrace{\left\{ \left[\! \begin{array}{c} 1 \\ 3 \\ 2 \\ 2 \\ 2 \end{array} \!\right] , \left[\! \begin{array}{r} 2 \\ 0 \\ -2 \\ 1 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 2 \\ 1 \\ -1 \\ 1 \\ 2 \end{array} \!\right] \right\}}_{\text{basis}\,\mathcal{A}} . \] Because of the special structure of the basis $\mathcal{B}$ it is easier to calculate the coordinates of the vectors in $\mathcal{A}$ relative to the basis $\mathcal{B}$. That is it is easier to calculate $\underset{\mathcal{B}\leftarrow\mathcal{A}}{P}$ by raw reducing the matrix \[ \left[\!\!\begin{array}{rrr|rrr} 1 & 0 & 0 & 1 & 2 & 2 \\ 0 & 1 & 0 & 3 & 0 & 1 \\ -1 & 1 & 0 & 2 & -2 & -1 \\ 0 & 0 & 1 & 2 & 1 & 1 \\ 1 & 1 & -1 & 2 & 1 & 2 \end{array} \!\!\right] \sim \cdots \sim \left[\!\!\begin{array}{rrr|rrr} 1 & 0 & 0 & 1 & 2 & 2 \\ 0 & 1 & 0 & 3 & 0 & 1 \\ 0 & 0 & 1 & 2 & 1 & 1 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \end{array} \!\!\right] \] Thus \[ \underset{\mathcal{B}\leftarrow\mathcal{A}}{P} = \left[\!\!\begin{array}{rrr} 1 & 2 & 2 \\ 3 & 0 & 1 \\ 2 & 1 & 1 \end{array} \!\!\right]. \] To find $\underset{\mathcal{A}\leftarrow\mathcal{B}}{P}$ we find the inverse of the last $3\!\times\!3$ matrix: \[ \left[\!\!\begin{array}{rrr|rrr} 1 & 2 & 2 & 1 & 0 & 0 \\ 3 & 0 & 1 & 0 & 1 & 0 \\ 2 & 1 & 1 & 0 & 0 & 1 \end{array} \!\!\right] \sim \cdots \sim \left[\!\!\begin{array}{rrr|rrr} 1 & 0 & 0 & -\tfrac{1}{3} & 0 & \tfrac{2}{3} \\ 0 & 1 & 0 & -\tfrac{1}{3} & -1 & \tfrac{5}{3} \\ 0 & 0 & 1 & 1 & 1 & -2 \end{array} \!\!\right] \] Thus, \[ \underset{\mathcal{A}\leftarrow\mathcal{B}}{P} = \frac{1}{3} \left[\!\!\begin{array}{rrr} -1 & 0 & 2 \\ -1 & -3 & 5 \\ 3 & 3 & -6 \end{array} \!\!\right]. \]
- Similarly, we have calculated two bases for $\operatorname{Col}A$: \[ \operatorname{Col} A = \operatorname{Row}(A^\top) = \operatorname{Span}\underbrace{\left\{ \left[\! \begin{array}{c} 1 \\ 2 \\ 2 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{c} 3 \\ 0 \\ 1 \\ 4 \end{array} \!\right] , \left[\! \begin{array}{c} 2 \\ 1 \\ 1 \\ 2 \end{array} \!\right] \right\}}_{\text{basis}\,\mathcal{C}} = \operatorname{Span}\underbrace{\left\{ \left[\! \begin{array}{r} 1 \\ 0 \\ 0 \\ 1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 1 \\ 0 \\ -1 \end{array} \!\right] , \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \\1 \end{array} \!\right] \right\}}_{\text{basis}\,\mathcal{D}} . \] Because of the special structure of the basis $\mathcal{D}$ it is easier to calculate the coordinates of the vectors in $\mathcal{C}$ relative to the basis $\mathcal{B}$. That is it is easier to calculate $\underset{\mathcal{B}\leftarrow\mathcal{A}}{P}$ by raw reducing the matrix \[ \left[\!\!\begin{array}{rrr|rrr} 1 & 0 & 0 & 1 & 3 & 2 \\ 0 & 1 & 0 & 2 & 0 & 1 \\ 0 & 0 & 1 & 2 & 1 & 1 \\ 1 & -1 & 1 & 1 & 4 & 2 \end{array} \!\!\right] \sim \cdots \sim \left[\!\!