Theorem. Let $n \in \mathbb{N}$ and let $A$ be an $n\!\times\!n$ matrix. The matrix $A$ is diagonalizable if and only if there exists a basis of $\mathbb{R}^n$ which consists of eigenvectors of $A.$
-
On Friday we discussed the following problem: Consider the matrix
\[
A =
\begin{bmatrix}
5 & x & -2 & 1 \\
0 & 3 & x & 2 \\
0 & 0 & 5 & 3 \\
0 & 0 & 0 & 1
\end{bmatrix}
\]
where \(x \in \mathbb{R}\). Find the values of $x \in \mathbb{R}$ such that the matrix $A$ is diagonalizable.
-
This problem is an exercise in understanding of Theorem 7 in Section 5.3: Diagonalization:

-
To apply Theorem 7 we first calculate the characteristic polynomial of \(A\):
\begin{align*}
\det( A -\lambda I_4) & =
\left| \begin{array}{cccc}
5 - \lambda & x & -2 & 1 \\[6pt]
0 & 3 - \lambda & x & 2 \\[6pt]
0 & 0 & 5 - \lambda & 3 \\[6pt]
0 & 0 & 0 & 1 - \lambda
\end{array} \right| \\[10pt]
& = (5 - \lambda)^2 (3 - \lambda) (1 - \lambda).
\end{align*}
The eigenvalues of \(A\) are the roots of its characteristic polynomial. An important aspect of Theorem 7 is the consideration of the multiplicities of these roots. Since the characteristic polynomial of \(A\) is \((5 - \lambda)^2 (3 - \lambda) (1 - \lambda)\), the eigenvalues of \(A\) are \(5\), \(3\) and \(1\). Their multiplicities are:
- The multiplicity of \(5\) as a root of \((5 - \lambda)^2 (3 - \lambda) (1 - \lambda)\) is \(2\),
- The multiplicity of \(3\) as a root of \((5 - \lambda)^2 (3 - \lambda) (1 - \lambda)\) is \(1\),
- The multiplicity of \(1\) as a root of \((5 - \lambda)^2 (3 - \lambda) (1 - \lambda)\) is \(1\).
-
Recall that the eigenspaces corresponding to these three eigenvalues are \[ \operatorname{Nul}( A - 5 I_4), \quad \operatorname{Nul}( A - 3 I_4), \quad \operatorname{Nul}( A - 1 I_4). \] It follows form item a. in Theorem 7 that \begin{alignat*}{2} 1 &\leq \dim \operatorname{Nul}( A - 5 I_4) & & \leq 2, \\ 1 &\leq \dim \operatorname{Nul}( A - 3 I_4) & & \leq 1, \\ 1 &\leq \dim \operatorname{Nul}( A - 1 I_4) & & \leq 1. \end{alignat*} Consequently, \[ \dim \operatorname{Nul}( A - 3 I_4) = 1, \quad \dim \operatorname{Nul}( A - 1 I_4 ) = 1 \] In other words, each of these two eigenspaces is spanned by a single eigenvector.
For the eigenspace \(\operatorname{Nul}( A - 5 I_4)\) we have two options \[ \dim \operatorname{Nul}( A - 5 I_4) = 1, \quad \text{or} \quad \dim \operatorname{Nul}( A - 5 I_4) = 2. \]
-
By item b. in Theorem 7: The given matrix \(A\) is diagonalazable if and only if the sum of the dimensions of the eigenspaces equals \(4\).
Since \[ 2 + 1 + 1 = 4, \] the given matrix \(A\) is diagonalizable if and only if \[ \dim \operatorname{Nul}( A - 5 I_4) = 2. \] Recall that the dimension of a null space of a matrix is the number of nonpivot columns in the RREF of that matrix. See Section 4.5 page 230
 So, we need to choose \(x \in \mathbb{R}\) such that the Reduced Row Echelon Form of the matrix
\[
\begin{bmatrix}
5 & x & -2 & 1 \\
0 & 3 & x & 2 \\
0 & 0 & 5 & 3 \\
0 & 0 & 0 & 1
\end{bmatrix} - 5 \begin{bmatrix}
1 & 0 & 0 & 0 \\
0 & 1 & 0 & 0 \\
0 & 0 & 1 & 0 \\
0 & 0 & 0 & 1
\end{bmatrix} = \begin{bmatrix}
0 & x & -2 & 1 \\
0 & -2 & x & 2 \\
0 & 0 & 0 & 3 \\
0 & 0 & 0 & -4
\end{bmatrix}
\]
has two free variables.
So, we need to choose \(x \in \mathbb{R}\) such that the Reduced Row Echelon Form of the matrix
\[
\begin{bmatrix}
5 & x & -2 & 1 \\
0 & 3 & x & 2 \\
0 & 0 & 5 & 3 \\
0 & 0 & 0 & 1
\end{bmatrix} - 5 \begin{bmatrix}
1 & 0 & 0 & 0 \\
0 & 1 & 0 & 0 \\
0 & 0 & 1 & 0 \\
0 & 0 & 0 & 1
\end{bmatrix} = \begin{bmatrix}
0 & x & -2 & 1 \\
0 & -2 & x & 2 \\
0 & 0 & 0 & 3 \\
0 & 0 & 0 & -4
\end{bmatrix}
\]
has two free variables.
- Row reduce: \begin{align*} \begin{bmatrix} 0 & x & -2 & 1 \\ 0 & -2 & x & 2 \\ 0 & 0 & 0 & 3 \\ 0 & 0 & 0 & -4 \end{bmatrix} & \sim \begin{bmatrix} 0 & 1 & -\frac{x}{2} & -1 \\ 0 & x & -2 & 1 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & -4 \end{bmatrix} \\[7pt] & \sim \begin{bmatrix} 0 & 1 & -\frac{x}{2} & 0 \\ 0 & 0 & -2 + \frac{x^2}{2} & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 \end{bmatrix} \\[7pt] \end{align*} Thus, \[ \dim \operatorname{Nul}( A - 5 I_4) = 2 \] if and only if \(-2 + \frac{x^2}{2} = 0\). That is, \(x^2 = 4\). Equivalently, \(x=-2\) or \(x=2\).
- In conclusion, the given matrix \(A\) is diagonalizable if and only if \(x=-2\) or \(x=2\).
-
This problem is an exercise in understanding of Theorem 7 in Section 5.3: Diagonalization:
- A little more complicated problem in the same spirit is as follows: Consider the matrix \[ A = \begin{bmatrix} 1 & 2 & y & 0 \\ 0 & 2 & x & -2 \\ 0 & 0 & 1 & y \\ 0 & 0 & 0 & 2 \end{bmatrix} \] where \(x, y \in \mathbb{R}\). Find all pairs $(x,y) \in \mathbb{R}^2$ such that the matrix $A$ is diagonalizable.
-
A simpler problem in the same spirit is as follows: Consider the matrix \[ \begin{bmatrix} 1 & x & 4 \\ 0 & 2 & x \\ 0 & 0 & 1 \end{bmatrix} \] where \(x \in \mathbb{R}\). Find all pairs $x \in \mathbb{R}$ such that the matrix $A$ is diagonalizable.
For this matrix, you can choose a specific value of \(x\), such as \(x=0\) and calculate the eigenvalues and eigenvectors to assess whether the matrix is diagonalizable. Next, you can determine the values of \(x\) that make the matrix diagonalizable and compute its diagonalization. While these tasks can be performed manually for the given \(4\times 4\) matrices, they are significantly more time-consuming to complete by hand.
-
Related to Problem 5 on the Assignment, today we discussed all the information about a matrix that one can read from its Reduced Row Echelon Form. In fact we revied the webpage that I wrote about it:
- In An Ode to Reduced Row Echelon Form we study the matrix \(A\) and its Reduced Row Echelon Form: \[ A = \begin{bmatrix} 1 & 1 & 4 & 1 & 6 \\ 2 & 1 & 3 & 0 & 4 \\ 3 & 1 & 2 & 1 & 8 \\ 4 & 1 & 1 & 0 & 6 \end{bmatrix} \ \sim \cdots \sim \ \begin{bmatrix} 1 & 0 & -1 & 0 & 1 \\ 0 & 1 & 5 & 0 & 2 \\ 0 & 0 & 0 & 1 & 3 \\ 0 & 0 & 0 & 0 & 0 \end{bmatrix}. \]
- One conclusion from the considerations in An Ode to Reduced Row Echelon Form is that the above RREF yields the following fact: \[ \text{The set} \quad \left\{\begin{bmatrix} 1 \\ 2 \\ 3 \\ 4 \end{bmatrix}, \begin{bmatrix} 1 \\ 1 \\ 1 \\ 1 \end{bmatrix},\begin{bmatrix} 1 \\ 0 \\ 1 \\ 0 \end{bmatrix} \right\} \quad \text{is a basis for} \quad \operatorname{Col}(A). \] In words: the pivot columns of \(A\) form a basis for \(\operatorname{Col}(A)\).
- Another conclusion from the considerations in An Ode to Reduced Row Echelon Form is that the above RREF yields the following fact: \[ \text{The set} \quad \left\{\begin{bmatrix} 1 \\ 0 \\ -1 \\ 0 \\ 1 \end{bmatrix}, \begin{bmatrix} 0 \\ 1 \\ 5 \\ 0 \\ 2 \end{bmatrix},\begin{bmatrix} 0 \\ 0 \\ 0 \\ 1 \\ 3\end{bmatrix} \right\} \quad \text{is a basis for} \quad \operatorname{Row}(A). \] In words: the nonzero rows of the RREF of \(A\) form a basis for \(\operatorname{Row}(A)\).
-
A novelty in Problem 5 on the Assignment is that new information about the column space and the row space of \(A\) can be deduced from the Reduced Row Echelon Form of the transpose of \(A\). Recall that
\[
\operatorname{Col}(A) = \operatorname{Row}(A^\top) \quad \text{and} \quad
\operatorname{Row}(A) = \operatorname{Col}(A^\top).
\]
- Using the reasoning in An Ode to Reduced Row Echelon Form, the matrix \(A^\top\) and its Reduced Row Echelon Form: \[ A^\top = \begin{bmatrix} 1 & 2 & 3 & 4 \\ 1 & 1 & 1 & 1 \\ 4 & 3 & 2 & 1 \\ 1 & 0 & 1 & 0 \\ 6 & 4 & 8 & 6 \end{bmatrix} \ \sim \cdots \sim \ \begin{bmatrix} 1 & 0 & 0 & -1 \\ 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix}. \] we deduce the following (please understand the reasoning behind these claims):
- \[ \text{The set} \quad \left\{\begin{bmatrix} 1 \\ 1 \\ 4 \\ 1 \\ 6 \end{bmatrix}, \begin{bmatrix} 2 \\ 1 \\ 3 \\ 0 \\ 4 \end{bmatrix},\begin{bmatrix} 3 \\ 1 \\ 2 \\ 1 \\ 8 \end{bmatrix} \right\} \quad \text{is a basis for} \quad \operatorname{Row}(A). \] In words: the pivot columns of \(A^\top\) form a basis for \(\operatorname{Row}(A)\).
- \[ \text{The set} \quad \left\{\begin{bmatrix} 1 \\ 0 \\ 0 \\ -1 \end{bmatrix}, \begin{bmatrix} 0 \\ 1 \\ 0 \\ 1 \end{bmatrix},\begin{bmatrix} 0 \\ 0 \\ 1 \\ 1 \end{bmatrix} \right\} \quad \text{is a basis for} \quad \operatorname{Col}(A). \] In words: the nonzero rows of the RREF of \(A^\top\) form a basis for \(\operatorname{Col}(A)\).
-
Below I want to present a change of coordinates matrix in a vector space of polynomials which requires only the Binomial Theorem. The Binomial Theorem is the theorem that you might have seen in a college algebra class: \begin{align*} (u+v)^1 & = u+v, \\ (u+v)^2 & = u^2+2\mkern 2mu u v + v^2, \\ (u+v)^3 & = u^3+ 3\mkern 2mu u^2 v + 3\mkern 2mu u v^2 + v^3,\\ (u+v)^4 & = u^4+ 4\mkern 2mu u^3 v + 6\mkern 2mu u^2 v^2 + 4\mkern 2mu u v^3 + v^4,\\ (u+v)^5 & = u^5+ 5\mkern 2mu u^4 v + 10\mkern 2mu u^3 v^2 + 10\mkern 2mu u^2 v^3 + 5\mkern 2mu u v^4 + v^5, \end{align*} and so on.
We do not need the general version of the Binomial Theorem here. But, since we mentioned it I write more about it in the last item in today's post.
-
Earlier we introduced the standard basis of a vector space of polynomials.
- For example, consider the vector space of all polynomials of degree less or equal to $4.$ This vector space of polynomials is denoted by $\mathbb{P}_4$. We have \[ \mathbb{P}_4 = \bigl\{\alpha_0 + \alpha_1 x + \alpha_2 x^2 + \alpha_3 x^3 + \alpha_4 x^4 \, : \, \alpha_0, \alpha_1, \alpha_2, \alpha_3, \alpha_4 \in \mathbb{R} \bigr\}, \] that is \[ \mathbb{P}_4 = \operatorname{Span}\bigl\{ 1, x, x^2, x^3, x^4 \bigr\}. \]
- Earlier we proved that the monomials \[ \mathcal{M} = \bigl\{ 1, x, x^2, x^3, x^4 \bigr\} \] are linearly independent. Therefore, $\mathcal{M}$ is a basis for $\mathbb{P}_4$. This basis is called the standard basis of a vector space of polynomials $\mathbb{P}_4$.
- Let us introduce another basis for $\mathbb{P}_4$. Let $a \in \mathbb{R}$ be any real number and consider the shifts of the monomials in $\mathcal{M}$: \[ \mathcal{S}_a = \bigl\{ 1, x-a, (x-a)^2, (x-a)^3, (x-a)^4 \bigr\}. \]
- Let us calculate the coordinates of the polynomials in $\mathcal{S}_a$ relative to the standard basis $\mathcal{M}_4$. To get the coefficients we apply the Binomial Theorem: \begin{align*} (x-a)^1 & = -a + x, \\ (x-a)^2 & = \phantom{-} a^2 - 2\mkern 2mu a x + x^2, \\ (x-a)^3 & = -a^3 + 3\mkern 2mu a^2 x - 3\mkern 2mu a x^2 + x^3,\\ (x-a)^4 & = \phantom{-} a^4 - 4\mkern 2mu a^3 x + 6\mkern 2mu a^2 x^2 - 4\mkern 2mu a x^3 + x^4. \end{align*} In the preceding four formulas we set \(u=x\) and \(v=-a\) in the Binomial Theorem.
- It follows from the preceding item that the coordinate vectors of the polynomials in $\mathcal{S}_a$ are as follows: \begin{align*} \Bigl[1\Bigr]_{\mathcal{M}} = \begin{bmatrix} 1 \\ 0 \\ 0 \\ 0 \\ 0 \end{bmatrix}, \quad & \Bigl[x-a\Bigr]_{\mathcal{M}} = \begin{bmatrix} -a \\ 1 \\ 0 \\ 0 \\ 0 \end{bmatrix}, \\ \Bigl[(x-a)^2\Bigr]_{\mathcal{M}} & = \begin{bmatrix} a^2 \\ -2a \\ 1 \\ 0 \\ 0 \end{bmatrix}, \ \Bigl[(x-a)^3\Bigr]_{\mathcal{M}} = \begin{bmatrix} -a^3 \\ 3 a^2 \\ -3 a \\ 1 \\ 0 \end{bmatrix}, \ \Bigl[(x-a)^4\Bigr]_{\mathcal{M}} = \begin{bmatrix} a^4 \\ -4a^3 \\ 6 a^2 \\ -4a \\ 1 \end{bmatrix}. \end{align*} Since the above five coordinate vectors are linearly independent, by Theorem 8 in Section 4.4 the polynomials in $\mathcal{S}_a$ are linearly independent. Since there are five linearly independent polynomials in $\mathcal{S}_a$ and \(5 = \dim \mathbb{P}_4\), by Theorem 12 in Section 4.5 the set $\mathcal{S}_a$ is a basis for $\mathbb{P}_4$. The change of coordinates matrix is \[ \underset{\mathcal{M}\leftarrow\mathcal{S}_a}{P} = \begin{bmatrix} 1 & -a & a^2 & -a^3 & a^4 \\ 0 & 1 & -2a & 3 a^2 & -4 a^3 \\ 0 & 0 & 1 & - 3 a & 6 a^2 \\ 0 & 0 & 0 & 1 & -4 a \\ 0 & 0 & 0 & 0 & 1 \end{bmatrix} \]
- The next task is to calculate the change of coordinates matrix $\displaystyle \underset{\mathcal{S}_a\leftarrow\mathcal{M}}{P}$. For this matrix we need the coordinate vectors: \[ \Bigl[1\Bigr]_{\mathcal{S}_a}, \quad \Bigl[x\Bigr]_{\mathcal{S}_a}, \quad \Bigl[x^2\Bigr]_{\mathcal{S}_a}, \quad \Bigl[x^3\Bigr]_{\mathcal{S}_a}, \quad \Bigl[x^4\Bigr]_{\mathcal{S}_a}. \] We use the fact that $x = a + (x-a)$ and apply the Binomial Theorem with \(u=a\) and \(v=(x-a)\): \begin{align*} x & = a + (x-a), \\ x^2 & = \bigl(a + (x-a)\bigr)^2 = a^2 + 2 a \mkern 2mu (x-a) + (x-a)^2, \\ x^3 & = \bigl(a + (x-a)\bigr)^3 = a^3 + 3 a^2 \mkern 2mu (x-a) + 3 a \mkern 2mu (x-a)^2 + (x-a)^3, \\ x^4 & = \bigl(a + (x-a)\bigr)^4 = a^4 + 4 a^3 \mkern 2mu (x-a) + 6 a^2 \mkern 2mu (x-a)^2 + 4 a \mkern 2mu (x-a)^3 + (x-a)^4. \end{align*}
- It follows from the preceding item that the coordinate vectors of the polynomials in $\mathcal{M}$ relative to the basis $\mathcal{S}_a$ are as follows: \begin{align*} \Bigl[1\Bigr]_{\mathcal{S}_a} = \begin{bmatrix} 1 \\ 0 \\ 0 \\ 0 \\ 0 \end{bmatrix}, \quad & \Bigl[x\Bigr]_{\mathcal{S}_a} = \begin{bmatrix} a \\ 1 \\ 0 \\ 0 \\ 0 \end{bmatrix}, \\ \Bigl[x^2\Bigr]_{\mathcal{S}_a} & = \begin{bmatrix} a^2 \\ 2a \\ 1 \\ 0 \\ 0 \end{bmatrix}, \ \Bigl[x^3\Bigr]_{\mathcal{S}_a} = \begin{bmatrix} a^3 \\ 3 a^2 \\ 3 a \\ 1 \\ 0 \end{bmatrix}, \ \Bigl[x^4\Bigr]_{\mathcal{S}_a} = \begin{bmatrix} a^4 \\ 4a^3 \\ 6 a^2 \\ 4a \\ 1 \end{bmatrix}. \end{align*} Therefore, the change of coordinates matrix $\displaystyle \underset{\mathcal{S}_a\leftarrow\mathcal{M}}{P}$ is \[ \underset{\mathcal{S}_a\leftarrow\mathcal{M}}{P} = \begin{bmatrix} 1 & a & a^2 & a^3 & a^4 \\ 0 & 1 & 2a & 3 a^2 & 4 a^3 \\ 0 & 0 & 1 & 3 a & 6 a^2 \\ 0 & 0 & 0 & 1 & 4 a \\ 0 & 0 & 0 & 0 & 1 \end{bmatrix}. \]
- To celebrate and verify our work we calculate \[ \Bigl(\underset{\mathcal{M}\leftarrow\mathcal{S}_a}{P}\Bigr) \Bigl( \underset{\mathcal{S}_a\leftarrow\mathcal{M}}{P} \Bigr) = \begin{bmatrix} 1 & -a & a^2 & -a^3 & a^4 \\ 0 & 1 & -2a & 3 a^2 & -4 a^3 \\ 0 & 0 & 1 & - 3 a & 6 a^2 \\ 0 & 0 & 0 & 1 & -4 a \\ 0 & 0 & 0 & 0 & 1 \\ \end{bmatrix} \begin{bmatrix} 1 & a & a^2 & a^3 & a^4 \\ 0 & 1 & 2a & 3 a^2 & 4 a^3 \\ 0 & 0 & 1 & 3 a & 6 a^2 \\ 0 & 0 & 0 & 1 & 4 a \\ 0 & 0 & 0 & 0 & 1 \end{bmatrix} = \begin{bmatrix} 1 & 0 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 1 \end{bmatrix} \]
-
We do not need the general version of the Binomial Theorem here, but, since we mentioned it I want to introduce you to the important concepts related to the Binomial Theorem. Those are the concept of factorial, the concept of a binomial coefficient, and, most importantly, the concept of recursion.