\begin{array}{rrr|rrr} 1 & 0 & 0 & 1 & 3 & 2 \\ 0 & 1 & 0 & 2 & 0 & 1 \\ 0 & 0 & 1 & 2 & 1 & 1 \\ 0 & 0 & 0 & 0 & 0 & 0 \end{array} \!\!\right] \] Thus \[ \underset{\mathcal{D}\leftarrow\mathcal{C}}{P} = \left[\!\!\begin{array}{rrr} 1 & 3 & 2 \\ 2 & 0 & 1 \\ 2 & 1 & 1 \end{array} \!\!\right]. \] Comparing the last matrix with $\underset{\mathcal{B}\leftarrow\mathcal{A}}{P}$ we see that $\underset{\mathcal{D}\leftarrow\mathcal{C}}{P} = \left(\underset{\mathcal{B}\leftarrow\mathcal{A}}{P}\right)^\top.$ Therefore \[ \underset{\mathcal{C}\leftarrow\mathcal{D}}{P} = \left(\underset{\mathcal{A}\leftarrow\mathcal{B}}{P}\right)^\top = \frac{1}{3} \left[\!\!\begin{array}{rrr} -1 & -1 & 3 \\ 0 & -3 & 3 \\ 2 & 5 & -6 \end{array} \!\!\right]. \]
- The concept of a basis of a finite-dimensional vector space is essential for everything that we discussed today. The definition of a basis on page 211.
- The Unique Representation Theorem on page 218.
- Let $\mathcal{B} = \{\mathbf{b}_1,\ldots,\mathbf{b}_n\}$ be a basis of a vector space $\mathcal{V}.$ Please understand the concept of the coordinates of a vector in $\mathcal{V}$ relative to the basis $\mathcal{B}.$ This definition is on page 218. Also understand the concept of the coordinate mapping determined by the basis $\mathcal{B}.$ Briefly, for a vector $\mathbb{v}$ in $\mathcal{V}$ we have \[ [\mathbb{v}]_{\mathcal{B}} = \left[\!\!\begin{array}{c} \alpha_1 \\ \alpha_2 \\ \vdots \\ \alpha_n \end{array}\!\!\right] \quad \text{if and only if} \quad \mathbb{v} = \alpha_1 \mathbf{b}_1 + \alpha_2 \mathbf{b}_2 + \cdots + \alpha_n \mathbf{b}_n \] The coordinate mapping determined by the basis $\mathcal{B}$ is the linear mapping with domain $\mathcal{V}$ and with the range $\mathbb{R}^n$ and for an arbitrary vector $\mathbb{v}$ in $\mathcal{V}$ it is defined by \[ \mathcal{V} \ni \mathbb{v} \longmapsto [\mathbb{v}]_{\mathcal{B}} = \left[\!\!\begin{array}{c} \alpha_1 \\ \alpha_2 \\ \vdots \\ \alpha_n \end{array}\!\!\right] \in \mathbb{R}^n. \]
- The fundamental theorem about the coordinate mapping is Theorem 8 on page 221. In Theorem 8 the book uses terminology one-to-one and onto. I would like to encourage you to use different terminology for these concepts. My preferred synonym for one-to-one is injection. My preferred synonym of onto is surjection.
-
Since the concepts of injection and surjection are basic concepts related to functions, I state their definitions here.
Definition. A function $f$ from $A$ to $B$, $f:A\to B$, is called surjection if it satisfies condition the following condition:
- For every $y \in B$ there exists $x \in A$ such that $f(x) = y$.
Definition. A function $f$ from $A$ to $B$, $f:A\to B$, is called injection if it satisfies the following condition
- For every $x_1, x_2 \in A$ we have that $f(x_1) = f(x_2)$ implies $x_1 = x_2$.
An equivalent formulation of the preceding condition is:
- For every $x_1, x_2 \in A$ we have that $x_1 \neq x_2$ implies $f(x_1) \neq f(x_2)$.