-
In general, if $n \in \mathbb{N}$ we have \begin{align*} (u+v)^n & = \sum_{k=0}^n \binom{n}{k} \mkern 2mu u^{n-k} v^k \\ & = u^n + n \mkern 2mu u^{n-1} v + \frac{n(n-1)}{2}\mkern 2mu u^{n-2} v^2 + \cdots + \frac{n(n-1)}{2}\mkern 2mu u^{2} v^{n-2} + n\mkern 2mu u v^{n-1} + v^n. \end{align*}
-
In the above formula, for \( n, k \in \{0\}\cup\mathbb{N}\) with \(k \leq n \), the symbol \( \displaystyle \binom{n}{k} \) (read as "n choose k") denotes the Binomial coefficient. The definition is:
\[ \binom{n}{k} = \frac{n!}{k! \, (n-k)!}, \]
where for \( m \in \mathbb{N} \), \( m! \) (read as "m factorial") is the product of all positive integers up to \( m \). By convention \( 0! = 1 \).
- Recursive definitions of functions defined on nonnegative integers are at the cornerstone of mathematics. Therefore, it is appropriate here to point out to the recursive definitions of the factorial and the binomial coefficients.
-
The recursive definition of the factorial is as follows:
The Base Case: \(0!=1\)
The Recursive Step: For all \(m\in\mathbb{N}\) we set \(m! = \bigl( (m-1)! \bigr) \mkern 2px m\).
For more details, see Factorial.
-
The recursive definition of the binomial coefficients is as follows:
The Base Case: \begin{equation*} \text{For all} \ \ n \in \{0\}\cup\mathbb{N} \quad \text{we set} \quad \binom{n}{0} = 1 \quad \text{and} \quad \binom{n}{n} = 1. \end{equation*} The Recursive Step: \begin{equation*} \text{For all} \ \ n \in \mathbb{N} \ \ \text{and} \ \ k \in \{1,\ldots,n\} \quad \text{we set} \quad \binom{n+1}{k} = \binom{n}{k-1} + \binom{n}{k}. \end{equation*} At each line below, the recursive step with specific values for \(n\) and \(k\) and the previously evaluated values (that is why it is called a recursion, see the next item below) for the binomial coefficients yields:
\begin{alignat*}{2} &\text{For } n=2, \ k=1 \qquad &&\binom{2}{1} = \binom{1}{0} + \binom{1}{1} = 1 + 1 = 2, \\ &\text{For } n=3, \ k=1 &&\binom{3}{1} = \binom{2}{0} + \binom{2}{1} = 1 + 2 = 3, \\ &\text{For } n=3, \ k=2 &&\binom{3}{2} = \binom{2}{1} + \binom{2}{2} = 2 + 1 = 3, \\ &\text{For } n=4, \ k=1 &&\binom{4}{1} = \binom{3}{0} + \binom{3}{1} = 1 + 3 = 4, \\ &\text{For } n=4, \ k=2 &&\binom{4}{2} = \binom{3}{1} + \binom{3}{2} = 3 + 3 = 6, \\ &\text{For } n=4, \ k=3 &&\binom{4}{3} = \binom{3}{2} + \binom{3}{3} = 3 + 1 = 4, \\ &\text{For } n=5, \ k=1 &&\binom{5}{1} = \binom{4}{0} + \binom{4}{1} = 1 + 4 = 5, \\ &\text{For } n=5, \ k=2 &&\binom{5}{2} = \binom{4}{1} + \binom{4}{2} = 4 + 6 = 10, \\ &\text{For } n=5, \ k=3 &&\binom{5}{3} = \binom{4}{2} + \binom{4}{3} = 6 + 4 = 10, \\ &\text{For } n=5, \ k=4 &&\binom{5}{4} = \binom{4}{3} + \binom{4}{4} = 4 + 1 = 5, \\ & & & \quad \quad \mkern 12px \vdots \end{alignat*}
For more details about this recursion, see Pascal's triangle.
-
- In this file, I provide sample problems formatted similarly to those on the final exam. These problems cover only the topics that were not included on the first two exams. Note that some sample problems contain more items than would appear on the actual exam. Please note that the final exam is comprehensive.
- Problems 13 and 14 in Section 4.7 deal with the change of coordinates for polynomials in $\mathbb{P}_2.$
-
The most important tool when working with finite-dimensional abstract vector spaces is the concept of a coordinate mapping introduced in Section 4.4 on page 221. Theorem 8 on page 221 and Problems 23-26 on page 225 provide theoretical background on how a coordinate mapping works. How to use a coordinate mapping is explained in Examples 5 and 6.
To use a coordinate mapping on a vector space we need to know a basis for that vector space.
-
The standard basis for the vector space $\mathbb{P}_3$ of polynomials is the set of all monomials: \[ \mathcal{M} =\bigl\{ 1, \ x, \ x^2, \ x^3 \bigr\}. \] The corresponding coordinate mapping is \[ \bigl[a_0 + a_1 x + a_2 x^2 + a_3 x^3 \bigr]_{\mathcal{M}} = \left[\!\begin{array}{c} a_0 \\ a_1 \\ a_2 \\ a_3 \end{array}\!\right] \in \mathbb{R}^4. \]
-
The standard basis for the vector space $\mathbb{R}^{2\times 2}$ of $2\!\times\!2$ matrices is the set of matrices: \[ \mathcal{S} = \left\{ \left[\!\begin{array}{cc} 1 & 0 \\ 0 & 0 \end{array}\!\right], \left[\!\begin{array}{cc} 0 & 1 \\ 0 & 0 \end{array}\!\right], \left[\!\begin{array}{cc} 0 & 0 \\ 1 & 0 \end{array}\!\right], \left[\!\begin{array}{cc} 0 & 0 \\ 0 & 1 \end{array}\!\right] \right\}. \] The corresponding coordinate mapping is \[ \Biggl[ \left[\!\begin{array}{cc} a & b \\ c & d \end{array}\!\right] \Biggr]_{\mathcal{S}} = \left[\!\begin{array}{c} a \\ b \\ c \\ d \end{array}\!\right] \in \mathbb{R}^4. \]
-
-
The above coordinate mapping can be used to solve this problem: Let
\[
A = \left[\!\begin{array}{cc}
0 & 1 \\ 2 & 3 \end{array}\!\right].
\]
Find a basis for the following subspace of $\mathbb{R}^{2 \times 2}$:
\[
\mathcal{C}_A = \bigl\{X \in \mathbb{R}^{2\times 2} : AX = XA \bigr\}.
\]
- We proceed as follows: We set \[ X = \left[\!\begin{array}{cc} x_1 & x_2 \\ x_3 & x_4 \end{array}\!\right], \quad \text{that is} \quad \bigl[X\bigr]_{\mathcal{S}} = \left[\!\begin{array}{c} x_1 \\ x_2 \\ x_3 \\ x_4 \end{array}\!\right] \] and calculate \[ AX = \left[\!\begin{array}{cc} x_3 & x_4 \\ 2 x_1 + 3 x_3 & 2 x_2 + 3 x_4 \end{array}\!\right] = \left[\!\begin{array}{cc} 2x_2 & x_1 + 3 x_2 \\ 2 x_4 & x_3 + 3 x_4 \end{array}\!\right] = XA. \]
- Therefore $X \in \mathcal{H}$ if and only if $x_1, x_2, x_3, x_4$ satisfy the following system of linear equations: \begin{align*} x_3 & = 2 x_2 \\ x_4 & = x_1 + 3 x_2 \\ 2 x_1 + 3 x_3 & = 2 x_4 \\ 2 x_2 + 3 x_4 & = x_3 + 3 x_4. \end{align*} We can rewrite these four equations as a homogeneous linear system \begin{alignat*}{5} & & & 2x_2 & - &\phantom{3} x_3 & & & & = 0 \\ & x_1 & + & 3x_2 & & & -& \phantom{2} x_4 & & = 0 \\ 2 & x_1 & & & + & 3x_3 & - & 2x_4 & & = 0 \\ & & & 2x_2 & - &\phantom{3} x_3 & & & & = 0 \\ \end{alignat*}
- The matrix of this homogeneous system is \[ \left[\!\begin{array}{rrrr} 0 & 2 & -1 & 0 \\ 1 & 3 & 0 & -1 \\ 2 & 0 & 3 & -2 \\ 0 & 2 & -1 & 0 \end{array}\!\right]. \] We row reduce the above matrix to its RREF: \begin{align*} \left[\!\begin{array}{rrrr} 0 & 2 & -1 & 0 \\ 1 & 3 & 0 & -1 \\ 2 & 0 & 3 & -2 \\ 0 & 2 & -1 & 0 \end{array}\!\right] & \sim \left[\!\begin{array}{rrrr} 1 & 3 & 0 & -1 \\ 0 & -6 & 3 & 0 \\ 0 & 2 & -1 & 0 \\ 0 & 0 & 0 & 0 \end{array}\!\right] \\ & \sim \left[\!\begin{array}{rrrr} 1 & 3 & 0 & -1 \\ 0 & 1 & -1/2 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{array}\!\right] \\ & \sim \left[\!\begin{array}{rrrr} 1 & 0 & 3/2 & -1 \\ 0 & 1 & -1/2 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{array}\!\right] \\ \end{align*} From the RREF we see that \(x_3\) and \(x_4\) are free variables. To find the null space we set \(x_3 = s\) and \(x_4 = t\) and solve \begin{alignat*}{5} & x_1 & & & + \frac{3}{2} & x_3 & - & x_4 & & = 0 \\ & & & x_2 & - \frac{1}{2} & x_3 & & & & = 0. \end{alignat*} Hence, the solution in vector form is \[ \left[\!\begin{array}{c} x_1 \\ x_2 \\ x_3 \\ x_4 \end{array}\!\right] = \left[\!\begin{array}{c} - \frac{3}{2} s + t \\ \frac{1}{2} s \\ s \\ t \end{array}\!\right] = \frac{s}{2} \left[\!\begin{array}{c} - 3 \\ 1 \\ 2 \\ 0 \end{array}\!\right] + t \left[\!\begin{array}{c} 1 \\ 0 \\ 0 \\ 1 \end{array}\!\right] \] Thus, the null space of the homogeneous system is \[ \operatorname{Span}\left\{ \left[\!\begin{array}{c} -3 \\ 1 \\ 2 \\ 0 \end{array}\!\right], \left[\!\begin{array}{c} 1 \\ 0 \\ 0 \\ 1 \end{array}\!\right] \right\}. \]
- Since \[ \Biggl[ \left[\!\begin{array}{cc} -3 & 1 \\2 & 0 \end{array}\!\right] \Biggr]_{\mathcal{S}} = \left[\!\begin{array}{c} -3 \\ 1 \\ 2 \\ 0 \end{array}\!\right] \quad \text{and} \quad \Biggl[ \left[\!\begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array}\!\right] \Biggr]_{\mathcal{S}} = \left[\!\begin{array}{c} 1 \\ 0 \\ 0 \\ 1 \end{array}\!\right], \] we deduce that \[ \mathcal{C}_A = \operatorname{Span} \left\{ \left[\!\begin{array}{cc} -3 & 1 \\ 2 & 0 \end{array}\!\right], \left[\!\begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array}\!\right] \right\} = \operatorname{Span} \left\{ \left[\!\begin{array}{cc} 0 & 1 \\ 2 & 3 \end{array}\!\right], \left[\!\begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array}\!\right] \right\}. \]
-
Here we found out that the identity matrix $I_2$ commutes with $A$, which is trivial. The identity matrix commutes with any matrix. Not only that, scaled identity matrix commutes with any matrix. We also "discovered" that the matrix \(A\) commutes with the matrix \(A\). This is nothing new, every square matrix commutes with itself.
The novelty here is that we discovered that every matrix which commutes with \( \left[\!\begin{array}{cc} 0 & 1 \\ 2 & 3 \end{array}\!\right]\) is a linear combination of \( \left[\!\begin{array}{cc} 0 & 1 \\ 2 & 3 \end{array}\!\right]\) and \( \left[\!\begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array}\!\right]\).
-
I conjecture that what we discovered for the specific matrix \( \left[\!\begin{array}{cc} 0 & 1 \\ 2 & 3 \end{array}\!\right]\) is true for every nonzero \(2\times 2\) matrix \(A\) which is not a multiple of identity.
Conjecture. If \(A\) is a nonzero \(2\times 2\) matrix such that \(A \neq a I_2\) for all \(a\in \mathbb{R}\), then \[ \mathcal{C}_A = \bigl\{X \in \mathbb{R}^{2\times 2} : AX = XA \bigr\} = \operatorname{Span}\bigl\{A, I_2\bigr\} \]
- The method of coordinate mapping can be used to solve the following problems: in Section 4.3 Problems 33, 34 which relate to linear independence of polynomials, in Section 4.4 Problems 13 and 14 which relate to the coordinates with respect to a basis of polynomials and problems 27, 28, 29, 30, 31, 32 which ask you to use the coordinates of polynomials to answer linear independence and span questions, and in Section 4.5 Problems 21, 22, 23, 24 which ask you to use the coordinates of a set of polynomials to prove that they form a basis of a space of polynomials.
-
In upper level mathematics courses, you will encounter vector spaces of functions. In the post on Tuesday, November 26 we studied a vector space \(\mathbb{P}_3\) of all polynomials of degree less or equal to 3. This is one example of a vector space of functions. In the next item I will give another example. The background for the example below is Example 5 in Section 4.1.

-
In Example 5 above, let \(\mathbb{D} = \mathbb{R}\), the set of real numbers. That is, let \(\mathcal{V}\) be the set of all real-valued functions defined on \(\mathbb{R}\). (Notice that my notation for a vector space is the calligraphic uppercase \(\mathcal{V}\). I choose calligraphic uppercase letters for vector spaces since uppercase letters are reserved for matrices and transformations.)
Problem. Consider the following subset of \(\mathcal{V}\): \[ \mathcal{S}_1 = \Bigl\{ \mathbf{f} \in \mathcal{V} : \text{for some} \ \ a,b \in \mathbb{R} \ \ \text{we have} \ \ \mathbf{f}(t) = a \sin(t + b) \Bigr\}. \] Prove that \(\mathcal{S}_1\) is a subspace and determine its dimension.
- A starting point for the explorations related to this problem is to familiarize ourselves with the individual functions in the set $\mathcal{S}_{1}$. One way to do this is to plot several functions in $\mathcal{S}_1.$ One can do this by hand and stay with a small number of functions.
-
Which functions are in $\mathcal{S}_1?$ For example, with $a=0$ and $b=0$, the function $\mathbf{f}(t) = 0$ for all \(t\in \mathbb{R}\) is in $\mathcal{S}_1?$. With $a=1$ and $b=0$, the function $\sin(t)$ is in the set $\mathcal{S}_1$. With $a=1$ and $b=\pi/2$, the function $\sin(t+\pi/2) = \cos(t)$ is in the set $\mathcal{S}_1$. One can continue with specific values with $a$ and $b$ and plot a few individual functions. However, using technology one can plot many functions in $\mathcal{S}_1$.
Below I present 180 functions from $\mathcal{S}_1$ with the coefficients \begin{align*} a & \in \left\{\frac{1}{6}, \frac{1}{3}, \frac{1}{2}, \frac{2}{3}, \frac{5}{6}, 1, \frac{7}{6}, \frac{4}{3}, \frac{3}{2}, \frac{5}{3}, \frac{11}{6},2, \frac{13}{6}, \frac{7}{3}, \frac{5}{2} \right\}, \\ b & \in \left\{ 0, \frac{\pi}{6},\frac{\pi}{3},\frac{\pi}{2},\frac{2\pi}{3}, \frac{5\pi}{6}, \pi, \frac{7\pi}{6},\frac{4\pi}{3},\frac{3\pi}{2},\frac{5\pi}{3}, \frac{11\pi}{6} \right\}. \end{align*}
Place the cursor over the image to see individual functions.
- The above pictures do not directly help us prove that \(\mathcal{S}_1\) is a subspace or determine its dimension. However, they are useful for developing an intuition about what elements of \(\mathcal{S}_1\) look like. We will present a formal proof in the next items. (The proof below is based on knowledge of trigonometry.)
- We will prove the following equality of sets: \[ \mathcal{S}_1 = \operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\}. \]
-
First we prove the inclusion:
\[
\mathcal{S}_1 \subseteq \operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\}.
\]
The inclusion is proved by proving that every element of the set on the left is an element of the set on the right.
Let \(\mathbb{f} \in \mathcal{S}_1\) be arbitrary. By the definition of \(\mathcal{S}_1\) there exist \(a,b \in \mathbb{R}\) such that \[ \mathbf{f}(t) = a \sin(t + b). \] Recall Angle sum and difference identities on Wikipedia, specifically \[ \sin(x+y) = \sin(x) \cos(y) + \cos(x) \sin(y). \] Using this identity we have \begin{align*} \mathbf{f}(t) & = a \sin(t + b) \\ & = a \bigl( \sin(t) \cos(b) + \cos(t) \sin(b) \bigr) \\ & = \bigl(a \cos(b) \bigr) \sin(t) + \bigl(a \sin(b) \bigr) \cos(t) \end{align*}
Setting \(\alpha = a \cos(b)\) and \(\beta = a \sin(b)\) we get \[ \mathbf{f}(t) = \alpha \sin(t) + \beta \cos(t); \] that is \(\mathbf{f}(t)\) is a linear combination of \(\sin(t)\) and \(\cos(t)\). This proves that \[ \mathbf{f} \in \operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\}. \] Since \(\mathbb{f} \in \mathcal{S}_1\) was arbitrary, this proves the inclusion \[ \mathcal{S}_1 \subseteq \operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\}. \]
-
Next we prove the inclusion: \[ \operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\} \subseteq \mathcal{S}_1. \]
Let \(\mathbf{f}(t)\) be an arbitrary element in \(\operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\}\). Then there exist real numbers \(\alpha\) and \(\beta\) such that \[ \mathbf{f}(t) = \alpha \sin(t) + \beta \cos(t). \] If \(\alpha = 0\) and \(\beta = 0\), then we can take \(a = 0\) and \(b=0\) and we have \[ \mathbf{f}(t) = 0 \sin(t) + 0 \cos(t) = 0 \sin(t + 0). \] Therefore \(\mathbf{f} \in \mathcal{S}_1\) in this case.
Now we assume that \(\alpha \neq 0\) or \(\beta \neq 0\). Then \(\alpha^2 + \beta^2 \gt 0\).
At this point the proof uses the unit circle definition of sine and cosine which states: If \(x\) and \(y\) are real numbers such that \(x^2 + y^2 = 1\), then there exists a real number \(\theta\) such that \[ x = \cos(\theta), \quad y = \sin(\theta). \] See Unit circle definition of sine and cosine on Wikipedia.
We use the preceding definition of sine and cosine with \[ x = \frac{\alpha}{\sqrt{\alpha^2 + \beta^2}}, \quad y = \frac{\beta}{\sqrt{\alpha^2 + \beta^2}}. \] Then, \[ x^2 + y^2 = \left(\frac{\alpha}{\sqrt{\alpha^2 + \beta^2}}\right)^2 + \left(\frac{\beta}{\sqrt{\alpha^2 + \beta^2}}\right)^2 = \frac{\alpha^2}{\alpha^2 + \beta^2} + \frac{\beta^2}{\alpha^2 + \beta^2} = 1. \] Consequently, there exists \(\theta \in \mathbb{R}\) such that \[ \cos(\theta) = \frac{\alpha}{\sqrt{\alpha^2 + \beta^2}}, \quad \sin(\theta) = \frac{\beta}{\sqrt{\alpha^2 + \beta^2}}. \]
Using the preceding paragraph we have \begin{align*} \mathbf{f}(t) & = \alpha \sin(t) + \beta \cos(t) \\ & = \sqrt{\alpha^2 + \beta^2} \left( \frac{\alpha}{\sqrt{\alpha^2 + \beta^2}} \sin(t) + \frac{\beta}{\sqrt{\alpha^2 + \beta^2}} \cos(t) \right) \\ & = \sqrt{\alpha^2 + \beta^2} \Bigl( \cos(\theta) \sin(t) + \sin(\theta) \cos(t) \Bigr) \\ & = \sqrt{\alpha^2 + \beta^2} \ \sin(t+\theta). \end{align*} Setting \(a = \sqrt{\alpha^2 + \beta^2}\) and \(b = \theta\) we proved that \[ \mathbf{f}(t) = a \sin(t + b). \] Thus we proved that \(\mathbf{f} \in \mathcal{S}_1\) and this proves that \[ \operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\} \subseteq \mathcal{S}_1. \]
- In conclusion, we proved two inclusions: \begin{align*} \mathcal{S}_1 & \subseteq \operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\} \\ \operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\} & \subseteq \mathcal{S}_1. \end{align*} Therefore, \[ \mathcal{S}_1 = \operatorname{Span}\Bigl\{ \sin(t), \cos(t) \Bigr\}. \] Since each span is a subspace this proves that \(\mathcal{S}_1\) is a subspace.
-
To prove that \(\Bigl\{ \sin(t), \cos(t) \Bigr\}\) is a basis for \(\mathcal{S}_1\), we need to prove that \(\sin(t)\) and \(\cos(t)\) are linearly independent. For that we need to prove the implication: \[ \alpha \sin(t) + \beta \cos(t) = 0 \quad \text{for all} \quad t \in \mathbb{R} \] implies \(\alpha = 0\) and \(\beta = 0\).
To prove the last implication, assume \[ \alpha \sin(t) + \beta \cos(t) = 0 \quad \text{for all} \quad t \in \mathbb{R}. \] Setting \(t= 0\) we get \[ 0 = \alpha \sin(0) + \beta \cos(0) = \alpha \, 0 + \beta \, 1 = \beta, \] proving that \(\beta = 0\). Setting \(t = \pi/2\) we get \[ 0 = \alpha \sin(\pi/2) + \beta \cos(\pi/2) = \alpha \, 1 + \beta \, 0 = \alpha, \] proving that \(\alpha = 0\). Thus we proved that \(\alpha = 0\) and \(\beta = 0\). This proves that \(\sin(t)\) and \(\cos(t)\) are linearly independent. Therefore \(\Bigl\{ \sin(t), \cos(t) \Bigr\}\) is a basis for \(\mathcal{S}_1\), Thus, \[ \dim \mathcal{S}_1 = 2. \]
- I created the above animation and the picture with 180 graphs using the computer algebra system Wolfram Mathematica. Enjoyment of mathematics is considerable enriched with Wolfram Mathematica. I would like to encourage you to get familiar with it. To get started with Mathematica see my Mathematica page. Please watch the videos that are on my Mathematica page. Watching the movies is very helpful to get started with Mathematica efficiently! Mathematica is available in the computer labs in BH 215 and BH 209.
- On Monday we introduced a concept of an abstract vector space. An abstract vector space I will usually denote by $\mathcal{V},$ or same other nearby capital calygraphy letter, like $\mathcal{U},$ or $\mathcal{W}.$ Individual vectors in these spaces will be denoted by lower case letters, $u,$ $v,$ $w,$ which will often be indexed, like $v_1,$ $v_2,$ and so on.
-
We talked about the following concepts this week:
- The definition of an abstract vector space on page 192 and posted on March 7.
- The definition of a subspace on page 195
- The definition of the span of a set of vectors in the first paragraph of the subsection "A Subspace Spanned by a Set" starting on page 196. This definition in the set-builder notation reads: Let $m$ be a positive integer and let ${v}_1,\ldots,{v}_m$ be vectors in a vector space $\mathcal{V}.$ The span of vectors ${v}_1,\ldots,{v}_m$ is defined as \[ \operatorname{Span}\bigl\{{v}_1,\ldots,{v}_m\bigr\} = \bigl\{ \alpha_1 {v}_1 + \cdots + \alpha_m {v}_m : \alpha_1,\ldots,\alpha_m \in \mathbb{R} \bigr\}. \] This is a very important theorem on page 196: Theorem 1. $\operatorname{Span}\{{v}_1,\ldots,{v}_m\}$ is a subspace of $\mathcal{V}.$
- The definition of a linearly independent set on page 210. Next, I will restate this definition as an implication: An indexed set of vectors $\{{v}_1,\ldots,{v}_m\}$ in a vector space $\mathcal{V}$ is said to be linearly independent if the following implication holds \[ \alpha_1 {v}_1 + \cdots + \alpha_m {v}_m = {0} \quad \text{implies} \quad \alpha_k = 0 \quad \text{for all} \quad k \in \{1,\ldots,m\}. \] There are many other equivalent ways of stating this definition. However, the above statement is the only formal definition which is easiest to use when we need to prove that certain vectors are linearly independent.
- The definition of a basis on page 211.
- The relevant section in the book is Section 4.3: Linear independent sets; bases. Suggested problems for Section 4.3: 3, 4, 5, 9, 10, 11, 13, 14, 15, 21, 22, 23, 25, 26, 33, 34. This is a good opportunity to review linear independence of vectors in $\mathbb{R}^n.$ Most of these problems deal with vectors in $\mathbb{R}^n.$ Pay special attention to problems 33, 34 which deal with polynomials and 37 and 38 which deal with trigonomatric functions.
-
Important examples of finite dimensional vector spaces are spaces of polynomials. For $n\in\mathbb{N}$ by $\mathbb{P}_n$ we denote the vector space of all polynomials of degree less or equal to $n.$
- The most important step in understanding the vector space $\mathbb{P}_n$ is establishing that the monomials \[ \mathcal{M}_n = \bigl\{ 1, x, x^2, \ldots, x^n \bigr\} \] form a basis of the vector space $\mathbb{P}_n$.
- I wrote this webpage with a proof which uses only linear algebra.
- Below I give two proofs that the monomials \(\mathcal{M}_3 = \bigl\{ 1, x, x^2, x^3 \bigr\}\) are linearly independent. One proof uses calculus, the other proof uses linear algebra. The proof which is given in our textbook uses the Fundamental Theorem of Algebra (which is more difficult to prove.)
-
In this item I prove that the set of four monomials \(\mathcal{M}_3 = \bigl\{ 1, x, x^2, x^3 \bigr\}\) is a basis for the vector space $\mathbb{P}_3$.
- $\mathbb{P}_3$ denotes the vector space of all polynomials of degree less or equal $3.$ That is, in set-builder notation, \[ \mathbb{P}_3 = \Bigl\{a_0 + a_1 x +a_2 x^2 + a_3 x^3 \, : \, a_0, a_1, a_2, a_3 \in \mathbb{R} \Bigr\}. \] Recall that the constant monomial $1$ is a polynomial in $\mathbb{P}_3$. To get this polynomial in the above set-builder notation we take $a_0 = 1,$ $a_1 = 0,$ $a_2 = 0,$ and $a_3 = 0.$ To get the monomial $x$ in the above set-builder notation we take $a_0 = 0,$ $a_1 = 1,$ $a_2 = 0,$ and $a_3 = 0.$ Similarly, to get the square monomial $x^2$ in the above set-builder notation we take $a_0 = 0,$ $a_1 = 0,$ $a_2 = 1,$ and $a_3 = 0.$ To get the cubic monomial $x^3$ in the above set-builder notation we take $a_0 = 0,$ $a_1 = 0,$ $a_2 = 0,$ and $a_3 = 1.$ Using the concept of the span, the above expression for $\mathbb{P}_2$ in set-builder notation can be written using the concept of the span as \[ \mathbb{P}_3 = \operatorname{Span}\bigl\{ 1, x, x^2, x^3 \bigr\}. \]
-
Here is a proof that the monomials $1, x, x^2, x^3$ are linearly independent in the vector space ${\mathbb P}_3$.
Assume that $\alpha_0,$ $\alpha_1,$ $\alpha_2,$ and $\alpha_3$ are scalars in $\mathbb{R}$ such that \begin{equation} \tag{G1} \require{bbox} \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_0\cdot 1 + \alpha_1 x + \alpha_2 x^2+ \alpha_3 x^3 =0 \quad \text{for all} \quad x \in \mathbb{R}}. \end{equation} The objective here is to prove \[ \bbox[5px, #FF6666, border: 1pt solid red]{\alpha_0 = 0, \quad \alpha_1 = 0, \quad \alpha_2 =0, \quad \alpha_3 = 0}. \] Here is a Proof: Step 1. The green identity labeled (G1) holds for all real numbers $x$ in \(\mathbb{R}\). Therefore we can substitute \(x=0\) in the green identity (G1) and we get \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_0 = 0}\). Since we proved \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_0 = 0}\), we can substrate \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_0 = 0}\) in the green identity (G1) and we get \begin{equation} \tag{G2} \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1 x + \alpha_2 x^2+ \alpha_3 x^3 =0 \quad \text{for all} \quad x \in \mathbb{R}}. \end{equation} Step 2. Take the derivative of the both sides of the equality in the identity (G2) and we get \begin{equation} \tag{G3} \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1 + 2 \alpha_2 x+ 3 \alpha_3 x^2 =0 \quad \text{for all} \quad x \in \mathbb{R}}. \end{equation} The green identity (G3) holds for all real numbers $x$ in \(\mathbb{R}\). Therefore we can substitute \(x=0\) in the green identity (G3) and we get \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1 = 0}\). Since we proved \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1 = 0}\), we can substrate \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1 = 0}\) in the green identity (G3) and we get \begin{equation} \tag{G4} \bbox[5px, #88FF88, border: 1pt solid green]{2\alpha_2 x + 3 \alpha_3 x^2 =0 \quad \text{for all} \quad x \in \mathbb{R}}. \end{equation} Step 3. Take the derivative of the both sides of the equality in the identity (G4) and we get \begin{equation} \tag{G5} \bbox[5px, #88FF88, border: 1pt solid green]{2 \alpha_2 + 6 \alpha_3 x = 0 \quad \text{for all} \quad x \in \mathbb{R}}. \end{equation} The green identity (G5) holds for all real numbers $x$ in \(\mathbb{R}\). Therefore we can substitute \(x=0\) in the green identity (G5) and we get \(\bbox[5px, #88FF88, border: 1pt solid green]{2\alpha_2 = 0}\). Multiplying both sides by \(1/2\) we get: \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_2 = 0}\). Since we proved \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_2 = 0}\), we can substrate \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_2 = 0}\) in the green identity (G5) and we get \begin{equation} \tag{G6} \bbox[5px, #88FF88, border: 1pt solid green]{6\alpha_3 x = 0 \quad \text{for all} \quad x \in \mathbb{R}}. \end{equation} Step 4. The green identity (G6) holds for all real numbers $x$ in \(\mathbb{R}\). Therefore we can substitute \(x=1\) in the green identity (G6) and we get \(\bbox[5px, #88FF88, border: 1pt solid green]{6\alpha_3 = 0}\). Multiplying both sides by \(1/6\) we get: \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_3 = 0}\).
Conclusion. Using repeated differentiation and substitution, we proved that the green identity (G1) implies \[ \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_0 = 0, \quad \alpha_1 = 0, \quad \alpha_2 =0, \quad \alpha_3 = 0}. \] In other words, we have greenified the red objective of the proof. This completes the proof. -
Here is an alternative proof that the monomials $1, x, x^2, x^3$ are linearly independent in the vector space ${\mathbb P}_3$.
Assume that $\alpha_0,$ $\alpha_1,$ $\alpha_2,$ and $\alpha_3$ are scalars in $\mathbb{R}$ such that \begin{equation} \tag{G1} \require{bbox} \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_0\cdot 1 + \alpha_1 x + \alpha_2 x^2+ \alpha_3 x^3 =0 \quad \text{for all} \quad x \in \mathbb{R}}. \end{equation} The objective here is to prove \[ \bbox[5px, #FF6666, border: 1pt solid red]{\alpha_0 = 0, \quad \alpha_1 = 0, \quad \alpha_2 =0, \quad \alpha_3 = 0}. \] Here is a Proof: The green identity labeled (G1) holds for all real numbers $x$ in \(\mathbb{R}\). Therefore we can substitute the following four values for \(x\): \(x = 0, 1, -1, 2\) in the green identity (G1). Then we get the following four linear equations for the unknowns \(\alpha_0, \alpha_1, \alpha_2, \alpha_3\): \[ \bbox[5px, #88FF88, border: 1pt solid green]{ \begin{array}{lr} \alpha_0 & = 0 \\ \alpha_0 + \alpha_1 + \alpha_2 + \alpha_3 &=0 \\ \alpha_0 - \alpha_1 + \alpha_2 - \alpha_3 &=0 \\ \alpha_0 + 2\alpha_1 + 4\alpha_2 +8\alpha_3 &=0 \end{array} } \] The last green box contains a homogeneous system of four linear equations with four unknowns. The first equation gives \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_0 = 0}\). Substituting \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_0 = 0}\) in the remaining three equations yields \[ \bbox[5px, #88FF88, border: 1pt solid green]{ \begin{array}{lr} \alpha_1 + \alpha_2 + \alpha_3 &=0 \\ - \alpha_1 + \alpha_2 - \alpha_3 &=0 \\ 2\alpha_1 + 4\alpha_2 +8\alpha_3 &=0 \end{array} } \] Replacing the second equation with the sum of the first two equations and replacing the third equation with the sum of the third equation and the multiple of the first equation by \(-2\) yields the equivalent system \[ \bbox[5px, #88FF88, border: 1pt solid green]{ \begin{array}{lr} \alpha_1 + \alpha_2 + \alpha_3 & = 0 \\ \phantom{\alpha_1 +} 2 \alpha_2 & = 0 \\ \phantom{\alpha_1 +} 2\alpha_2 +6\alpha_3 &=0 \end{array} } \] Multiplying the second equation by \(1/2\) yields \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_2 = 0}\). Substituting \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_2 = 0}\) in the first and third equation yields the equivalent system \[ \bbox[5px, #88FF88, border: 1pt solid green]{ \begin{array}{lr} \alpha_1 + \alpha_3 & = 0 \\ \phantom{\alpha_1 +\,} 6\alpha_3 & = 0 \end{array} } \] Multiplying the second equation by \(1/6\) yields \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_3 = 0}\). Substituting \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_3 = 0}\) in the first equation we get \(\bbox[5px, #88FF88, border: 1pt solid green]{\alpha_1 = 0}\).
In conclusion, we proved: \[ \bbox[5px, #88FF88, border: 1pt solid green]{\alpha_0 = 0, \quad\alpha_1 = 0, \quad \alpha_2 =0, \quad \alpha_3 = 0}. \] In this way we have greenifyed the red statement. That is, we proved it. - Since we have \[ \mathbb{P}_3 = \operatorname{Span}\bigl\{ 1, x, x^2, x^3 \bigr\} \] and and we have already shown above that the monomials $\mathcal{M}_3 = \bigl\{ 1, x, x^2, x^3 \bigr\}$ are linearly independent, it follows that the monomials in $\mathcal{M}_3$ form a basis for $\mathbb{P}_3.$
-
Now that we know that $\mathcal{M}_3 = \bigl\{ 1, x, x^2, x^3 \bigr\}$ is a basis for $\mathbb{P}_3$, we can use the coordinate mapping relative to this basis.
The concept of a coordinate mapping is introduced in Section 4.4 on page 221. The most important fact is in Theorem 8 on page 221. This theorem states that a coordinate mapping is a bijection and linear transformation. A proof of Theorem 8 is outlined in Problems 23-26 on page 225. Pay attention to the paragraph before Examples 5. How to use a coordinate mapping is explained in Examples 5 and 6.
- The method of coordinate mapping can be used to solve the following problems: in Section 4.3 Problems 33, 34 which relate to linear independence of polynomials, in Section 4.4 Problems 13 and 14 which relate to the coordinates with respect to a basis of polynomials and problems 27, 28, 29, 30, 31, 32 which ask you to use the coordinates of polynomials to answer linear independence and span questions, and in Section 4.5 Problems 21, 22, 23, 24 which ask you to use the coordinates of a set of polynomials to prove that they form a basis of a space of polynomials.
- Problems 13 and 14 in Section 4.7 deal with the change of coordinates for polynomials in $\mathbb{P}_2.$
-
The standard basis for the vector space $\mathbb{P}_3$ of polynomials is the set of all monomials: \[ \mathcal{M}_3 =\bigl\{ 1, \ x, \ x^2, \ x^3 \bigr\}. \] The corresponding coordinate mapping is \[ \Bigl[a_0 + a_1 x + a_2 x^2 + a_3 x^3 \Bigr]_{\mathcal{M}_3} = \left[\!\begin{array}{c} a_0 \\ a_1 \\ a_2 \\ a_3 \end{array}\!\right] \in \mathbb{R}^4. \] For example, \[ \Bigl[(x-1)^3 \Bigr]_{\mathcal{M}_3} = \left[\!\begin{array}{r} -1 \\ 3 \\ -3 \\ 1 \end{array}\!\right] \in \mathbb{R}^4. \]
- One task in this context is to use the definition of a subspace to prove that $\mathcal{Z}_1$ is a subspace of $\mathbb{P}_3.$ Do this as an Exercise.
- In three items below we will prove that the set \(\mathcal{Z}_1\) is a span of three polynomials: \[ \mathcal{Z}_1 = \operatorname{Span}\bigl\{ x-1, x^2-1, x^3 - 1 \bigr\}. \]
- Proofs involving equality of two sets are done in two steps. We first prove that each polynomial in $\mathcal{Z}_1$ must be in $\operatorname{Span}\bigl\{ x-1, x^2-1, x^3 - 1 \bigr\},$ that is we prove that \[ \mathcal{Z}_1 \subseteq \operatorname{Span}\bigl\{ x-1, x^2-1, x^3 - 1 \bigr\}. \] Then we prove that each polynomial in $\operatorname{Span}\bigl\{x-1, x^2-1, x^3 - 1 \bigr\}$ must also be in $\mathcal{Z}_1.$ That is, we prove that \[ \operatorname{Span}\bigl\{ x-1, x^2-1, x^3 - 1 \bigr\} \subseteq \mathcal{Z}_1. \] Together these two facts prove the equality of two sets.
- Assume that $\mathbf{p} \in \mathcal{Z}_1.$ Then $\mathbf{p} \in \mathbb{P}_3$ and $\mathbf{p}(1) = 0.$ Therefore, for some $a_0, a_1, a_2, a_3 \in \mathbb{R}$ we have \[ \mathbf{p}(x) = a_0 + a_1 x + a_2 x^2 + a_3 x^3 \quad \text{and} \quad \mathbf{p}(1) = a_0 + a_1 + a_2 + a_3 = 0. \] Thus, if $\mathbf{p} \in \mathcal{Z}_1$ and \(\mathbf{p}(x) = a_0 + a_1 x + a_2 x^2 + a_3 x^3\), then \(a_0 + a_1 + a_2 + a_3 = 0\). Consequently, \(a_0 = -a_1 - a_2 - a_3\). Therefore, if $\mathbf{p} \in \mathcal{Z}_1$, then we have \begin{align*} \mathbf{p}(x) &= -a_1 - a_2 - a_3 + a_1 x + a_2 x^2 + a_3 x^3 \\ &= a_1 x -a_1 + a_2 x^2 - a_2 + a_3 x^3 - a_3\\ &= a_1 (x -1) + a_2 (x^2 - 1) + a_3 (x^3 - 1). \end{align*} The last expression shows that $\mathbf{p}$ is a linear combination of the polynomials \(x-1, x^2-1, x^3 - 1\). Hence, we proved \[ \mathcal{Z}_1 \subseteq \operatorname{Span}\bigl\{ x-1, x^2-1, x^3 - 1 \bigr\}. \]
- Assume that $\mathbf{p} \in \operatorname{Span}\bigl\{ x-1, x^2-1, x^3 - 1 \bigr\}.$ By definition of a span, there exist $\alpha_1, \alpha_2, \alpha_3 \in \mathbb{R}$ such that \[ \mathbf{p}(x) = a_1 (x -1) + a_2 (x^2 - 1) + a_3 (x^3 - 1). \] Now calculate \[ \mathbf{p}(1) = a_1 (1 -1) + a_2 (1 - 1) + a_3 (1 - 1) = 0. \] This proves that $\mathbf{p} \in \mathcal{Z}_1$. Therefore \[ \operatorname{Span}\bigl\{ x-1, x^2-1, x^3 - 1 \bigr\} \subseteq \mathcal{Z}_1. \] This item and the preceding one prove \[ \mathcal{Z}_1 = \operatorname{Span}\bigl\{ x-1, x^2-1, x^3 - 1 \bigr\}. \]
-
Above we expressed $\mathcal{Z}_1$ as a span of three polynomials. By Theorem 1 in Section 4.1 each span is a subspace. Therefore, this is an alternative proof that $\mathcal{Z}_1$ is a subspace.