-
Together with the terminology injection and surjection goes the following terminology
Definition. A function $f:A\to B$ is called bijection if it it satisfies the following two conditions:
- For every $y \in B$ there exists $x \in A$ such that $f(x) = y$.
- For every $x_1, x_2 \in A$ we have that $f(x_1) = f(x_2)$ implies $x_1 = x_2$.
In other words, a function $f:A\to B$ is called bijection if it is both an injection and a surjection.
-
In the context of vector spaces the following is an important definition:
Definition. Let $\mathcal V$ and $\mathcal W$ be vector spaces. A linear bijection $T: \mathcal V \to \mathcal W$ is said to be an isomorphism.
-
Since I use different terminology, I will restate Theorem 8 from page 221 here.
Theorem 8. Let $n \in \mathbb{N}$. Let $\mathcal{B} = \{\mathbf{b}_1, \ldots, \mathbf{b}_n\}$ be a basis of a vector space $\mathcal V$. The coordinate mapping \[ \mathbb{v} \mapsto [\mathbb{v}]_\mathcal{B}, \qquad \mathbb{v} \in \mathcal V, \] is a linear bijection between the vector space $\mathcal V$ and the vector space $\mathbb{R}^n.$
Theorem 8. Let $n \in \mathbb{N}$. Let $\mathcal{B} = \{\mathbf{b}_1, \ldots, \mathbf{b}_n\}$ be a basis of a vector space $\mathcal V$. The coordinate mapping \[ \mathbb{v} \mapsto [\mathbb{v}]_\mathcal{B}, \qquad \mathbb{v} \in \mathcal V, \] is an isomorphism between the vector space $\mathcal V$ and the vector space $\mathbb{R}^n.$
-
The next two corollaries of Theorem 8 are useful tools in dealing with abstract vector spaces.
Corollary 1. Let $m, n \in \mathbb{N}$. Let $\mathcal{B} = \{\mathbf{b}_1, \ldots, \mathbf{b}_n\}$ be a basis of a vector space $\mathcal V$. Then the following statements are equivalent:
- Vectors $\mathbb{v}_1, \mathbb{v}_2, \ldots, \mathbb{v}_m \in \mathcal V$ are linearly independent
- The columns of the $n\times m$ matrix $\Bigl[ [\mathbb{v}_1]_\mathcal{B} \ [\mathbb{v}_2]_\mathcal{B} \ \cdots \ [\mathbb{v}_m]_\mathcal{B} \Bigr]$ are linearly independent.
Corollary 2. Let $m, n \in \mathbb{N}$. Let $\mathcal{B} = \{\mathbf{b}_1, \ldots, \mathbf{b}_n\}$ be a basis of a vector space $\mathcal V$. Then the following statements are equivalent:
- Vectors $\mathbb{v}_1, \mathbb{v}_2, \ldots, \mathbb{v}_m$ span $ \in \mathcal V$.
- The columns of the $n\times m$ matrix $\Bigl[ [\mathbb{v}_1]_\mathcal{B} \ [\mathbb{v}_2]_\mathcal{B} \ \cdots \ [\mathbb{v}_m]_\mathcal{B} \Bigr]$ span $\mathbb{R}^n$.
- Section 4.7 in the textbook talks about change of coordinates (they call it change of basis, but I think change of coordinates is more appropriate. Theorem 15 on page 242 is the main result. We will do examples on Tuesday.
-
We talked about the following concepts this week:
- The definition of an abstract vector space on page 192 and posted on January 6.