Now we will prove that the polynomials $x-1, x^2-1, x^3 - 1$ are linearly independent. For that we will use the coordinate mapping relative to the standard basis \(\mathcal{M}_3 = \bigl\{1,x,x^2,x^3\bigr\}\). We have \[ \Bigl[ x- 1 \Bigr]_{\mathcal{M}_3} = \left[\!\begin{array}{r} -1 \\ 1 \\ 0 \\ 0 \end{array}\!\right], \quad \Bigl[ x^2 - 1 \Bigr]_{\mathcal{M}_3} = \left[\!\begin{array}{r} -1 \\ 0 \\ 1 \\ 0 \end{array}\!\right], \quad \Bigl[ x^3 - 1 \Bigr]_{\mathcal{M}_3} = \left[\!\begin{array}{r} -1 \\ 0 \\ 0 \\ 1 \end{array}\!\right]. \] The polynomials $x-1, x^2-1, x^3 - 1$ are linearly independent if and only if their coordinate vectors \(\Bigl[ x- 1 \Bigr]_{\mathcal{M}_3}\), \(\Bigl[ x^2- 1 \Bigr]_{\mathcal{M}_3}\), \(\Bigl[ x^3 - 1 \Bigr]_{\mathcal{M}_3}\) are linearly independent (see Example 6 in Section 4.4). Since \[ \left[\!\begin{array}{rrr} -1 & -1 & -1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\!\right] \ \sim \ \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\-1 & -1 & -1 \end{array}\!\right] \ \sim \ \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \end{array}\!\right]. \] Since all the columns in the above RREF are pivot columns, the coordinate vectors \(\Bigl[ x- 1 \Bigr]_{\mathcal{M}_3}\), \(\Bigl[ x^2- 1 \Bigr]_{\mathcal{M}_3}\), \(\Bigl[ x^3 - 1 \Bigr]_{\mathcal{M}_3}\) are linearly independent. Consequently, the polynomials $x-1, x^2-1, x^3 - 1$ are linearly independent. Therefore, \[ \bigl\{ x-1, x^2-1, x^3 - 1 \bigr\} \] is a basis for \(\mathcal{Z}_1\). Therefore \[ \dim \mathcal{Z}_1 = 3. \]
- We did Section 4.1 today. Recommended exercises: 1, 3, 5, 6, 7, 8, 9, 11 13, 15, 16, 17, 18, 21, 22, 23, 24.
-
Here I recall the definition of a vector space as I stated it in class.
Definition. A nonempty set $\mathcal{V}$ is said to be a vector space over $\mathbb R$ if it satisfies the following ten axioms.
Axiom 1. (AE) There exists a function $+: \mathcal{V}\!\times\!\mathcal{V} \to \mathcal{V}.$That is, for each pair $(u,v) \in \mathcal{V}\!\times\!\mathcal{V}$ there exists a unique $u+v \in \mathcal{V}$ which is called the sum of $u$ and $v.$Axiom 2. (AA) For every $u, v, w \in \mathcal{V}$ we have $u+(v+w) = (u+v)+w$Axiom 3. (AC) For every $u, v \in \mathcal{V}$ we have $u+v = v+u$Axiom 4. (AZ) There exists $0 \in \mathcal{V}$ such that for every $v \in \mathcal{V}$ we have $v+0 = v$Axiom 5. (AO) For every $v \in \mathcal{V}$ there exists $-v \in \mathcal{V}$ such that $v+(-v) = 0$Axiom 6. (SE) There exists a function $\cdot: \mathbb{R}\!\times\!\mathcal{V} \to \mathcal{V}.$That is, for each real number $\alpha \in \mathbb R$ and each $v \in \mathcal{V}$ there exists a unique $\alpha v \in \mathcal{V}$ which is called the scalar product of $\alpha$ and $v.$Axiom 7. (SA) For every $\alpha, \beta \in \mathbb R$ and every $v \in \mathcal{V}$ we have $\alpha (\beta v) = (\alpha\beta) v$Axiom 8. (SD) For every $\alpha, \beta \in \mathbb R$ and every $v \in \mathcal{V}$ we have $(\alpha +\beta) v = \alpha v + \beta v$Axiom 9. (SD) For every $\alpha \in \mathbb R$ and every $u, v \in \mathcal{V}$ we have $\alpha (u + v) = \alpha u + \alpha v$Axiom 10. (S0) For every $v \in \mathcal{V}$ we have $1 v = v$Explanation of the abbreviations: AE--addition exists, AA--addition is associative, AC--addition is commutative, AZ--addition has zero, AO--addition has opposites, SE-- scaling exists, SA--scaling is associative, SD--scaling distributes over addition of real numbers, SD--scaling distributes over addition of vectors, SO--scaling with one.
- To illustrate the definition of a vector space we studied an exotic vector space: \[ \require{bbox} \mathcal{V} = \left\{ \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]} \, : \, x_1, x_2 \in \mathbb{R} \ \ \text{and} \ \ x_1, x_2 \gt 0 \right\} \] with the addition defined as \[ \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]} \bbox[yellow]{+} \bbox[yellow]{\left[\! \begin{array}{c} y_1 \\ y_2 \end{array} \!\right]} = \bbox[yellow]{\left[\! \begin{array}{c} x_1 y_1 \\ x_2 y_2 \end{array} \!\right]} \quad \text{for all} \quad \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]}, \bbox[yellow]{\left[\! \begin{array}{c} y_1 \\ y_2 \end{array} \!\right]} \in \mathcal{V} \] and scaling defined as \[ \alpha \bbox[yellow]{\phantom{*}} \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]} = \bbox[yellow]{\left[\! \begin{array}{c} (x_1)^\alpha \\ (x_2)^\alpha \end{array} \!\right]} \quad \text{for all} \quad \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]}\in \mathcal{V} \quad \text{and for all} \quad \alpha \in \mathbb{R}. \] It is a nice exercise to verify that all the axioms of a vector space are satisfied. Interestingly, the zero vector in the vector space $\mathcal{V}$ is the vector $\bbox[yellow]{\left[\! \begin{array}{c} 1 \\ 1 \end{array} \!\right]}.$
- I colored the vectors in $\mathcal{V}$ yellow to distinguish them from the vectors in $\mathbb{R}^2.$
- Now consider the function $L:\mathcal{V} \to \mathbb{R}^2$ defined as follows \[ L \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]} = \left[\! \begin{array}{c} \ln x_1 \\ \ln x_2 \end{array} \!\right] \quad \text{for all} \quad \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]}\in \mathcal{V}. \] This function has the following two properties: \[ L \left(\bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]} \bbox[yellow]{+} \bbox[yellow]{\left[\! \begin{array}{c} y_1 \\ y_2 \end{array} \!\right]} \right) = L \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]} + L \bbox[yellow]{\left[\! \begin{array}{c} y_1 \\ y_2 \end{array} \!\right]} \quad \text{for all} \quad \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]}, \bbox[yellow]{\left[\! \begin{array}{c} y_1 \\ y_2 \end{array} \!\right]} \in \mathcal{V} \] and \[ L \left(\alpha\bbox[yellow]{\phantom{*}} \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]} \right) = \alpha L \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]} \quad \text{for all} \quad \bbox[yellow]{\left[\! \begin{array}{c} x_1 \\ x_2 \end{array} \!\right]} \in \mathcal{V} \quad \text{and for all} \quad \alpha \in \mathbb{R}. \]
- These two properties make $L:\mathcal{V} \to \mathbb{R}^2$ a linear transformation defined on $\mathcal{V}$ to $\mathbb{R}^2.$
- It is interesting to study subspaces of the vector space $\mathcal{V}.$ For example, what is \[ \operatorname{Span} \left\{ \bbox[yellow]{\left[\! \begin{array}{c} 1 \\ 2 \end{array} \!\right]} \right\}, \] or, what is \[ \operatorname{Span} \left\{ \bbox[yellow]{\left[\! \begin{array}{c} 2 \\ 1 \end{array} \!\right]} \right\}, \] or, \[ \operatorname{Span} \left\{ \bbox[yellow]{\left[\! \begin{array}{c} 2 \\ 2 \end{array} \!\right]} \right\}, \] or \[ \operatorname{Span} \left\{ \bbox[yellow]{\left[\! \begin{array}{c} 4 \\ 2 \end{array} \!\right]} \right\}, \] or, \[ \operatorname{Span} \left\{ \bbox[yellow]{\left[\! \begin{array}{c} 2 \\ 4 \end{array} \!\right]} \right\}. \]
- I am posting two challenging problems related to this section.
-
I recommend learning LaTeX, a superior typesetting system for writing mathematical papers. LaTeX is not only the best tool for creating mathematical content on a computer but also the standard for displaying math on the Internet. For example, all the mathematics on my website and on Wikipedia is written in LaTeX. On a Wikipedia math page, you can view the LaTeX code by clicking the "Edit" button next to the "Read" button below the title. This will show you the page's source code, where you will find LaTeX formulas. You can even copy and paste these formulas directly into your own documents if needed.
- I created Getting Started with LaTeX page to help you with this.
- Here is a simple LaTeX sample document in which I prove an interesting inequality.
- If you need help starting with LaTeX, feel free to ask me for help. It is as important as learning one nice piece of mathematics. And I want to help you with that, not only because that is my job, but because I deeply believe that both math - through learning rigorous thinking - and professional writing skills - supported by rigorous thinking - will help you in your life more than anything else.
- I have noticed that many students use the online LaTeX editor Overleaf. I do not have any experience with Overleaf, except that I have seen that many students use it with nice results.
- LaTeX functions like a computer program that compiles your mathematical document. As you may know, ChatGPT excels at writing code in various programming languages, including LaTeX. If you are unsure how to accomplish a specific task in LaTeX, you can ask ChatGPT for advice. The advice I have received has been superb, not just for LaTeX but also for Wolfram Mathematica. However, ChatGPT can sometimes be a bit sloppy and make mistakes, such as mismatched parentheses or similar issues. Providing detailed and precise prompts significantly improves the quality of the responses.
-
Below is my detailed prompt to ChatGPT and its answer.

You:
Can you please write a complete LaTeX file with instructions on using basic mathematical operations, like fractions, sums, integrals, basic functions, like cosine, sine, and exponential function, and how to structure a document and similar features? Please explain the difference between the inline and displayed mathematical formulas. Please include examples of different ways of formatting displayed mathematical formulas. Please include what you think would be useful to a mathematics student. Also, can you please include your favorite somewhat complicated mathematical formula as an example of the power of LaTeX? I emphasize I want a complete file that I can copy into a LaTeX compiler and compile into a pdf file. Please ensure that your document contains the code for the formulas you are writing, which displays both as code separately from compiled formulas. Also, please double-check that your code compiles correctly. Remember that I am a beginner and cannot fix the errors. Please act as a concerned teacher would do.
This is the LaTeX document that ChatGPT produced base on the above prompt. Here is the compiled PDF document.
You can ask ChatGPT for a specific LaTeX advice. To get a good response, think carefully about your prompt. Also, you can offer to ChatGPT a sample of short mathematical writing from the web or a book as a PNG file and it can convert that writing to LaTeX. You can even try with neat handwriting. The results will of course depend on the clarity of the file, ChatGPT makes mistakes, but I found it incredibly useful.
- It is tempting to make LaTeX a mandatory tool for creating submissions in this class. However, I do not appreciate having mandates imposed on me; I prefer the freedom to think my own thoughts. An important part of a teacher's role is to encourage students to think their own thoughts, and imposing a mandate could contradict that spirit.
-
Today I answered the following question:
in class:
Question. Let $f_n$, with $n \in \{0\}\cup\mathbb{N},$ be the sequence of Fibonacci numbers. Does there exist a continuous function $g:[0,+\infty)\to \mathbb{R}$ such that for every $n \in \{0\}\cup\mathbb{N}$ we have $g(n) = f_n.$ Here it is expected that we give a reasonably simple formula for $g(x)$.
-
Let me summarize some findings about Fibonacci numbers from yesterday.
- Standard recursive definition. \[ f_0 = 0, \quad f_1 = 1 \quad \text{and} \quad \text{for every} \quad n \in \mathbb{N} \quad f_{n+1} = f_{n} + f_{n-1} \] This definition is uses only the addition of positive integers. Applying the recursive definition repeatedly, we obtain the sequence of Fibonacci numbers \begin{multline*} f_2 = 1, f_3 = 2, f_4 = 3, f_5 = 5, f_6 = 8, f_7 = 13, f_8 = 21, f_9 = 34, f_{10} = 55, \\ f_{11} = 89, f_{12} = 144, f_{13} = 233, f_{14} = 377, f_{15} = 610, f_{16} = 987, f_{17} = 1597, \cdots \end{multline*}
- A formula for Fibonacci numbers using matrices. In class we deduced a formula for Fibonacci numbers using powers of a $2\!\times\!2$ matrix \[ \text{for all} \quad n \in \mathbb{N} \quad f_{n} = \bigl[ 1 \ \ 0 \bigr] \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right]. \] This formula involves powers of a matrix, which is not a simple calculation. It appears not to be recursive, although, in full honesty, the definition of powers is a recursive definition.
- A closed form expression for the Fibonacci numbers. We used a diagonalization of the matrix $\left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]$ to deduce the following closed form expression for the Fibonacci numbers: \[ \text{For all} \quad n \in \mathbb{N} \qquad f_{n} = \frac{1}{\sqrt{5}}\Biggl( \biggl(\frac{1+\sqrt{5}}{2}\biggr)^n - \biggl(\frac{1-\sqrt{5}}{2}\biggr)^n \Biggr). \]
- The difficulty with the last formula is that calculating accurate high powers of irrational numbers is difficult. It is important to mention that the irrational number \[ \varphi = \frac{1+\sqrt{5}}{2} \] is the famous number called Golden Ratio. We have that \[ \frac{1}{\varphi} = \frac{2}{1+\sqrt{5}} = \frac{2}{1+\sqrt{5}} \frac{1-\sqrt{5}}{1-\sqrt{5}} = \frac{2 (1-\sqrt{5})}{1-5} = - \frac{1-\sqrt{5}}{2}. \]
- Therefore, the closed form expression for the Fibonacci numbers can be written as: \[ \text{For all} \quad n \in \mathbb{N} \qquad f_{n} = \frac{1}{\sqrt{5}}\Bigl( \varphi^n - (-1)^n \varphi^{-n} \Bigr). \]
- In the previous item we deduced the following closed form expression for the Fibonacci numbers \[ \text{for all} \quad n \in \mathbb{N} \qquad f_{n} = \frac{1}{\sqrt{5}}\Bigl( \varphi^n - (-1)^n \varphi^{-n} \Bigr). \] Here $\varphi$ is the Golden Ratio. The preceding displayed formula indicates a possible answer to Christopher's question. In the displayed formula for the Fibonacci numbers replace $n$ with a positive real number $x$ as follows: \[ \text{For all} \quad x \geq 0 \quad \text{set} \qquad g(x) = \frac{1}{\sqrt{5}}\Bigl( \varphi^x - (-1)^x \varphi^{-x} \Bigr). \] The problem with the proposed formula for $g(x)$ is that the expression $(-1)^x$ is not defined for noninteger values of $x.$ You can see that there is a problem when \(x=1/2\). If you learned about the complex numbers, you know that $(-1)^{1/2} = \sqrt{-1}$ is the imaginary unit; so a complex number. We want to work with real numbers only. So, we have to work out some other formula.
-
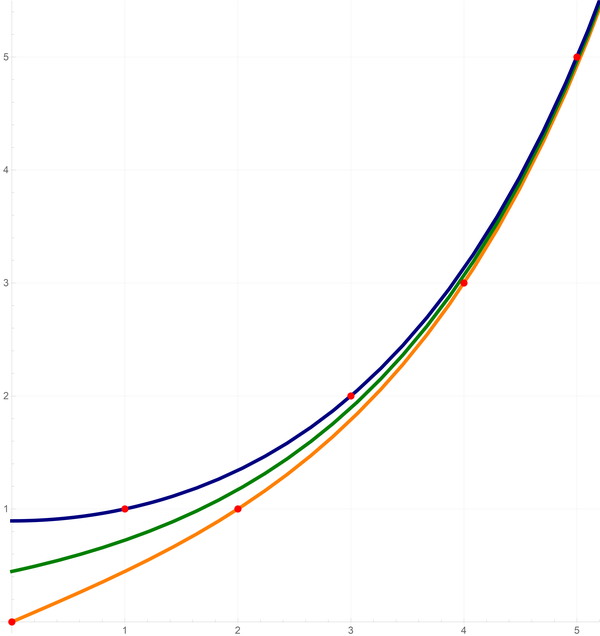
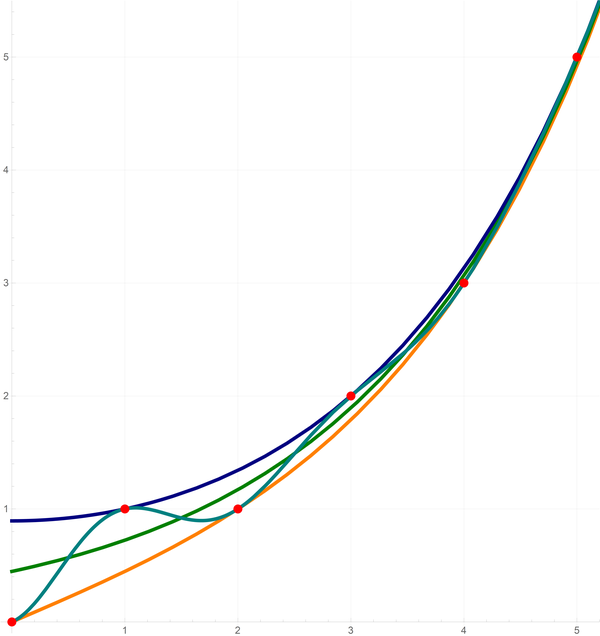
In the last (wrong) displayed formula for $g(x)$ I notice three correctly defined functions of $x$:
\begin{equation*}
\color{orange}{a(x)} = \frac{\varphi^x - \varphi^{-x}}{\sqrt{5}}, \quad
\color{#008000}{b(x)} = \frac{ \varphi^x}{\sqrt{5}}, \quad
\color{#000080}{c(x)} = \frac{\varphi^x + \varphi^{-x}}{\sqrt{5}}, \quad x \geq 0.
\end{equation*}
Clearly,
\begin{equation*}
\color{orange}{a(x)} \lt
\color{#008000}{b(x)} \lt
\color{#000080}{c(x)} \quad \text{for all} \quad x \geq 0.
\end{equation*}
On the plot below you can see the orange function $ \color{orange}{a(x)},$ the dark green function $\color{#008000}{b(x)}$ and the navy blue function $\color{#000080}{c(x)}$ and the first five Fibonacci numbers represented by red dots.
- The second problem done today is posted below.
- Consider the matrix \[ A = \frac{1}{5} \left[\! \begin{array}{rr} 4 & 3/2 \\[5pt] 1 & 7/2 \end{array} \!\right] \qquad A = \left[\! \begin{array}{rr} 0.8 & 0.3 \\[5pt] 0.2 & 0.7 \end{array} \!\right] \] These two matrices are identical. I write both, since the decimal numbers are more informative, while I prefer to do calculations with fractions.
- Today we discussed the behaviour of the sequence of vectors \[ A^n\left[\!\begin{array}{c} 1 \\ 1 \end{array} \!\right] \] for large values of positive integer $n.$ To find the formula for the preceding displayed vector, we recall that for an eigenvector $\mathbf{v}$ of $A$ corresponding to an eigenvalue $\lambda$ the calculation of $A^n\mathbf{v}$ is easy $A^n\mathbf{v} = \lambda^n\mathbf{v}.$ So, in the next item we find eigenvalues and eigenvectors of $A$.