- The definition of a subspace on page 195
- The definition of the span of a set of vectors in the first paragraph of the subsection "A Subspace Spanned by a Set" starting on page 196. This definition in the set-builder notation reads: Let $m$ be a positive integer and let $\mathbf{v}_1,\ldots,\mathbf{v}_m$ be vectors in a vector space $\mathcal{V}.$ The span of vectors $\mathbf{v}_1,\ldots,\mathbf{v}_m$ is defined as \[ \operatorname{Span}\{\mathbf{v}_1,\ldots,\mathbf{v}_m\} = \bigl\{ \alpha_1 \mathbf{v}_1 + \cdots + \alpha_m \mathbf{v}_m : \alpha_1,\ldots,\alpha_m \in \mathbb{R} \bigr\}. \] This is a very important theorem: Theorem 1. $\operatorname{Span}\{\mathbf{v}_1,\ldots,\mathbf{v}_m\}$ is a subspace of $\mathcal{V}.$
- The definition of a linearly independent set on page 210. Next, I will restate this definition as an implication: An indexed set of vectors $\{\mathbf{v}_1,\ldots,\mathbf{v}_m\}$ in a vector space $\mathcal{V}$ is said to be linearly independent if the following implication holds \[ \alpha_1 \mathbf{v}_1 + \cdots + \alpha_m \mathbf{v}_m = \mathbf{0} \quad \text{implies} \quad \alpha_k = 0 \quad \text{for all} \quad k \in \{1,\ldots,m\}. \] There are many other equivalent ways of stating this definition. However, the above statement is the only formal definition which is easiest to use when we need to prove that certain vectors are linearly independent.
- The definition of a basis on page 211.
- Important examples of finite dimensional vector spaces are spaces of polynomials. For $n\in\mathbb{N}$ by $\mathbb{P}_n$ we denote the vector space of all polynomials of degree less or equal to $n.$ The most important step in understanding the vector space $\mathbb{P}_n$ is establishing that the monomials form a basis of this space. I wrote this webpage with a proof which uses only linear algebra. The proof which I give below for $\mathbb{P}_2$ uses calculus. The proof which is given in our textbook uses the Fundamental Theorem of Algebra (which is more difficult to prove).
-
The friendliest among spaces $\mathbb{P}_n$ is the spaces $\mathbb{P}_2$. Below I explore some of the properties of $\mathbb{P}_2$.
- $\mathbb{P}_2$ denotes the vector space of all polynomials of degree less or equal $2.$ That is, in set-builder notation, \[ \mathbb{P}_2 = \bigl\{a_0 + a_1 x +a_2 x^2 \, : \, a_0, a_1, a_2 \in \mathbb{R} \bigr\}. \] Recall that the constant polynomial $1$ is a polynomial in $\mathbb{P}_2$. To get this polynomial in the above set-builder notation we take $a_0 = 1,$ $a_1 = 0,$ and $a_2 = 0.$ To get the polynomial $x$ in the above set-builder notation we take $a_0 = 0,$ $a_1 = 1,$ and $a_2 = 0.$ Similarly, to get the square polynomial $x^2$ in the above set-builder notation we take $a_0 = 0,$ $a_1 = 0,$ and $a_2 = 1.$ Using the concept of the span the above expression for $\mathbb{P}_2$ in set-builder notation can be written using the concept of the span as \[ \mathbb{P}_2 = \operatorname{Span}\bigl\{ 1, x, x^2 \bigr\}. \]
- As you probably learned in Math 204 the polynomials $1, x, x^2$ are linearly independent.
- Here is a proof that the polynomials $1, x, x^2$ are linearly independent in the vector space ${\mathbb P}_2$. Assume that $\alpha_1,$ $\alpha_2,$ and $\alpha_3$ are scalars in $\mathbb{R}$ such that \[ \require{bbox} \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1\cdot 1 + \alpha_2 x + \alpha_3 x^2 =0 \quad \text{for all} \quad x \in \mathbb{R}}. \] The objective here is to prove \[ \bbox[5px, #FF4444, border: 1pt solid red]{\alpha_1 = 0, \quad \alpha_2 =0, \quad \alpha_3 = 0}. \] Consider the left-hand side of the above green identity as a function of $x$ and take the derivative with respect to $x$. We obtain \[ \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_2 + 2 \alpha_3 x =0 \quad \text{for all} \quad x \in \mathbb{R}}. \] Again, consider the left-hand side of the above green identity as a function of $x$ and take the derivative with respect to $x$. We obtain \[ \bbox[5px, #88FF88, border: 1pt solid green]{2 \alpha_3 =0 \quad \text{for all} \quad x \in \mathbb{R}}. \] Substituting $x=0$ in the first two green identities and dividing the third green equality by $2$ we obtain \[ \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1 = 0, \quad \alpha_2 =0, \quad \alpha_3 = 0}. \] In this way we have greenifyed the red statement. That is, we proved it.