- First find the characteristic polynomial of $A$: \begin{align*} \left| \begin{array}{cc} \frac{4}{5} -\lambda & \frac{3}{10} \\[7pt] \frac{1}{5} & \frac{7}{10} -\lambda \end{array} \right| & = \left( \frac{4}{5} -\lambda \right) \left( \frac{7}{10} -\lambda \right) - \frac{3}{50} \\ & = \lambda^2 - \frac{3}{2} \lambda + \frac{14}{25} - \frac{3}{50} \\ & = \lambda^2 - \frac{3}{2} \lambda + \frac{1}{2} \\ & = \left( \lambda - 1 \right)\left( \lambda - \frac{1}{2} \right). \end{align*} Thus the eigenvalues of $A$ are $1$ and $1/2.$ Let us find corresponding eigenvectors.
- First the eigenvalue $1.$ We need to find the nullspace of \[ \left[ \begin{array}{cc} \frac{4}{5} - 1 & \frac{3}{10} \\[7pt] \frac{1}{5} & \frac{7}{10} -1 \end{array} \right] = \left[ \begin{array}{cc} -\frac{1}{5} & \frac{3}{10} \\[7pt] \frac{1}{5} & -\frac{3}{10} \end{array} \right] = \frac{1}{10} \left[ \begin{array}{cc} -2 & 3 \\[5pt] 2 & - 3 \end{array} \right]. \] Clearly, the nullspace of the last matrix is one-dimensional and a basis vector for the null space is $\left[\!\begin{array}{c} 3 \\ 2\end{array} \right].$ Thus $\left[\!\begin{array}{c} 3 \\ 2\end{array}\!\right]$ is an eigenvector corresponding to the eigenvalue $1.$
- Now, find an eigenvector corresponding to the eigenvalue $1/2.$ We need to find the null space of \[ \left[ \begin{array}{cc} \frac{4}{5} - \frac{1}{2} & \frac{3}{10} \\[7pt] \frac{1}{5} & \frac{7}{10} - \frac{1}{2} \end{array} \right] = \left[ \begin{array}{cc} \frac{3}{10} & \frac{3}{10} \\[7pt] \frac{1}{5} & \frac{2}{10} \end{array} \right] = \frac{1}{10} \left[ \begin{array}{cc} 3 & 3 \\[5pt] 2 & 2 \end{array} \right]. \] Clearly, the nullspace of the last matrix is one-dimensional and a basis vector for the null space is $\left[\!\begin{array}{c} 1 \\ -1 \end{array} \right].$ Thus $\left[\!\begin{array}{c} 1 \\ -1\end{array}\!\right]$ is an eigenvector corresponding to the eigenvalue $1/2.$
- In conclusion, we found two linearly independent eigenvectors of $A$ \[ \left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right], \quad \left[\!\begin{array}{c} 1 \\ -1\end{array}\!\right]. \] These two vectors form a basis for $\mathbb{R}^2.$ Thus, we can write the vector $\left[\!\begin{array}{c} 1 \\ 1 \end{array} \!\right]$ as a linear combination of the eigenvectors that we found: \[ \left[\!\begin{array}{c} 1 \\ 1 \end{array} \!\right] = \frac{2}{5} \left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right] - \frac{1}{5} \left[\!\begin{array}{c} 1 \\ -1\end{array}\!\right]. \]
- Finally, using the properties of the matrix-vector multiplication and the fact that we found eigenvectors we can calculate \begin{align*} A^n\left[\!\begin{array}{c} 1 \\ 1 \end{array} \!\right] & = A^n \left( \frac{2}{5} \left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right] - \frac{1}{5} \left[\!\begin{array}{c} 1 \\ -1\end{array}\!\right] \right) \\ & = \frac{2}{5} A^n \left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right] - \frac{1}{5} A^n \left[\!\begin{array}{c} 1 \\ -1\end{array}\!\right] \\ & = \frac{2}{5} 1^n \left[\!\begin{array}{c} 3 \\ 2\end{array}\!\right] - \frac{1}{5} \left(\frac{1}{2}\right)^n \left[\!\begin{array}{c} 1 \\ -1\end{array}\!\right] \\ & = \frac{2}{5} \left[\!\begin{array}{c} 3 \\ 2 \end{array}\!\right] - \frac{1}{5} \frac{1}{2^n}\left[\!\begin{array}{c} 1 \\ -1\end{array}\!\right]. \end{align*}
- Since $\displaystyle\frac{1}{2^n}$ is very close to $0$ when $n$ is a large positive number, we deduce that \[ A^n\left[\!\begin{array}{c} 1 \\ 1 \end{array} \!\right] \quad \text{is very close to} \quad \frac{2}{5} \left[\!\begin{array}{c} 3 \\ 2\end{array}\!\right] = \left[\!\begin{array}{c} 1.2 \\ 0.8 \end{array}\!\right]. \] Using the concept of limit we can write \[ \lim_{n \to \infty}A^n\left[\!\begin{array}{c} 1 \\ 1 \end{array} \!\right] = \frac{2}{5} \left[\!\begin{array}{c} 3 \\ 2\end{array}\!\right] = \left[\!\begin{array}{c} 1.2 \\ 0.8 \end{array}\!\right]. \]
- In this post I present a remarkable application of eigenvalues and eigenvectors to a famous sequence of positive integers: Fibonacci numbers.
- Recall that $\mathbb{N}$ denotes the set of positive integers. The Fibonacci numbers are the elements of the sequence \[ f_0, f_1, f_2, \ldots, f_n, \ldots \] recursively defined by \[ f_0 = 0, \quad f_1 = 1, \quad \text{and} \quad f_{n+1} = f_n + f_{n-1} \quad \text{for} \quad n \in \mathbb{N}. \] Since we are given $f_0 = 0$ and $f_1 = 1$ using the recursion $f_{n+1} = f_n + f_{n-1}$ with $n=1$ we get $f_2 = 0+1 = 1.$ A repeated use of the recursion $f_{n+1} = f_n + f_{n-1}$ with $n=2$, then $n=3$, and so on, we get \begin{multline*} f_0 = 0, \ f_1 = 1, \ f_2 = 1, \ f_3 = 2, \ f_4 = 3, \ f_5 = 5, \ f_6 = 8, \ f_7 = 13, \ f_8 = 21, \ \\ f_9 = 34, \ f_{10} = 55, \ f_{11} = 89, \ f_{12} = 144, \ f_{13} = 233, \ f_{14} = 377, \ \ldots \ \end{multline*} It is clear that with enough patience we can calculate $f_{100}$ by calculating all Fibonacci numbers preceding it. However, that would take quite a bit of patience, since \[ f_{100} = 354,224,848,179,261,915,075. \] Computers are really good with doing recursively defined operations. I wrote a webpage to get you started with Mathematica. If you want to try using Mathematica on WWU computers please let me know. I want to help you with that.
- Since in Mathematics we like to be able to approach mathematical concepts in diverse ways, we are interested in finding a formula for the $n$-th Fibonacci number without calculating all the preceding Fibonacci numbers; a formula that will use only $n$ and algebraic operations. Amazingly, Linear Algebra offers a way to do that. The next items will illustrate how that comes about.
- The first step is to write the recutsion \[ f_{n+1} = f_n + f_{n-1} \] using a matrix: \[ \left[\!\begin{array}{l} f_{n} \\ f_{n+1} \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{l} f_{n-1} \\ f_{n} \end{array}\!\right]. \] Thus, we can obtain the Fibonacci sequence by repeated application of the matrix $\displaystyle\left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]$ as follows \begin{align*} \left[\!\begin{array}{l} f_{1} \\ f_{2} \end{array}\!\right] & = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{l} f_0 \\ f_{1} \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] \\ \left[\!\begin{array}{l} f_{2} \\ f_{3} \end{array}\!\right] & = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{l} f_{1} \\ f_{2} \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^2 \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] \\ \left[\!\begin{array}{l} f_{3} \\ f_{4} \end{array}\!\right] &= \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{l} f_{2} \\ f_{3} \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]\left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^2 \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^3 \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] \\ \left[\!\begin{array}{l} f_{4} \\ f_{5} \end{array}\!\right] &= \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{l} f_{3} \\ f_{4} \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^3 \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^4 \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] \\ & \ \vdots \\ \left[\!\begin{array}{l} f_{n} \\ f_{n+1} \end{array}\!\right] &= \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{l} f_{n-1} \\ f_{n} \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^{n-1} \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^{n} \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] \\ \left[\!\begin{array}{l} f_{n+1} \\ f_{n+2} \end{array}\!\right] &= \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{l} f_{n} \\ f_{n+1} \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^{n} \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^{n+1} \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] \end{align*}
- In the preceding item we saw that \[ \left[\!\begin{array}{l} f_{n} \\ f_{n+1} \end{array}\!\right] = \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right]. \] Therefore, \[ f_n = \bigl[ 1 \ \ 0 \bigr] \left[\!\begin{array}{l} f_{n} \\ f_{n+1} \end{array}\!\right] = \bigl[ 1 \ \ 0 \bigr] \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right]. \] We could stop here and pronounce that this is sufficiently good formula for $f_n$ which uses only $n$ and matrix algebra. However, we want a formula for $f_n$ which uses only algebra with specific numbers, without matrices. To obtain such a formula we will calculate the eigenvalues and eigenvectors of the matrix $\displaystyle\left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]$.
- First we calculate the characteristic polynomial of $\displaystyle\left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]$: \[ \det\left( \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right] - \left[\!\begin{array}{cc} \lambda & 0 \\ 0 & \lambda \end{array}\!\right] \right) = \left|\!\begin{array}{cc} -\lambda & 1 \\ 1 & 1-\lambda \end{array}\!\right| = -\lambda(1-\lambda) - 1 = \lambda^2 - \lambda - 1 \] The roots of the characteristic polynomial are \[ \lambda_1 = \frac{1+\sqrt{5}}{2} = \varphi \quad \text{and} \quad \lambda_2 = \frac{1-\sqrt{5}}{2} = \psi. \] The number $\varphi$ is the famous number Golden ratio. The Greek letter $\varphi$ is the standard notation for the Golden ratio. We introduce $\psi$ since we will use it several times below.
- An eigenvector of $\displaystyle\left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]$ corresponding to $\varphi$ is $\displaystyle\left[\!\begin{array}{l} 1 \\ \varphi \end{array}\!\right]$ and an eigenvector corresponding to $\psi$ is $\displaystyle\left[\!\begin{array}{l} 1 \\ \psi \end{array}\!\right]$. Please verify that \[ \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]\left[\!\begin{array}{l} 1 \\ \varphi \end{array}\!\right] = \varphi \left[\!\begin{array}{l} 1 \\ \varphi \end{array}\!\right] \quad \text{and} \quad \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]\left[\!\begin{array}{l} 1 \\ \psi \end{array}\!\right] = \psi \left[\!\begin{array}{l} 1 \\ \psi \end{array}\!\right]. \] To verify the preceding vector equalities you will use that $\varphi$ and $\psi$ are the roots of the characteristic polynomial, that is \[ \varphi^2 - \varphi - 1 = 0 \quad \text{and} \quad \psi^2 - \psi - 1 = 0. \] One of the important properties of eigenvectors is that it is easy to calculate the action of the powers of the matrix on eigenvectors: \[ \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left[\!\begin{array}{c} 1 \\ \varphi \end{array}\!\right] = \varphi^n \left[\!\begin{array}{c} 1 \\ \varphi \end{array}\!\right] \quad \text{and} \quad \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left[\!\begin{array}{c} 1 \\ \psi \end{array}\!\right] = \psi^n \left[\!\begin{array}{c} 1 \\ \psi \end{array}\!\right]. \]
- To improve the formula \[ f_n = \bigl[ 1 \ \ 0 \bigr] \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left[\!\begin{array}{c} 0 \\ 1 \end{array}\!\right], \] we will represent the vector $\displaystyle\left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right]$ as a linear combination of the eigenvectors: \[ \left[\!\begin{array}{c} 0 \\ 1 \end{array}\!\right] = x_1 \left[\!\begin{array}{c} 1 \\ \varphi \end{array}\!\right] + x_2 \left[\!\begin{array}{c} 1 \\ \psi \end{array}\!\right]. \] We do not need to do row reduction to solve this system. Since $x_1+x_2 = 0$ we deduce that $x_2 = -x_1$. Then we have \[ x_1 (\varphi - \psi) = 1. \] Since $\varphi - \psi = \sqrt{5}$ we have \[ \left[\!\begin{array}{c} 0 \\ 1 \end{array}\!\right] = \frac{1}{\sqrt{5}} \left[\!\begin{array}{c} 1 \\ \varphi \end{array}\!\right] - \frac{1}{\sqrt{5}} \left[\!\begin{array}{c} 1 \\ \psi \end{array}\!\right]. \] Therefore, \begin{align*} f_n & = \bigl[ 1 \ \ 0 \bigr] \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left[\!\begin{array}{l} 0 \\ 1 \end{array}\!\right] \\ & = \bigl[ 1 \ \ 0 \bigr] \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left( \frac{1}{\sqrt{5}} \left[\!\begin{array}{c} 1 \\ \varphi \end{array}\!\right] - \frac{1}{\sqrt{5}} \left[\!\begin{array}{c} 1 \\ \psi \end{array}\!\right] \right) \\ & = \bigl[ 1 \ \ 0 \bigr] \left( \frac{1}{\sqrt{5}} \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left[\!\begin{array}{c} 1 \\ \varphi \end{array}\!\right] - \frac{1}{\sqrt{5}} \left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]^n \left[\!\begin{array}{c} 1 \\ \psi \end{array}\!\right] \right) \\ & = \bigl[ 1 \ \ 0 \bigr] \left( \frac{1}{\sqrt{5}} \varphi^n \left[\!\begin{array}{l} 1 \\ \varphi \end{array}\!\right] - \frac{1}{\sqrt{5}} \psi^n \left[\!\begin{array}{c} 1 \\ \psi \end{array}\!\right] \right) \\ & = \frac{1}{\sqrt{5}} \bigl[ 1 \ \ 0 \bigr] \left( \left[\!\begin{array}{c} \varphi^n \\ \varphi^{n+1} \end{array}\!\right] - \left[\!\begin{array}{c} \psi^{n} \\ \psi^{n+1} \end{array}\!\right] \right) \\ & = \frac{1}{\sqrt{5}} \bigl[ 1 \ \ 0 \bigr] \left[\!\begin{array}{c} \varphi^n - \psi^{n} \\ \varphi^{n+1} -\psi^{n+1} \end{array}\!\right]\\ & = \frac{1}{\sqrt{5}} \bigl( \varphi^n - \psi^{n} \bigr). \end{align*} Thus, finally and amazingly, \[ f_n = \frac{1}{\sqrt{5}} \bigl( \varphi^n - \psi^{n} \bigr) = \frac{1}{\sqrt{5}} \left( \frac{(1+\sqrt{5})^n}{2^n} - \frac{(1-\sqrt{5})^n}{2^n} \right) = \frac{ (1+\sqrt{5})^n - (1-\sqrt{5})^n }{2^n \sqrt{5}} \] for all nonnegative integers $n$. A formula like this in which $f_n$ is given in terms of $n$ and standard functions is called a closed form expression. A lot of effort in mathematics has been put in finding closed form expressions for different mathematical objects.
-
A closed form expression for the Fibonacci numbers. In the preceding items we used eigenvectors of the matrix $\left[\!\begin{array}{cc} 0 & 1 \\ 1 & 1 \end{array}\!\right]$ to deduce the following closed form expression for the Fibonacci numbers: \[ \text{for all} \quad n \in \mathbb{N} \qquad f_{n} = \frac{1}{\sqrt{5}}\Biggl( \biggl(\frac{1+\sqrt{5}}{2}\biggr)^n - \biggl(\frac{1-\sqrt{5}}{2}\biggr)^n \Biggr). \] The difficulty with the recursive formula for the Fibonacci numbers is that we have to calculate all the numbers preceding $f_n$ in order to calculate $f_n.$ The difficulty with the closed form expression for the Fibonacci numbers is that calculating accurate powers \[ \biggl(\frac{1+\sqrt{5}}{2}\biggr)^n \quad \text{and} \quad \biggl(\frac{1-\sqrt{5}}{2}\biggr)^n \] for large values for $n \in\mathbb{N}$, like $n=100$, is difficult.
It is important to mention that the irrational number \[ \varphi = \frac{1+\sqrt{5}}{2} \] is the famous number called Golden Ratio.
We have that \[ \frac{1-\sqrt{5}}{2} = \frac{\bigl(1-\sqrt{5}\bigr)\bigl(1+\sqrt{5}\bigr)}{2\bigl(1+\sqrt{5}\bigr)} = \frac{1-5}{2\bigl(1+\sqrt{5}\bigr)} = - \frac{2}{1+\sqrt{5}} = - \frac{1}{\varphi} = - \varphi^{-1}. \] Therefore, the closed form expression for the Fibonacci numbers can be written as \[ \text{for all} \quad n \in \mathbb{N} \qquad f_{n} = \frac{1}{\sqrt{5}}\Bigl( \varphi^n - (-1)^n \varphi^{-n} \Bigr) \quad \text{where} \quad \varphi = \frac{1+\sqrt{5}}{2}. \]
- Recommended exercises for Section 5.3 are 2, 3, 5, 8, 9, 12, 13, 16, 18, 20, 23, 24.
-
Today we discussed the following theorem:
The above formulation of this important theorem is short. It requires the understanding of the definition of a diagonalizable matrix and the understanding of the definition of a basis of $\mathbb{R}^n$ and the understanding of the concept of an eigenvector of $A.$ A long statement of the theorem which incorporates all these definitions is as follows:
Theorem. Let $n \in \mathbb{N}$ and let $A$ be an $n\!\times\!n$ matrix. The following two statements are equivalent:
(a) There exist an invertible $n\!\times\!n$ matrix $P$ and a diagonal $n\!\times\!n$ matrix $D$ such that $A= PDP^{-1}.$
(b) There exist linearly independent vectors $\mathbf{v}_1, \mathbf{v}_2, \ldots, \mathbf{v}_n$ in $\mathbb{R}^n$ and real numbers $\lambda_1, \lambda_2,\ldots,\lambda_n$ such that $A \mathbf{v}_k = \lambda_k \mathbf{v}_k$ for all $k\in \{1,\ldots,n\}.$
- Proof of (b)⇒(a). Assume (b). That is, assume that there exist linearly independent vectors $\mathbf{v}_1, \mathbf{v}_2, \ldots, \mathbf{v}_n$ in $\mathbb{R}^n$ and real numbers $\lambda_1, \lambda_2,\ldots,\lambda_n$ such that \[ A \mathbf{v}_k = \lambda_k \mathbf{v}_k \quad \text{for all} \quad k\in \{1,\ldots,n\}. \] The preceding displayed expression contains $n$ vector equations. These $n$ vector equations can be expressed as one matrix equation \[ \Bigl[ A \mathbf{v}_1 \ A \mathbf{v}_2 \ \cdots \ A \mathbf{v}_n \Bigr] = \Bigl[ \lambda_1 \mathbf{v}_1 \ \lambda_2 \mathbf{v}_2 \ \cdots \ \lambda_n \mathbf{v}_n \Bigr]. \] By the definition of the matrix multiplication the preceding matrix equality can be expressed as \[ A \Bigl[ \mathbf{v}_1 \ \mathbf{v}_2 \ \cdots \ \mathbf{v}_n \Bigr] = \Bigl[ \mathbf{v}_1 \ \mathbf{v}_2 \ \cdots \ \mathbf{v}_n \Bigr] \left[\!\begin{array}{cccc} \lambda_1 & 0 & \cdots & 0 \\ 0 & \lambda_1 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_n \end{array}\!\right]. \] The preceding matrix equality can be written as \[ A P = P D, \] where we set \[ P = \Bigl[ \mathbf{v}_1 \ \mathbf{v}_2 \ \cdots \ \mathbf{v}_n \Bigr] \quad \text{and} \quad D = \left[\!\begin{array}{cccc} \lambda_1 & 0 & \cdots & 0 \\ 0 & \lambda_1 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_n \end{array}\!\right]. \] Since we assume that $\mathbf{v}_1, \mathbf{v}_2, \ldots, \mathbf{v}_n$ are linearly independent vectors in $\mathbb{R}^n$ the matrix $P$ is invertible by the Invertible Matrix Theorem. Therefore, the matrix $P^{-1}$ exists. Multiplying the equality \[ AP=PD \] from the right by $P^{-1}$ we get \[ A = PDP^{-1}. \] This proves (a).
- Now we recall Example 1 from Monday, November 18, 2024. We calculated that \begin{align*} \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] & = 1 \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right], \\ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & = 2 \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \\ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right]\left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] & = 2 \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right]. \end{align*} and \[ \left[\! \begin{array}{crc|ccc} 1 & -1 & 1 & 1 & 0 & 0\\ 1 & 1 & 0 & 0 & 1 & 0 \\ 3 & 0 & 1 & 0 & 0 & 1 \end{array} \!\right] \sim \cdots \sim \left[\! \begin{array}{ccc|rrc} 1 & 0 & 0 & -1 & -1 & 1\\ 0 & 1 & 0 & 1 & 2 & -1 \\ 0 & 0 & 1 & 3 & 3 & -2 \end{array} \!\right]. \]
- In the preceding item we have that \[ A = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \] is a $3\!\times\!3$ matrix. The vectors \[ \mathbf{v}_1 = \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right], \quad \mathbf{v}_2 = \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \quad \mathbf{v}_3 = \left[\! \begin{array}{r} 1 \\ 0 \\ 1 \end{array} \!\right] \] are linearly independent vectors in $\mathbb{R}^3$ which are eigenvectors of $A$ such that \[ A \mathbf{v}_1 = 1 \mathbf{v}_1, \quad A \mathbf{v}_2 = 2 \mathbf{v}_2, \quad A \mathbf{v}_3 = 2 \mathbf{v}_3. \] Based on the proof presented above the preceding three vector equations can be written as one matrix equation as follows (this is the equation $AP=PD$ in the proof) \[ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{crc} 1 & -1 & 1\\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{crc} 1 & -1 & 1\\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{crc} 1 & 0 & 0\\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] \] Multiplying the preceding matrix equation with the inverse calculated in the previous item \[ \left[\! \begin{array}{crc} 1 & -1 & 1\\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right]^{-1} = \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right], \] we get the diagonalization of the matrix $A$: \[ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] . \] Notice that this is a specific numerical matrix equality and it takes just a little bit of patience to verify whether it is true or not.
- For Section 5.2 do 1-8, 11, 12, 14, 15, (in all these problems you can find eigenvectors as well) 9, 13, 18, 19, 20, 21, 24, 25, 27.
-
Example 1. In this item I will illustrate how to calculate eigenvalues and the corresponding eigenspaces of a specific $3\!\times\!3$ matrix. Consider the matrix
\[
A = \left[\!
\begin{array}{rrr}
3 & 1 & -1 \\
1 & 3 & -1 \\
3 & 3 & -1
\end{array}
\!\right] .
\]
- First we find the characteristic polynomial of this matrix. The characteristic polynomial is the determinant of the following matrix: \[ A - \lambda I_3 = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] - \left[\! \begin{array}{rrr} \lambda & 0 & 0 \\ 0 & \lambda & 0 \\ 0 & 0 & \lambda \end{array} \!\right] = \left[\! \begin{array}{ccc} 3-\lambda & 1 & -1 \\ 1 & 3-\lambda & -1 \\ 3 & 3 & -1-\lambda \end{array} \!\right] \] Next we calculate this determinant: \begin{align*} \left|\! \begin{array}{ccc} 3-\lambda & 1 & -1 \\ 1 & 3-\lambda & -1 \\ 3 & 3 & -1-\lambda \end{array} \!\right| &= \left|\! \begin{array}{ccc} 2-\lambda & -2+\lambda & 0 \\ 1 & 3-\lambda & -1 \\ 3 & 3 & -1-\lambda \end{array} \!\right| \\[5pt] &= \left|\! \begin{array}{ccc} 2-\lambda & 0 & 0 \\ 1 & 4-\lambda & -1 \\ 3 & 6 & -1-\lambda \end{array} \!\right| \\[5pt] &= (2-\lambda) \bigl( (4-\lambda)(-1-\lambda) + 6 \bigr) \\[5pt] & = (2-\lambda)\bigl(\lambda^2 - 3 \lambda + 2\bigr) \\[5pt] & = -(\lambda - 2)^2 ( \lambda - 1) \end{align*} (At the first equality sign, we subtracted the second row from the first. At the second equality sign, we added the first column to the second. These operations do not change the value of a determinant.)
- Thus the eigenvalues of the matrix $A$ are $1$ and $2.$
- Next we will find the eigenspace corresponding to the eigenvalue $1.$ For that we need to find the nullspace of the matrix \[ A - 1 I_3 = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] - \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{ccc} 2 & 1 & -1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right]. \] So, we row reduce this matrix: \[ \left[\! \begin{array}{ccc} 2 & 1 & -1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] \sim \left[\! \begin{array}{ccc} 1 & 2 & -1 \\ 0 & 3 & -1 \\ 0 & 3 & -1 \end{array} \!\right] \sim \left[\! \begin{array}{ccc} 1 & 2 & -1 \\ 0 & 1 & -1/3 \\ 0 & 0 & 0 \end{array} \!\right] \sim \left[\! \begin{array}{ccc} 1 & 0 & -1/3 \\ 0 & 1 & -1/3 \\ 0 & 0 & 0 \end{array} \!\right]. \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} s/3 \\ s/3 \\ s \end{array} \!\right] \ : \ s \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] \right\}. \] Hence one eigenvector is $\left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right].$
- Next we will find the eigenspace corresponding to the eigenvalue $2.$ For that we need to find the nullspace of the matrix \[ A - 2 I_3 = \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] - \left[\! \begin{array}{rrr} 2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & 1 & -1 \\ 1 & 1 & -1 \\ 3 & 3 & -3 \end{array} \!\right]. \] So, we row reduce this matrix: \[ \left[\! \begin{array}{rrr} 1 & 1 & -1 \\ 1 & 1 & -1 \\ 3 & 3 & -3 \end{array} \!\right] \sim \left[\! \begin{array}{rrr} 1 & 1 & -1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array} \!\right]. \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} -s + t \\ s \\ t \end{array} \!\right] \ : \ s, t \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{c} -1 \\ 1 \\ 0 \end{array} \!\right], \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] \right\}. \]
- Hence, two linearly independent eigenvectors corresponding to the eigenvalue $2$ are \[ \left[\! \begin{array}{c} -1 \\ 1 \\ 0 \end{array} \!\right] \qquad \text{and} \qquad \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right]. \]
- The magic of what we found by now is that we found a basis of $\mathbb{R}^3$ which consists of eigenvectors of $A:$ \[ \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right], \quad \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \quad \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right]. \]
- It is easy to verify whether these are really eigenvectors: \begin{align*} \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right] & = 1 \left[\! \begin{array}{c} 1 \\ 1 \\ 3 \end{array} \!\right], \\ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right] \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & = 2 \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \\ \left[\! \begin{array}{rrr} 3 & 1 & -1 \\ 1 & 3 & -1 \\ 3 & 3 & -1 \end{array} \!\right]\left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right] & = 2 \left[\! \begin{array}{c} 1 \\ 0 \\ 1 \end{array} \!\right]. \end{align*} Yes, they are.
- I also made the claim that the three eigenvectors are linearly independent. Let us verify that as well. \[ \left[\! \begin{array}{crc|ccc} 1 & -1 & 1 & 1 & 0 & 0\\ 1 & 1 & 0 & 0 & 1 & 0 \\ 3 & 0 & 1 & 0 & 0 & 1 \end{array} \!\right] \sim \cdots \sim \left[\! \begin{array}{ccc|rrc} 1 & 0 & 0 & -1 & -1 & 1\\ 0 & 1 & 0 & 1 & 2 & -1 \\ 0 & 0 & 1 & 3 & 3 & -2 \end{array} \!\right]. \] We know that the right-hand side matrix in the Reduced Row Echelon Form is the inverse of the matrix whose columns are the eigenvectors. To verify the row reduction above, we calculate: \[ \left[\! \begin{array}{rrr} 1 & -1 & 1 \\ 1 & 1 & 0 \\ 3 & 0 & 1 \end{array} \!\right] \left[\! \begin{array}{rrr} -1 & -1 & 1 \\ 1 & 2 & -1 \\ 3 & 3 & -2 \end{array} \!\right] = \left[\! \begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right]. \]
-
Example 2. In this item I will illustrate how to calculate eigenvalues and the corresponding eigenspaces of a specific $4\!\times\!4$ matrix. The purpose is to demonstrate a matrix that is not diagonalizable. Consider the matrix
\[
A = \left[\!
\begin{array}{rrrr}
0 & 0 & -1 & -1 \\
-1 & 0 & 0 & 0 \\
2 & 1 & 2 & 1 \\
-2 & -1 & -1 & 0
\end{array}
\!\right] .
\]
- First we find the characteristic polynomial of this matrix. The characteristic polynomial is the determinant of the following matrix: \[ A - \lambda I_4 = \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] - \left[\! \begin{array}{rrrr} \lambda & 0 &0 & 0 \\ 0 & \lambda & 0 & 0 \\ 0 & 0 & \lambda & 0 \\ 0 & 0 & 0 & \lambda \end{array} \!\right] = \left[\! \begin{array}{cccc} -\lambda & 0 & -1 & -1 \\ -1 & -\lambda & 0 & 0 \\ 2 & 1 & 2-\lambda & 1 \\ -2 & -1 & -1 & -\lambda \end{array} \!\right] \] Next we calculate the determinant of the preceding matrix: \begin{align*} \left|\! \begin{array}{cccc} -\lambda & 0 & -1 & -1 \\ -1 & -\lambda & 0 & 0 \\ 2 & 1 & 2-\lambda & 1 \\ -2 & -1 & -1 & -\lambda \end{array} \!\right| & = -\lambda \left|\begin{array}{ccc} -\lambda & 0 & 0 \\ 1 & 2-\lambda & 1 \\ -1 & -1 & -\lambda \end{array} \right| - \left| \begin{array}{ccc} -1 & -\lambda & 0 \\ 2 & 1 & 1 \\ -2 & -1 & -\lambda \end{array} \right| + \left| \begin{array}{ccc} -1 & -\lambda & 0 \\ 2 & 1 & 2-\lambda \\ -2 & -1 & -1 \end{array} \right| \\ & = \lambda^2 ( \lambda^2 -2 \lambda + 1 ) - \bigl( \lambda -1 +2 \lambda - 2 \lambda^2 \bigr) + \bigl( \lambda - 1 + 2 \lambda - 2 \lambda^2 \bigr) \\ & = \lambda^2 ( \lambda^2 -2 \lambda + 1 ) \\ & = \lambda^2 ( \lambda - 1 )^2 \end{align*}
- Thus the eigenvalues of the matrix $A$ are $0$ and $1.$
- Next we will find the eigenspace corresponding to the eigenvalue $0.$ For that we need to find the nullspace of the matrix \[ A - 0 I_4 = \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] \]
- So, we row reduce the matrix $A:$ \[ \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] \sim \cdots \sim \left[\! \begin{array}{rrrr} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & -1 \\ 0 & 0 & 1 & 1 \\ 0 & 0 & 0 & 0 \end{array} \!\right] \] Thus, the eigenspace is the subspace \[ \left\{ \left[\! \begin{array}{c} 0 \\ s \\ -s \\ s \end{array} \!\right] \ : \ s \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{r} 0 \\ 1 \\ -1 \\ 1 \end{array} \!\right] \right\}. \]
- Thus, eigenspace corresponding to the eigenvalue $0$ is one-dimensional.
- Next we will find the eigenspace corresponding to the eigenvalue $1.$ For that we need to find the nullspace of the matrix \[ A - 1 I_4 = \left[\! \begin{array}{rrrr} 0 & 0 & -1 & -1 \\ -1 & 0 & 0 & 0 \\ 2 & 1 & 2 & 1 \\ -2 & -1 & -1 & 0 \end{array} \!\right] - \left[\! \begin{array}{rrrr} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{array} \!\right] = \left[\! \begin{array}{rrrr} -1 & 0 & -1 & -1 \\ -1 & -1 & 0 & 0 \\ 2 & 1 & 1 & 1 \\ -2 & -1 & -1 & -1 \end{array} \!\right] \]
- So, we row reduce the precedig matrix: \[ \left[\! \begin{array}{rrrr} -1 & 0 & -1 & -1 \\ -1 & -1 & 0 & 0 \\ 2 & 1 & 1 & 1 \\ -2 & -1 & -1 & -1 \end{array} \!\right] \sim \cdots \sim \left[\! \begin{array}{rrrr} 1 & 0 & 1 & 1 \\ 0 & 1 & -1 & -1 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{array} \!\right] \] Thus, the eigenspace corresponding to the eigenvalue $1$ is the subspace \[ \left\{ \left[\! \begin{array}{c} -s-t \\ s+t \\ s \\ t \end{array} \!\right] \ : \ s, t \in \mathbb{R} \right\} = \operatorname{Span} \left\{ \left[\! \begin{array}{r} -1 \\ 1 \\ 1 \\ 0 \end{array} \!\right], \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \\ 1 \end{array} \!\right] \right\}. \]
- Thus, the eigenspace corresponding to the eigenvalue $1$ is two-dimensional.
- Since we found all eigenspaces of the $4\!\times\!4$ matrix $A$ and these eigenspaces have dimensions $1$ and $2$, we conclude that we can have at most three linearly independent eigenvectors. Consequently, we can not have a basis for $\mathbb R^4$ which consists of eigenvectors of $A.$ This shows directly that the matrix $A$ is not diagonalizable.
- We discussed Section 5.1. Suggested problems for Section 5.1: 1, 3, 4, 5, 6, 8, 11, 15, 16, 17, 19, 20, 24-27, 29, 30, 31.
- A related Wikipedia link: Eigenvalue, eigenvector and eigenspace.
- Below are animations of different matrices in action. In each scene the navy blue vector is the image of the sea green vector under the multiplication by a matrix $A$. For easier visualization of the action the heads of vectors leave traces.
- Just looking at the movies you can guess what are the eigenvalues and eigenvectors of the featured matrix. In particular it is easy to see whether an eigenvalue is positive, negative, zero, or a complex number, ... You can also approximately calculate which matrix is featured in each movie.
Place the cursor over the image to start the animation.
|
|
|
|
|
|
|
|
|
|
- In this file(updated), you will find sample problems formatted similarly to those on the exam. Note that some sample problems contain more items than would appear on the actual exam; I will include at most three small items per problem. Check the website on Monday for any updates to this sample file.
- Before I present the method of finding the inverse of an invertible matrix using cofactors, I point out that a more efficient way to find the inverse of an invertible $3\!\times\!3$ matrix is the method presented earlier where we calculated the inverse $A^{-1}$ by row reducing the $3\times 6$ matrix $[A | I_3]$.
- Let \[ A = \left[\! \begin{array}{cc} a & b \\ c & d \end{array} \!\right]. \] Then without any conditions on the matrix $A$ we have \[ \left[\! \begin{array}{cc} a & b \\ c & d \end{array} \!\right] \left[\! \begin{array}{rr} d & -b \\ -c & a \end{array} \!\right] = (ad-bc) \left[\! \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \!\right]. \] Therefore $A$ is invertable if and only if $\det(A) = ad-bc \neq 0.$ If $\det(A) = ad-bc \neq 0,$ then \[ A^{-1} = \frac{1}{ad-bc} \left[\! \begin{array}{rr} d & -b \\ - c & a \end{array} \!\right] = \frac{1}{ad-bc} \left[\! \begin{array}{rr} d & -c \\ -b & a \end{array} \!\right]^{\top} \]
- It is truly amazing that the same pattern holds for a $3\!\times\!3$ matrix. We just have to take into account that the definition of the determinant for a $3\!\times\!3$ matrix is more complicated and the determinant can be expressed as three different looking cofactor expensions.