- Here is an alternative proof that the polynomials $1, x, x^2$ are linearly independent in the vector space ${\mathbb P}_2$. Assume that $\alpha_1,$ $\alpha_2,$ and $\alpha_3$ are scalars in $\mathbb{R}$ such that \[ \require{bbox} \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1\cdot 1 + \alpha_2 x + \alpha_3 x^2 =0 \quad \text{for all} \quad x \in \mathbb{R}}. \] The objective here is to prove \[ \bbox[5px, #FF4444, border: 1pt solid red]{\alpha_1 = 0, \quad \alpha_2 =0, \quad \alpha_3 = 0}. \] The above green identity holds for all $x\in\mathbb{R}.$ In particular it holds for specific $x=-1,$ $x=0,$ and $x=1.$ That is, we have \[ \bbox[5px, #88FF88, border: 1pt solid green]{ \begin{array}{lr} \alpha_1 - \alpha_2 +\alpha_3 &=0 \\ \alpha_1 &=0 \\ \alpha_1 + \alpha_2 +\alpha_3 &=0 \\ \end{array} } \] The last green box contains a homogeneous system of linear equations which can be written in a matrix form as \[ \bbox[5px, #88FF88, border: 1pt solid green]{ \left[\!\begin{array}{rrr} 1 & -1 & 1 \\ 1 & 0 & 0 \\ 1 & 1 & 1 \end{array}\!\right] \left[\!\begin{array}{c} \alpha_1 \\ \alpha_2 \\ \alpha_3 \end{array}\!\right] = \left[\!\begin{array}{c} 0 \\ 0 \\ 0 \end{array}\!\right] } \] Since the determinant of the above $3\!\times\!3$ matrix is $2$, the above homogeneous equation has only the trivial solution. That is, \[ \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1 = 0, \quad \alpha_2 =0, \quad \alpha_3 = 0}. \] In this way we have greenifyed the red statement. That is, we proved it.
- Hence, \[ \mathbb{P}_2 = \operatorname{Span}\bigl\{ 1, x, x^2 \bigr\} \] and $\mathcal{M} = \bigl\{ 1, x, x^2 \bigr\}$ is a basis for $\mathbb{P}_2.$ I denoted this basis by $\mathcal{M}$ since the polynomials $1,$ $x,$ $x^2$ are called monomials.
-
Let us now look at few subspaces of $\mathbb{P}_2.$ First consider the set
\[
\mathcal{H}_0 = \bigl\{ \mathbf{p} \in \mathbb{P}_2 \, : \, \mathbf{p}(0) = 0 \bigr\}.
\]
That is, by $\mathcal{H}_0$ we denote the set of all polynomials in $\mathbb{P}_2$ which have one root equal to $0.$ For example the polynomial $\mathbf{q}_1(x) = x$ is in $\mathcal{H}_0.$ Similarly, $\mathbf{q}_2(x) = x^2$ is also in $\mathcal{H}_0.$
- Please use the definition of the concept of a subspace to prove that $\mathcal{H}_0$ is a subspace of $\mathbb{P}_2.$
- The following equivalence is clear: \[ a_0 + a_1 x + a_2 x^2 \in \mathcal{H}_0 \quad \text{if and only if} \quad a_0 = 0. \] Therefore \[ \mathcal{H}_0 = \bigl\{a_1 x + a_2 x^2 \, : \, a_1, a_2 \in \mathbb{R} \bigr\}. \] Since \[ \bigl\{a_1 x + a_2 x^2 \, : \, a_1, a_2 \in \mathbb{R} \bigr\} = \operatorname{Span}\bigl\{ x, x^2 \bigr\}, \] we have that \[ \mathcal{H}_0 = \operatorname{Span}\bigl\{ x, x^2 \bigr\}. \] Here we expressed $\mathcal{H}_0$ as a span of two polynomials. By Theorem 1 each span is a subspace. Therefore, this is alternative proof that $\mathcal{H}_0$ is a subspace.
- Since the set $\bigl\{ x, x^2 \bigr\}$ is linearly independent and since $\bigl\{ x, x^2 \bigr\}$ spans $\mathcal{H}_0$ we have that $\bigl\{ x, x^2 \bigr\}$ is a basis for $\mathcal{H}_0.$
- I recommend that you look into learning LaTeX which is a superior typesetting system for writing math papers. I created Getting Started with LaTeX page to help you with this.