- Let \[ A = \left[\! \begin{array}{rrr} a & b & c \\ d & e & f \\ g & h & i \end{array} \!\right]. \] Recall that \begin{align*} \require{bbox} \det(A) & = a \left(\bbox[yellow]{\left|\! \begin{array}{cc} e & f \\ h & i \end{array} \!\right|}\right) + b \left(\bbox[yellow]{-\left|\! \begin{array}{cc} d & f \\ g & i \end{array} \!\right|}\right) + c \left(\bbox[yellow]{\left|\! \begin{array}{cc} d & e \\ g & h \end{array} \!\right|}\right) \\ & = d \left(\bbox[cyan]{-\left|\! \begin{array}{cc} b & c \\ h & i \end{array} \!\right|} \right) + e \left(\bbox[cyan]{\left|\! \begin{array}{cc} a & c \\ g & i \end{array} \!\right|}\right) + f \left(\bbox[cyan]{-\left|\! \begin{array}{cc} a & b \\ g & h \end{array} \!\right|}\right) \\ & = g \left(\bbox[#FF88FF]{\left|\! \begin{array}{cc} b & c \\ e & f \end{array} \!\right|}\right) + h \left(\bbox[#FF88FF]{-\left|\! \begin{array}{cc} a & c \\ d & f \end{array} \!\right|}\right) + i \left(\bbox[#FF88FF]{\left|\! \begin{array}{cc} a & b \\ d & e \end{array} \!\right|}\right) \\ & = aei + bfg +cdh - afh - bdi - ceg. \end{align*}
- Then without any assumptions on the $3\!\times\!3$ matrix $A$ we have \[ \require{bbox} \left[\! \begin{array}{rrr} a & b & c \\ d & e & f \\ g & h & i \end{array} \!\right] \left[\! \begin{array}{rrr} \bbox[yellow]{\left|\! \begin{array}{cc} e & f \\ h & i \end{array} \!\right|} & \bbox[cyan]{ -\left|\! \begin{array}{cc} b & c \\ h & i \end{array} \!\right|} & \bbox[#FF88FF]{ \left|\! \begin{array}{cc} b & c \\ e & f \end{array} \!\right|} \\[6pt] \bbox[yellow]{ -\left|\! \begin{array}{cc} d & f \\ g & i \end{array} \!\right|} & \bbox[cyan]{ \left|\! \begin{array}{cc} a & c \\ g & i \end{array} \!\right|} & \bbox[#FF88FF]{ -\left|\! \begin{array}{cc} a & c \\ d & f \end{array} \!\right|} \\[6pt] \bbox[yellow]{ \left|\! \begin{array}{cc} d & e \\ g & h \end{array} \!\right|} & \bbox[cyan]{ -\left|\! \begin{array}{cc} a & b \\ g & h \end{array} \!\right|} & \bbox[#FF88FF]{ \left|\! \begin{array}{cc} a & b \\ d & e \end{array} \!\right|} \end{array} \!\right] = \] (here we use the definition of matrix multiplication to calculate the product) \[ = \require{bbox} \left[\! \begin{array}{ccc} \bbox[yellow]{ a \left|\! \begin{array}{cc} e & f \\ h & i \end{array} \!\right| - b \left|\! \begin{array}{cc} d & f \\ g & i \end{array} \!\right| + c \left|\! \begin{array}{cc} d & e \\ g & h \end{array} \!\right|} \ & \bbox[cyan]{ - a \left|\! \begin{array}{cc} b & c \\ h & i \end{array} \!\right| + b \left|\! \begin{array}{cc} a & c \\ g & i \end{array} \!\right| - c \left|\! \begin{array}{cc} a & b \\ g & h \end{array} \!\right|} \ & \bbox[#FF88FF]{ a \left|\! \begin{array}{cc} b & c \\ e & f \end{array} \!\right| - b \left|\! \begin{array}{cc} a & c \\ d & f \end{array} \!\right| + c \left|\! \begin{array}{cc} a & b \\ d & e \end{array} \!\right|} \\[14pt] \bbox[yellow]{ d \left|\! \begin{array}{cc} e & f \\ h & i \end{array} \!\right| - e \left|\! \begin{array}{cc} d & f \\ g & i \end{array} \!\right| + f \left|\! \begin{array}{cc} d & e \\ g & h \end{array} \!\right|} \ & \bbox[cyan]{ - d \left|\! \begin{array}{cc} b & c \\ h & i \end{array} \!\right| + e \left|\! \begin{array}{cc} a & c \\ g & i \end{array} \!\right| - f \left|\! \begin{array}{cc} a & b \\ g & h \end{array} \!\right|} \ & \bbox[#FF88FF]{ d \left|\! \begin{array}{cc} b & c \\ e & f \end{array} \!\right| - e \left|\! \begin{array}{cc} a & c \\ d & f \end{array} \!\right| + f \left|\! \begin{array}{cc} a & b \\ d & e \end{array} \!\right|} \\[14pt] \bbox[yellow]{ g \left|\! \begin{array}{cc} e & f \\ h & i \end{array} \!\right| - h \left|\! \begin{array}{cc} d & f \\ g & i \end{array} \!\right| + i \left|\! \begin{array}{cc} d & e \\ g & h \end{array} \!\right|} \ & \bbox[cyan]{ - g \left|\! \begin{array}{cc} b & c \\ h & i \end{array} \!\right| + h \left|\! \begin{array}{cc} a & c \\ g & i \end{array} \!\right| - i \left|\! \begin{array}{cc} a & b \\ g & h \end{array} \!\right|} \ & \bbox[#FF88FF]{ g \left|\! \begin{array}{cc} b & c \\ e & f \end{array} \!\right| - h \left|\! \begin{array}{cc} a & c \\ d & f \end{array} \!\right| + i \left|\! \begin{array}{cc} a & b \\ d & e \end{array} \!\right|} \end{array} \!\right] = \] (now we notice that each colored entry in the preceding matrix is a cofactor expension of a $3\!\times\!3$ determinant; so each colored entry we write as a determinant; so the entry of the preceding matrix are $3\!\times\!3$ determinants) \[ = \left[\! \begin{array}{ccc} \bbox[yellow]{\left|\! \begin{array}{ccc} a & b & c \\ d & e & f \\ g & h & i \end{array} \!\right|} & \bbox[cyan]{\left|\! \begin{array}{ccc} a & b & c \\ a & b & c \\ g & h & i \end{array} \!\right|} & \bbox[#FF88FF]{ \left|\! \begin{array}{ccc} a & b & c \\ d & e & f \\ a & b & c \end{array} \!\right|} \\[6pt] \bbox[yellow]{ \left|\! \begin{array}{ccc} d & e & f \\ d & e & f \\ g & h & i \end{array} \!\right| } & \bbox[cyan]{\left|\! \begin{array}{ccc} a & b & c \\ d & e & f \\ g & h & i \end{array} \!\right|} & \bbox[#FF88FF]{ \left|\! \begin{array}{ccc} a & b & c \\ d & e & f \\ d & e & f \end{array} \!\right|} \\[6pt] \bbox[yellow]{\left|\! \begin{array}{ccc} g & h & i \\ d & e & f \\ g & h & i \end{array} \!\right|} & \bbox[cyan]{ \left|\! \begin{array}{ccc} a & b & c \\ g & h & i \\ g & h & i \end{array} \!\right|} & \bbox[#FF88FF]{ \left|\! \begin{array}{ccc} a & b & c \\ d & e & f \\ g & h & i \end{array} \!\right| } \end{array} \!\right] = \] (now looking carefully at each of nine determinants, we see that on the diagonal we have $\det(A)$ and off-diagonal we have determinants with two identical rows, so these are equal to $0$) \[ =\left[\! \begin{array}{ccc} \bbox[yellow]{ \det(A)} & \bbox[cyan]{0} & \bbox[#FF88FF]{0} \\[6pt] \bbox[yellow]{ 0} & \bbox[cyan]{\det(A)} & \bbox[#FF88FF]{0} \\[6pt] \bbox[yellow]{0} & \bbox[cyan]{0} & \bbox[#FF88FF]{\det(A)} \end{array} \!\right] = \det(A) \left[\! \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right]. \]
- In conclusion, without any conditions on the $3\!\times\!3$ matrix $A$ we have \[ \require{bbox} \left[\! \begin{array}{rrr} a & b & c \\ d & e & f \\ g & h & i \end{array} \!\right] \left[\! \begin{array}{rrr} \bbox[yellow]{\left|\! \begin{array}{cc} e & f \\ h & i \end{array} \!\right|} & \bbox[cyan]{ -\left|\! \begin{array}{cc} b & c \\ h & i \end{array} \!\right|} & \bbox[#FF88FF]{ \left|\! \begin{array}{cc} b & c \\ e & f \end{array} \!\right|} \\[6pt] \bbox[yellow]{ -\left|\! \begin{array}{cc} d & f \\ g & i \end{array} \!\right|} & \bbox[cyan]{ \left|\! \begin{array}{cc} a & c \\ g & i \end{array} \!\right|} & \bbox[#FF88FF]{ -\left|\! \begin{array}{cc} a & c \\ d & f \end{array} \!\right|} \\[6pt] \bbox[yellow]{ \left|\! \begin{array}{cc} d & e \\ g & h \end{array} \!\right|} & \bbox[cyan]{ -\left|\! \begin{array}{cc} a & b \\ g & h \end{array} \!\right|} & \bbox[#FF88FF]{ \left|\! \begin{array}{cc} a & b \\ d & e \end{array} \!\right|} \end{array} \!\right] = \det(A) \left[\! \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array} \!\right]. \]
- The preceding formula shows that $A$ is invertible if and only if $\det(A) \neq 0.$ If $\det(A) \neq 0,$ then \[ A^{-1} = \frac{1}{\det(A)} \left[\! \begin{array}{rrr} \bbox[yellow]{\left|\! \begin{array}{cc} e & f \\ h & i \end{array} \!\right|} & \bbox[cyan]{ -\left|\! \begin{array}{cc} b & c \\ h & i \end{array} \!\right|} & \bbox[#FF88FF]{ \left|\! \begin{array}{cc} b & c \\ e & f \end{array} \!\right|} \\[6pt] \bbox[yellow]{ -\left|\! \begin{array}{cc} d & f \\ g & i \end{array} \!\right|} & \bbox[cyan]{ \left|\! \begin{array}{cc} a & c \\ g & i \end{array} \!\right|} & \bbox[#FF88FF]{ -\left|\! \begin{array}{cc} a & c \\ d & f \end{array} \!\right|} \\[6pt] \bbox[yellow]{ \left|\! \begin{array}{cc} d & e \\ g & h \end{array} \!\right|} & \bbox[cyan]{ -\left|\! \begin{array}{cc} a & b \\ g & h \end{array} \!\right|} & \bbox[#FF88FF]{ \left|\! \begin{array}{cc} a & b \\ d & e \end{array} \!\right|} \end{array} \!\right]. \] Notice that in the matrix on the right we have cofactors of the matrix $A.$
- The preceding formula for the inverse is commonly written with the transpose of the matrix involving the cofactors. \[ A^{-1} = \frac{1}{\det(A)} \left[\! \begin{array}{rrr} \bbox[yellow]{\left|\! \begin{array}{cc} e & f \\ h & i \end{array} \!\right|} & \bbox[yellow]{-\left|\! \begin{array}{cc} d & f \\ g & i \end{array} \!\right|} & \bbox[yellow]{\left|\! \begin{array}{cc} d & e \\ g & h \end{array} \!\right|} \\ \bbox[cyan]{-\left|\! \begin{array}{cc} b & c \\ h & i \end{array} \!\right|} & \bbox[cyan]{\left|\! \begin{array}{cc} a & c \\ g & i \end{array} \!\right|} & \bbox[cyan]{-\left|\! \begin{array}{cc} a & b \\ g & h \end{array} \!\right|} \\ \bbox[#FF88FF]{\left|\! \begin{array}{cc} b & c \\ e & f \end{array} \!\right|} & \bbox[#FF88FF]{-\left|\! \begin{array}{cc} a & c \\ d & f \end{array} \!\right|} & \bbox[#FF88FF]{\left|\! \begin{array}{cc} a & b \\ d & e \end{array} \!\right|} \end{array} \!\right]^{\mathbf{\top}}. \] Please recall the definition of the cofactors of $A$. With the definition of the cofactors the above formula for the inverse is simply \[ A^{-1} = \frac{1}{\det(A)} \left[\! \begin{array}{rrr} \bbox[yellow]{C_{11}} & \bbox[yellow]{C_{21}} & \bbox[yellow]{C_{31}} \\ \bbox[cyan]{C_{12}} & \bbox[cyan]{C_{22}} & \bbox[cyan]{C_{32}} \\ \bbox[#FF88FF]{C_{13}} & \bbox[#FF88FF]{C_{23}} & \bbox[#FF88FF]{C_{33}} \end{array} \!\right]^{\mathbf{\top}}. \]
- The pattern presented above for a $3\!\times\!3$ matrix holds for any $n\!\times\!n$ matrix: \[ \left[\! \begin{array}{cccc} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nn} \end{array} \!\right] \left[\! \begin{array}{cccc} C_{11} & C_{21} & \cdots & C_{n1} \\ C_{12} & C_{22} & \cdots & C_{n2} \\ \vdots & \vdots & \ddots & \vdots \\ C_{1n} & C_{2n} & \cdots & C_{nn} \end{array} \!\right] = \det(A) I_n. \] A justification for this identity is the definition of determinant using the cofactor expansions along the rows of $A$ and the fact that a determinant with two identical rows is equal to $0.$
- Let us calculate the inverse of a specific $3\!\times\!3$ matrix. Consider \[ A = \left[\! \begin{array}{ccc} 1 & 2 & 6 \\ 3 & 5 & 7 \\ 4 & 8 & 9 \end{array} \!\right]. \] Let us first evaluate the determinant of this matrix in three different ways, by performing the cofactor expansion along each column: \begin{align*} \det A & = 1*(\bbox[yellow]{+(-11)})+2*(\bbox[yellow]{-(-1)})+6*(\bbox[yellow]{+(4)}) \\ & = 3*(\bbox[cyan]{-(-30)})+5*(\bbox[cyan]{+(-15)})+7*(\bbox[cyan]{-(0)}) \\ & = 4*(\bbox[#FF88FF]{+(-16)})+8*(\bbox[#FF88FF]{-(-11)})+9*(\bbox[#FF88FF]{+(-1)}) \\ & = 15. \end{align*} Since we are doing this three different ways, there is a lot of checking going on in the above calculations.
- Based on the three cofactor expansions above we can write the inverse of the given matrix $A:$ \[ A^{-1} = \frac{1}{15} \left[\! \begin{array}{rrr} \bbox[yellow]{-11} & \bbox[cyan]{30} & \bbox[#FF88FF]{-16} \\ \bbox[yellow]{1} & \bbox[cyan]{-15} & \bbox[#FF88FF]{11} \\ \bbox[yellow]{4} & \bbox[cyan]{0} & \bbox[#FF88FF]{-1} \end{array} \!\right]. \] To verify, calculate \[ \left[\! \begin{array}{ccc} 1 & 2 & 6 \\ 3 & 5 & 7 \\ 4 & 8 & 9 \end{array} \!\right] \left[\! \begin{array}{rrr} \bbox[yellow]{-11} & \bbox[cyan]{30} & \bbox[#FF88FF]{-16} \\ \bbox[yellow]{1} & \bbox[cyan]{-15} & \bbox[#FF88FF]{11} \\ \bbox[yellow]{4} & \bbox[cyan]{0} & \bbox[#FF88FF]{-1} \end{array} \!\right] = \left[\! \begin{array}{rrr} \bbox[yellow]{15} & \bbox[cyan]{0} & \bbox[#FF88FF]{0} \\ \bbox[yellow]{0} & \bbox[cyan]{15} & \bbox[#FF88FF]{0} \\ \bbox[yellow]{0} & \bbox[cyan]{0} & \bbox[#FF88FF]{15} \end{array} \!\right] \]
- Suggested problems for Section 3.3: 2, 4, 6, 7, 9, 13, 14, 18, 19-24, 27, 30, 31, 32.
- We discussed Section 3.2 Properties of determinants. Suggested problems for Section 3.2: 5, 7, 9, 11, 16-20 (even), 21, 25, 31, 33, 34, 35, 40c
-
Let \(m \in \mathbb{N}\). Let \(i,j \in \mathbb{N}\) be such that \(i \lt j \lt n\). In this item I want to prove that the determinant of the elementary matrix obtained from the identity matrix by exchanging the positions of \(i\)-th and \(j\)-th row equals to \(-1\).
Below is a "click-by-click" proof of the fact that the determinant of the elementary matrix obtained from the identity matrix by exchanging two rows (or, equivalently two columns) equals to $-1.$ There are nine steps in this proof. I describe each step below.- This is the determinant that we want to calculate.
- I emphasize that the $i$-th and $j$-th row in the identity matrix are interchanged.
- We will calculate the $n\!\times\!n$ determinant by cofactor expansion along the $i$-th row.
- Since the only nonzero entry in the $i$-th row is at the $j$-th place, the cofactor expansion equals $(-1)^{i+j}$ multiplied by an $(n-1)\times(n-1)$ determinant.
- We will calculate the $(n-1)\!\times\!(n-1)$ determinant using cofactor expansion along the $(j-1)$-st row. Notice that the only nonzero entry in the $(j-1)$-st row is $1$ which is at $i$-th position.
- The previous $(n-1)\!\times\!(n-1)$ determinant calculates to $(-1)^{i+j-1}$ multiplied by the $(n-2)\!\times\!(n-2)$ determinant of the identity matrix.
- The $(n-2)\!\times\!(n-2)$ determinant of the identity matrix calculates to $1$.
- $(-1)^{i+j}(-1)^{i+j-1} = (-1)^{2i+2j-1}$.
- $(-1)^{2i+2j-1} = -1$.
All entries left blank in the determinant below are zeros.
Click on the image for a step by step proof.
-
A different way to prove that the determinant of the elementary matrix obtained from the identity matrix by exchanging two rows (or, equivalently two columns) equals to $-1$ is by first observing the following fact
Let $n$ be a positive integer greater than $2$ and let $k\in\{1,2,\ldots,n\}.$ Let $A$ be an $n\!\times\!n$ matrix in which $k$-th row ($k$-th column, respectively) is the $k$-th row ($k$-th column, respectively) of the identity matrix $I_n.$ Then the determinant of $A$ equals to the determinant of the $(n-1)\!\times\!(n-1)$ matrix obtained from $A$ by removing its $k$-th row and its $k$-th column.
This fact follows from the cofactor expansion calculation of a determinant, Theorem 1 in Section 3.1.
- For example, with the third row being the third row of the identity matrix $I_4:$ \[ \require{bbox} \left| \begin{array}{cccc} a & b & \bbox[yellow]{c} & d \\ e & f & \bbox[yellow]{g} & h \\ \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{1} & \bbox[yellow]{0} \\ i & j & \bbox[yellow]{k} & l \end{array} \right| = (-1)^{3+3} \left| \begin{array}{ccc} a & b & d \\ e & f & h \\ i & j & l \end{array} \right| =\left| \begin{array}{ccc} a & b & d \\ e & f & h \\ i & j & l \end{array} \right|. \]
-
This procedure is repeatable as many times as many rows or columns of the identity matrix we have in a square matrix. That is
Let $n$ be a positive integer greater than $2,$ $l \in \{1,2,\ldots,n\}$ and let $k_1,\ldots,k_l\in\{1,2,\ldots,n\}$ be distinct. Let $A$ be an $n\!\times\!n$ matrix with the following property:Then the determinant of $A$ equals to the determinant of the $(n-l)\!\times\!(n-l)$ matrix obtained from $A$ by removing all of its rows with indexes $k_1,\ldots,k_l$ and all of its columns with indexes $k_1,\ldots,k_l.$For every $j \in \{1,\ldots,l\}$ we have that $k_j$-th row is the $k_j$-th row of the identity matrix $I_n$ OR $k_j$-th column is the $k_j$-th column of the identity matrix $I_n$.
- For example, with the third row being the third row of the identity matrix $I_6$ and the fifth column being the fifth column of the identity matrix $I_6:$ (here $l = 2$ and $k_1 = 3, k_2 = 5$) \begin{align*} \require{bbox} \left| \begin{array}{cccccc} a & b & \bbox[yellow]{c} & d & 0 & e \\ f & g & \bbox[yellow]{h} & i & 0 & j \\ \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{1} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0} \\ k & l & \bbox[yellow]{m} & n & 0 & o \\ p & q & \bbox[yellow]{r} & s & 1 & t \\ u & v & \bbox[yellow]{w} & x & 0 & y \end{array} \right| & = \left| \begin{array}{ccccc} a & b & d & 0 & e \\ f & g & i & 0 & j \\ k & l & n & 0 & o \\ p & q & s & 1 & t \\ u & v & x & 0 & y \end{array} \right| \\[6pt] & = \left| \begin{array}{ccccc} a & b & d & \bbox[yellow]{0} & e \\ f & g & i & \bbox[yellow]{0} & j \\ k & l & n & \bbox[yellow]{0} & o \\ \bbox[yellow]{p} & \bbox[yellow]{q} & \bbox[yellow]{s} & \bbox[yellow]{1} & \bbox[yellow]{t} \\ u & v & x & \bbox[yellow]{0} & y \end{array} \right| \\[6pt] & = \left| \begin{array}{cccc} a & b & d & e \\ f & g & i & j \\ k & l & n & o \\ u & v & x & y \end{array} \right|. \end{align*}
- Or, with the third row being the third row of the identity matrix $I_6$ and the second column being the second column of the identity matrix $I_6$ and the fifth column being the fifth column of the identity matrix $I_6:$ (here $l = 3$ and $k_1 = 2, k_2 = 3, k_3 = 5$) \begin{equation*} \require{bbox} \left| \begin{array}{cccccc} a & \bbox[yellow]{0} & \bbox[yellow]{b} & c & \bbox[yellow]{0} & d \\ \bbox[yellow]{e} & \bbox[yellow]{1} & \bbox[yellow]{f} & \bbox[yellow]{g} & \bbox[yellow]{0} & \bbox[yellow]{h} \\ \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{1} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0} \\ i & \bbox[yellow]{0} & \bbox[yellow]{j} & k & \bbox[yellow]{0} & l \\ \bbox[yellow]{m} & \bbox[yellow]{0} & \bbox[yellow]{n} & \bbox[yellow]{o} & \bbox[yellow]{1} & \bbox[yellow]{p} \\ q & \bbox[yellow]{0} & \bbox[yellow]{r} & s & \bbox[yellow]{0} & t \end{array} \right| = \left| \begin{array}{ccc} a & c & d \\ i & k & l \\ q & s & t \end{array} \right|. \end{equation*}
- Let $n$ be a positive integer greater than $2$ and $i,j \in \{1,2,\ldots,n\}$ are such that $i \lt j.$ For the $n\!\times\!n$ elementary matrix in which $i$-th and $j$-th rows exchanged places in the identity matrix $I_n$, then all the rows and the columns with indexes different from $i$ and $j$ can be removed. Thus, the determinant of this elementary matrix equals \[ \left| \begin{array}{cc} 0 & 1 \\ 1 & 0 \end{array} \right| = -1. \]
- The following \(7\times 7\) determinant is obtained from the identity matrix by exchanging the third and the fifth row. Below, at each step we remove a row and a column which comes from the corresponding identity matrix: (at the first step, the first row and column, then again the first row and column, then the second row and column, then again the second row and column, then, finally, the third row and column) \begin{align*} \require{bbox} \left| \begin{array}{ccccccc} \bbox[yellow]{1} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0} \\ \bbox[yellow]{0} & 1 & 0 & 0 & 0 & 0 & 0\\ \bbox[yellow]{0} & 0 & 0 & 0 & 0 & 1 & 0\\ \bbox[yellow]{0} & 0 & 0 & 1 & 0 & 0 & 0\\ \bbox[yellow]{0} & 0 & 0 & 0 & 1 & 0 & 0\\ \bbox[yellow]{0} & 0 & 1 & 0 & 0 & 0 & 0 \\ \bbox[yellow]{0} & 0 & 0 & 0 & 0 & 0 & 1 \end{array} \right| &= \left| \begin{array}{cccccc} \bbox[yellow]{1} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0}\\ \bbox[yellow]{0} & 0 & 0 & 0 & 1 & 0\\ \bbox[yellow]{0} & 0 & 1 & 0 & 0 & 0\\ \bbox[yellow]{0} & 0 & 0 & 1 & 0 & 0\\ \bbox[yellow]{0} & 1 & 0 & 0 & 0 & 0 \\ \bbox[yellow]{0} & 0 & 0 & 0 & 0 & 1 \end{array} \right| \\[6pt] &= \left| \begin{array}{ccccc} 0 & \bbox[yellow]{0} & 0 & 1 & 0\\ \bbox[yellow]{0} & \bbox[yellow]{1} & \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{0}\\ 0 & \bbox[yellow]{0} & 1 & 0 & 0\\ 1 & \bbox[yellow]{0} & 0 & 0 & 0 \\ 0 & \bbox[yellow]{0} & 0 & 0 & 1 \end{array} \right| \\[6pt] &= \left| \begin{array}{cccc} 0 & \bbox[yellow]{0} & 1 & 0\\ \bbox[yellow]{0} & \bbox[yellow]{1} & \bbox[yellow]{0} & \bbox[yellow]{0}\\ 1 & \bbox[yellow]{0} & 0 & 0 \\ 0 & \bbox[yellow]{0} & 0 & 1 \end{array} \right| \\[6pt] &= \left| \begin{array}{cccc} 0 & 1 & \bbox[yellow]{0}\\ 1 & 0 & \bbox[yellow]{0} \\ \bbox[yellow]{0} & \bbox[yellow]{0} & \bbox[yellow]{1} \end{array} \right| \\[6pt] & = \left| \begin{array}{cc} 0 & 1 \\ 1 & 0 \end{array} \right|\\[6pt] & = -1. \end{align*}
- We did Section 3.1 today. Suggested problems for Section 3.1: 1, 3, 5, 9, 11, 13, 17, 20, 21, 22, 25-32, 37, 41, 42
-
Today in class we explored a problem inspired by the picture below. No numbers are given just the picture. In the picture below we are given two bases of $\mathbb{R}^2$, one blue and one purple:
\[
\color{blue}{\mathcal B} = \bigl\{ \color{blue}{\mathbf{b}_1}, \color{blue}{\mathbf{b}_2} \bigr\}, \quad \color{purple}{\mathcal C} = \bigl\{ \color{purple}{\mathbf{c}_1}, \color{purple}{\mathbf{c}_2} \bigr\}
\]
- Suggested exercises for Section 4.7: Change of Basis are 2, 3, 4, 6, 8, 9, 11, 12, 19, 20.
-
A brief review of the Change of Coordinates Matrix (this is my preferred name) follows. Let $m, n \in \mathbb{N}$ and $m\leq n$. Let $\mathcal{H}$ be a subspace of $\mathbb{R}^n$ and let
\[
\mathcal{A} = \bigl\{\mathbf{a}_1,\ldots,\mathbf{a}_m\bigr\}
\]
and
\[
\mathcal{B} = \bigl\{\mathbf{b}_1,\ldots,\mathbf{b}_m\bigr\}
\]
be two bases of $\mathcal{H}.$ By definition of a basis this implies that
\[
\mathcal{H} = \operatorname{Span}\bigl\{\mathbf{a}_1,\ldots,\mathbf{a}_m\bigr\} = \operatorname{Span}\bigl\{\mathbf{b}_1,\ldots,\mathbf{b}_m\bigr\}
\]
and both
\[
\mathcal{A} = \bigl\{\mathbf{a}_1,\ldots,\mathbf{a}_m\bigr\} \quad \text{and} \quad \mathcal{B} = \bigl\{\mathbf{b}_1,\ldots,\mathbf{b}_m\bigr\}
\]
are linearly independent. We proved in class that the change of coordinates matrix $\displaystyle\underset{\mathcal{B}\leftarrow\mathcal{A}}{P}$ is given by
\[
\underset{\mathcal{B}\leftarrow\mathcal{A}}{P} = \Bigl[ \bigl[\mathbf{a}_1\bigr]_{\mathcal{B}} \ \cdots \ \bigl[ \mathbf{a}_m\bigr]_{\mathcal{B}} \Bigr]
\]
and analogously
\[
\underset{\mathcal{A}\leftarrow\mathcal{B}}{P} = \Bigl[ \bigl[\mathbf{b}_1\bigr]_{\mathcal{A}} \ \cdots \ \bigl[ \mathbf{b}_m\bigr]_{\mathcal{A}} \Bigr].
\]
But, how to calculate
\[
\bigl[\mathbf{a}_1\bigr]_{\mathcal{B}}, \ldots,\bigl[ \mathbf{a}_m\bigr]_{\mathcal{B}}?
\]
Let us look at
\[
\bigl[\mathbf{a}_1\bigr]_{\mathcal{B}} = \left[\!\begin{array}{c}
x_1 \\ \vdots \\ x_m
\end{array}\!\right].
\]
To find the real numbers $x_1, \ldots, x_m$ we have to solve the nonhomogeneous vector equation
\[
x_1 \mathbf{b}_1 + x_2 \mathbf{b}_2 + \cdots + x_m \mathbf{b}_m = \mathbf{a}_1.
\]
To solve the preceding equation we row reduce
\[
\Bigl[\!\begin{array}{cccc|c}
\mathbf{b}_1 & \mathbf{b}_2 & \cdots & \mathbf{b}_m & \mathbf{a}_1\end{array}\!\Bigr].
\]
Since the vectors $\mathbf{b}_1, \mathbf{b}_2, \ldots, \mathbf{b}_m$ are linearly independent, the Reduced Row Echelon Form of the preceding augmented matrix has the following form
\[
\left[\!\begin{array}{cccc|c}
1 & 0 & \cdots & 0 & \text{the solution for} \ x_1 \\
0 & 1 & \cdots & 0 & \text{the solution for} \ x_2 \\
\vdots & \vdots & \ddots & \vdots & \vdots \\
0 & 0 & \cdots & 1 & \text{the solution for} \ x_m \\
0 & 0 & \cdots & 0 & 0 \\
\vdots & \vdots & \ddots & \vdots & \vdots \\
0 & 0 & \cdots & 0 & 0
\end{array}\!\right].
\]
Notice that in the preceding matrix the bottom zero rows are present only in the case when $n \gt m.$ If $n \gt m$, then there are exactly $n-m$ rows of zeros. Also notice that the above system must be consistent since the vector $\mathbf{a}_1$ is in the span of the vectors $\mathbf{b}_1, \mathbf{b}_2, \ldots, \mathbf{b}_m.$
To solve the nonhomogeneous vector equations \[ x_1 \mathbf{b}_1 + x_2 \mathbf{b}_2 + \cdots + x_m \mathbf{b}_m = \mathbf{a}_2, \quad \ldots, \quad x_1 \mathbf{b}_1 + x_2 \mathbf{b}_2 + \cdots + x_m \mathbf{b}_m = \mathbf{a}_m, \] we just build the bigger augmented matrix: \[ \Bigl[\!\begin{array}{cccc|cccc} \mathbf{b}_1 & \mathbf{b}_2 & \cdots & \mathbf{b}_m & \mathbf{a}_1 & \mathbf{a}_2 & \cdots & \mathbf{a}_m \end{array}\!\Bigr]. \] Since the vectors $\mathbf{b}_1, \ldots, \mathbf{b}_m$ are linearly independent, the RREF off the matrix whose columns are the vectors of $\mathcal{B}$ consists of the identity matrix $I_m$ and $n-m$ zero rows at the bottom if $n\gt m.$ Therefore \[ \Bigl[\!\begin{array}{ccc|ccc} \mathbf{b}_1 & \cdots & \mathbf{b}_m & \mathbf{a}_1 & \cdots & \mathbf{a}_m \end{array}\!\Bigr] \sim \cdots \sim \left[\! \begin{array}{c|c} I_m & \underset{\mathcal{B}\leftarrow\mathcal{A}}{P} \\ 0 & 0 \end{array} \!\right]. \] In the preceding RREF, the zero matrices at the bottom are present only if $n-m \gt 0.$ Then, if $n-m \gt 0,$ these matrices are of the size $(n-m)\!\times\!m;$ they both have $m$ columns and $n-m$ rows consisting of zeros. -
In the next example we are given two bases of a two-dimensional subspace of $\mathbb{R}^4$ and we are asked to find a change of coordinate matrices between these two bases:
\[
\mathcal{H} = \operatorname{Span}\left\{\left[\!\begin{array}{c}
1 \\ 2 \\ 1 \\ 3
\end{array}\!\right], \left[\!\begin{array}{c}
2 \\ 3 \\ 1 \\ 5
\end{array}\!\right]\right\} = \operatorname{Span}\left\{\left[\!\begin{array}{c}
2 \\ 5 \\ 3 \\ 7
\end{array}\!\right], \left[\!\begin{array}{r}
1 \\ 0 \\ -1 \\ 1
\end{array}\!\right]\right\}.
\]
Set
\[
\mathcal{A} = \left\{\left[\!\begin{array}{c}
1 \\ 2 \\ 1 \\ 3
\end{array}\!\right], \left[\!\begin{array}{c}
2 \\ 3 \\ 1 \\ 5
\end{array}\!\right]\right\}, \qquad \mathcal{B} = \left\{\left[\!\begin{array}{c}
2 \\ 5 \\ 3 \\ 7
\end{array}\!\right], \left[\!\begin{array}{r}
1 \\ 0 \\ -1 \\ 1
\end{array}\!\right]\right\}.
\]
To calculate $\displaystyle\underset{\mathcal{B}\leftarrow\mathcal{A}}{P}$ we need to row reduce the matrix
\[
\left[\!\begin{array}{cr|cc}
2 & 1 & 1 & 2 \\
5 & 0 & 2 & 3 \\
3 & -1 & 1 & 1 \\
7 & 1 & 3 & 5
\end{array}\!\right]
\]
The RREF of the preceding matrix will certainly include fractions. Therefore we rather find $\displaystyle\underset{\mathcal{A}\leftarrow\mathcal{B}}{P}$ for which we need to row reduce (without fractions)
\[
\left[\!\begin{array}{cc|cr}
1 & 2 & 2 & 1 \\
2 & 3 & 5 & 0 \\
1 & 1 & 3 & -1 \\
3 & 5 & 7 & 1
\end{array}\!\right] \sim \cdots \sim
\left[\!\begin{array}{cc|rr}
1 & 0 & 4 & -3 \\
0 & 1 & -1 & 2 \\
0 & 0 & 0 & 0 \\
0 & 0 & 0 & 0
\end{array}\!\right].
\]
Hence
\[
\underset{\mathcal{A}\leftarrow\mathcal{B}}{P} = \left[\!\begin{array}{rr}
4 & -3 \\
-1 & 2
\end{array}\!\right].
\]
Let us verify this calculation. Is it true that:
\[
\left[\!\begin{array}{c}
2 \\ 5 \\ 3 \\ 7
\end{array}\!\right] = (4) \left[\!\begin{array}{c}
1 \\ 2 \\ 1 \\ 3
\end{array}\!\right] + (-1)\left[\!\begin{array}{c}
2 \\ 3 \\ 1 \\ 5
\end{array}\!\right], \qquad \left[\!\begin{array}{r}
1 \\ 0 \\ -1 \\ 1
\end{array}\!\right] = (-3) \left[\!\begin{array}{c}
1 \\ 2 \\ 1 \\ 3
\end{array}\!\right] + (2) \left[\!\begin{array}{c}
2 \\ 3 \\ 1 \\ 5
\end{array}\!\right]?
\]
Yes. Therefore the following equalities are correct:
\[
\bigl[ \mathbf{b}_1\bigr]_{\mathcal{A}} = \left[\!\begin{array}{r}
4 \\ -1
\end{array}\!\right], \qquad \bigl[ \mathbf{b}_2\bigr]_{\mathcal{A}} = \left[\!\begin{array}{r}
-3 \\ 2
\end{array}\!\right].
\]
Hence, $\displaystyle\underset{\mathcal{A}\leftarrow\mathcal{B}}{P}$ is correct.
We have \[ \underset{\mathcal{B}\leftarrow\mathcal{A}}{P} = \left(\underset{\mathcal{A}\leftarrow\mathcal{B}}{P}\right)^{-1} = \frac{1}{5} \left[\!\begin{array}{rr} 2 & 3 \\ 1 & 4 \end{array}\!\right]. \] Verify this: \[ \left[\!\begin{array}{c} 1 \\ 2 \\ 1 \\ 3 \end{array}\!\right] = \frac{2}{5}\left[\!\begin{array}{c} 2 \\ 5 \\ 3 \\ 7 \end{array}\!\right] + \frac{1}{5} \left[\!\begin{array}{r} 1 \\ 0 \\ -1 \\ 1 \end{array}\!\right], \qquad \left[\!\begin{array}{c} 2 \\ 3 \\ 1 \\ 5 \end{array}\!\right] = \frac{3}{5} \left[\!\begin{array}{c} 2 \\ 5 \\ 3 \\ 7 \end{array}\!\right] + \frac{4}{5} \left[\!\begin{array}{r} 1 \\ 0 \\ -1 \\ 1 \end{array}\!\right]. \] True. Therefore the following equalities are correct: \[ \bigl[ \mathbf{a}_1\bigr]_{\mathcal{B}} = \frac{1}{5}\left[\!\begin{array}{r} 2 \\ 1 \end{array}\!\right], \qquad \bigl[ \mathbf{a}_2\bigr]_{\mathcal{B}} = \frac{1}{5} \left[\!\begin{array}{r} 3 \\ 4 \end{array}\!\right]. \] Hence, $\displaystyle\underset{\mathcal{B}\leftarrow\mathcal{A}}{P}$ is correct.
-
Today, I dedicate this post to what I consider to be a fundamental theorem in linear algebra—one that, surprisingly, the author of our textbook doesn’t even present as a theorem. Here is the relevant snippet from the book.
 I will use this snippet to highlight some differences in notation that I use in class and on this website. I denote subspaces using script letters; thus, instead of \(H\) as used in the textbook, I write \(\mathcal{H}\) to denote a subspace. Additionally, for the vector \(\mathbf{0}\), I always indicate the space it belongs to:
\[
\mathbf{0}_2 = \left[\! \begin{array}{c} 0 \\ 0 \end{array} \!\right] \in \mathbb{R}^2, \quad
\mathbf{0}_3 = \left[\! \begin{array}{c} 0 \\ 0 \\ 0 \end{array} \!\right] \in \mathbb{R}^3, \quad
\mathbf{0}_4 = \left[\! \begin{array}{c} 0 \\ 0 \\ 0 \\ 0 \end{array} \!\right] \in \mathbb{R}^4.
\]
In general, I denote the zero vector in \(\mathbb{R}^n\) by \(\mathbf{0}_n\).
I will use this snippet to highlight some differences in notation that I use in class and on this website. I denote subspaces using script letters; thus, instead of \(H\) as used in the textbook, I write \(\mathcal{H}\) to denote a subspace. Additionally, for the vector \(\mathbf{0}\), I always indicate the space it belongs to:
\[
\mathbf{0}_2 = \left[\! \begin{array}{c} 0 \\ 0 \end{array} \!\right] \in \mathbb{R}^2, \quad
\mathbf{0}_3 = \left[\! \begin{array}{c} 0 \\ 0 \\ 0 \end{array} \!\right] \in \mathbb{R}^3, \quad
\mathbf{0}_4 = \left[\! \begin{array}{c} 0 \\ 0 \\ 0 \\ 0 \end{array} \!\right] \in \mathbb{R}^4.
\]
In general, I denote the zero vector in \(\mathbb{R}^n\) by \(\mathbf{0}_n\).
-
Today, I will share several important theorems and aim to explain each proof in full detail. I view mathematical proofs as consisting of three parts: the claim, the background knowledge needed, and the proof itself, which I usually break down into several steps.
As I mentioned earlier, each theorem is an implication that can be summarized as: "If \( p \), then \(q\)," where \( p \) represents the assumptions of the theorem and \(q\) represents the conclusion. To help clarify the structure of proofs, I often color-code the assumptions and relevant background facts in green, a color symbolizing approachability and friendliness, and I color the conclusion in red. This color scheme highlights the initial mystery in the connection between the assumptions (green) and the conclusion (red), emphasizing that the proofer’s task is to bridge this gap by constructing a logical path. In this language of colors, the proofer’s task is to create a green path of logical steps, starting with the assumptions, using the background knowledge as individual stepping stones, and ultimately reaching the red conclusion. In a way, the goal of the proof is to "greenify" the red, completing the logical connection.
-
Theorem below is presented in Exercise 27 and Exercise 28 in Section 2.9 (page 161) in the textbook. My presentation is different, but the content is the same. In fact, I prove the contrapositives of the statements presented in these exercises.
Theorem 1. Let $n, p, q \in \mathbb{N}.$ Let $F$ be an $n\!\times\!p$ matrix and let $G$ be an $n\!\times\!q$ matrix. If \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\operatorname{Col}(F) \subseteq \operatorname{Col}(G)} \quad \text{and} \quad \bbox[lightgreen, 6px, border:3px solid green]{\text{the columns of} \ \ F \ \ \text{are linearly independent}}, \end{equation*} then \begin{equation*} \bbox[#FFC0C0, 6px, border:3px solid red]{p \leq q}. \end{equation*}
Background Knowledge is as follows.
BK0. The definition of matrix-vector multiplication, the definition of matrix multiplication.
BK1. Let \(\mathbb{y} \in \mathbb{R}^n\). Then \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\mathbb{y} \in \operatorname{Col}(G) \quad \text{if and only if} \quad \text{there exists} \ \ \mathbb{x} \in \mathbb{R}^q \ \ \text{such that} \ \ \mathbb{y} = G \mathbb{x}}. \end{equation*}
BK2. Let \(H\) be an \(q\times p\) matrix and let \(\mathbb{x} \in \mathbb{R}^p\). Then \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{ \begin{array}{c} \text{the columns of} \ \ H \ \ \text{are linearly independent} \quad \\ \quad\quad\quad\quad \quad \text{if and only if}\quad \quad H\mathbf{x} = \mathbf{0}_q \ \Rightarrow \ \mathbf{x} = \mathbf{0}_p. \end{array}} \end{equation*} Notice that the implication \(H\mathbf{x} = \mathbf{0}_q \ \Rightarrow \ \mathbf{x} = \mathbf{0}_p\) is stated in English as: The homogeneous equation \(H\mathbf{x} = \mathbf{0}_q\) has only the trivial solution.
BK3. Let \(H\) be an \(q\times p\) matrix. The following implication holds: \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{ \text{If the columns of} \ H \ \text{are linearly independent, then} \ \ p \leq q. } \end{equation*} In English, this implication can be stated as: If the columns of a matrix are linearly independent, then the number of rows is greater than or equal to the number of columns.
Proof. Let \(\mathbf{f}_1,\ldots, \mathbf{f}_p \in \mathbb{R}^n\) be the columns of \(F\) and let \(\mathbf{g}_1,\ldots, \mathbf{g}_q \in \mathbb{R}^n\) be the columns of \(G\). That is \[ F = \bigl[ \mathbf{f}_1 \ \cdots \ \mathbf{f}_p \bigr], \qquad G = \bigl[ \mathbf{g}_1 \ \cdots \ \mathbf{g}_q \bigr]. \]
Step 1. Since for every \(j\in\{1,\ldots,p\}\) we have \(\mathbf{f}_j \in \operatorname{Col}(F)\), the assumption \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\operatorname{Col}(F) \subseteq \operatorname{Col}(G)} \end{equation*} implies that \(\mathbf{f}_j \in \operatorname{Col}(G)\). Since for every \(j\in\{1,\ldots,p\}\) we have \(\mathbf{f}_j \in \operatorname{Col}(G)\), by background knowledge BK1 we conclude that for every \(j\in\{1,\ldots,p\}\) there exists \(\mathbf{h}_j \in \mathbb{R}^q\) such that \(\mathbf{f}_j = G\mathbf{h}_j\). Set \[ H = \bigl[ \mathbf{h}_1 \ \cdots \ \mathbf{h}_p \bigr]. \] Then \(H\) is \(q\times p\) matrix and by background knowledge BK0 we have \begin{align*} GH & = G\bigl[ \mathbf{h}_1 \ \cdots \ \mathbf{h}_p \bigr] \\ & = \bigl[ G\mathbf{h}_1 \ \cdots \ G \mathbf{h}_p \bigr] \\ & = \bigl[ \mathbf{f}_1 \ \cdots \ \mathbf{f}_p \bigr] \\ & = F. \end{align*} Thus, there exists an \(q\times p\) matrix \(H\) such that \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{F = GH}. \end{equation*}
Step 2. In this step we will prove that the columns of \(H\) are linearly independent. For that proof we use background knowledge BK2. We will prove that for \(\mathbf{x} \in \mathbb{R}^p\) the following implication holds: \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{H\mathbf{x} = \mathbf{0}_q} \quad \Rightarrow \quad \bbox[#FFC0C0, 6px, border:3px solid red]{\mathbf{x} = \mathbf{0}_p}. \end{equation*} Here is the proof of this implication. (Notice how I start from green and use only known green stuff to arrive at red.) Assume \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{H\mathbf{x} = \mathbf{0}_q}. \end{equation*} Apply matrix \(G\) to both sides of the preceding green equality to get \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{GH\mathbf{x} = G\mathbf{0}_q}. \end{equation*} By Step 1 we have \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{F = GH}. \end{equation*} and by BK0 we have \(