- Here is a simple LaTeX sample document in which I prove an interesting inequality.
- Here is a LaTeX assignment template which you can use to write your assignments.
- If you need help in starting with LaTeX feel free to ask me for help. I consider it as important as learning one nice piece of mathematics. And I want to help you with that, not only because that is my job, but more because I deeply believe that both math - through learning rigorous thinking - and professional writing skills - supported by rigorous thinking - will help you in your life more than anything else.
-
In this item, I recall the definition of a vector space as I stated it in class. In the definition below $\times$ denotes the Cartesian product between two sets.
Definition. A nonempty set $\mathcal{V}$ is said to be a vector space over $\mathbb R$ if it satisfies the following 10 axioms.
Axiom 1. (AE) There exists a function $+: \mathcal{V}\!\times\!\mathcal{V} \to \mathcal{V}.$That is, for every $u \in \mathcal{V}$ and every $v \in \mathcal{V}$ there exists a unique $u+v \in \mathcal{V}$ which is called the sum of $u$ and $v.$Axiom 2. (AA) For all $u, v, w \in \mathcal{V}$ we have $u+(v+w) = (u+v)+w$Axiom 3. (AC) For all $u, v \in \mathcal{V}$ we have $u+v = v+u$Axiom 4. (AZ) There exists $0_{\mathcal{V}} \in \mathcal{V}$ such that for all $v \in \mathcal{V}$ we have $v+0_{\mathcal{V}} = v$Axiom 5. (AO) For all $v \in \mathcal{V}$ there exists $-v \in \mathcal{V}$ such that $v+(-v) = 0_{\mathcal{V}}$Axiom 6. (SE) There exists a function $\cdot: \mathbb{R}\!\times\!\mathcal{V} \to \mathcal{V}.$That is, for every real number $\alpha \in \mathbb R$ and every $v \in \mathcal{V}$ there exists a unique $\alpha v \in \mathcal{V}$ which is called the scaling of the vector $v$ by the scalar $\alpha.$Axiom 7. (SA) For all $\alpha, \beta \in \mathbb R$ and all $v \in \mathcal{V}$ we have $\alpha (\beta v) = (\alpha\beta) v$Axiom 8. (SD) For all $\alpha, \beta \in \mathbb R$ and all $v \in \mathcal{V}$ we have $(\alpha +\beta) v = \alpha v + \beta v$Axiom 9. (SD) For all $\alpha \in \mathbb R$ and all $u, v \in \mathcal{V}$ we have $\alpha (u + v) = \alpha u + \alpha v$Axiom 10. (S0) For all $v \in \mathcal{V}$ we have $1 v = v$Explanation of the abbreviations: AE--addition exists, AA--addition is associative, AC--addition is commutative, AZ--addition has zero, AO--addition has opposites, SE-- scaling exists, SA--scaling is associative, SD--scaling distributes over addition of real numbers, SD--scaling distributes over addition of vectors, SO--scaling with one.
- In the above Definition we use the same symbol $+$ to denote two different additions: one addition is the addition of real numbers, the other addition is the addition of vectors in the vector space $\mathcal{V}$. Similarly, the usage of the blank space between two symbols is ambiguous; between two real numbers the blank space means the multiplication of two real numbers, while between a real number and a vector in $\mathcal{V}$ the blank space means scaling of that vector by a real number. As a learner you should pay attention and make sure that you understand the meaning of all the symbols in the formulas that you are dealing with.
-
Let us introduce some "funny'' names for the algebraic operations that appear in the above Definition.
\begin{alignat*}{2}
\mathbf{\mathsf{VectorPlus}}:& \ \mathcal{V}\!\times\!\mathcal{V} \to \mathcal{V}, \quad &
\mathbf{\mathsf{Scale}}:& \ \mathbb{R}\!\times\!\mathcal{V} \to \mathcal{V} \\
\mathbf{\mathsf{Plus}}:& \ \mathbb{R}\!\times\!\mathbb{R} \to \mathbb{R}, & \qquad
\mathbf{\mathsf{Times}}:& \ \mathbb{R}\!\times\!\mathbb{R} \to \mathbb{R}.
\end{alignat*}
Thus, for $u,v \in \mathcal{V}$ the sum of the vectors $u$ and $v$ is denoted by $\mathbf{\mathsf{VectorPlus}}(u,v)$, for $\alpha \in \mathbb{R}$ and $v \in \mathcal{V}$ the scaling of the vector $v$ by $\alpha$ is denoted by $\mathbf{\mathsf{Scale}}(\alpha,v)$, for $\alpha, \beta \in \mathbb{R}$ the sum of the real numbers $\alpha$ and $\beta$ is denoted by $\mathbf{\mathsf{Plus}}(\alpha,\beta)$, and for $\alpha, \beta \in \mathbb{R}$ the product of the real numbers $\alpha$ and $\beta$ is denoted by $\mathbf{\mathsf{Times}}(\alpha,\beta)$.
Just to clarify, in this notation we have $\mathbf{\mathsf{Plus}}(2,3) = 5$ and $\mathbf{\mathsf{Times}}(2,3) = 6$. The distributive law for real numbers in this notation reads: for all real numbers $\alpha, \beta$ and $\gamma$ we have \[ \mathbf{\mathsf{Times}}\bigl(\alpha, \mathbf{\mathsf{Plus}}(\beta,\gamma) \bigr) = \mathbf{\mathsf{Plus}}\bigl( \mathbf{\mathsf{Times}}(\alpha,\beta) , \mathbf{\mathsf{Times}}(\alpha,\gamma) \bigr) \]
Exercise. Rewrite the axioms SA, SD, SD, and SO using the notation for the algebraic operations introduced above.
- The information sheet
-
We will start with a review. Please review
- The definition of an abstract vector space in Section 4.1, page 192.
- The definition a linearly independent set and the definition of a basis in Section 4.3; Examples 3, 4, 5, 6 and 10; Practice Problems 1, 2, 3, Exercises 1-8 and 38.
- Section 4.4: Theorem 7 (the unique representation theorem), the definition of coordinates with respect to a basis, the definition of a change-of-coordinates matrix on page 249 and the definition and the properties of a coordinate mapping; Examples 1, 2, 4, 5, 6; Practice Problems 1, 2; Exercises 3, 4, 5, 7, 9, 10, 11, 13, 18, 21, 32.
- Section 4.5: Theorem 10, the definition of a finite-dimensional vector space and its dimension and the Basis Theorem; Examples 1, 2, 3, 4; Practice Problems 1, 2; Exercises 2, 3, 7, 22, 24, and 34.
- Section 4.7 Change of Basis. Suggested exercises are 2, 3, 4, 6, 8, 9, 11, 12, 15, 16, 19 (you do not need a calculator for this problem).
-
What is the oldest linear algebra problem?
-
Clay tablet VAT 8389 from the Old Babylonian period, from 2000 to 1600 BC, contains what is believed to be the earliest word problem that can be interpreted as a system of linear equations:
A translation of this word problem into a system of linear equations is as follows: \begin{alignat*}{4} &x_1 & &\ + &x_2 & = 1800 \\ \tfrac{2}{3} &x_1 & &- \tfrac{1}{2} &x_2 & = \phantom{1}500. \end{alignat*} -
Problem 40 of the Rhind papyrus which is dated to 1550 BC is:
Denote by $x_1$ the smallest number and by $x_2$ the common difference. After simplification the above problem translates into the following system of linear equations: \begin{alignat*}{5} 5 &x_1 & & + 10 &x_2 & = 100 \\ \tfrac{11}{7} &x_1 & & - \phantom{1}\tfrac{2}{7} &x_2 & = \phantom{10}0. \end{alignat*} -
Most importantly for us, the oldest known treatment of systems of linear equations from antiquity which resembles the methods that we will use in this class is in Chapter 8 of the Chinese textbook Nine Chapters of the Mathematical Art which is at least 1800 years old.
-
Clay tablet VAT 8389 from the Old Babylonian period, from 2000 to 1600 BC, contains what is believed to be the earliest word problem that can be interpreted as a system of linear equations: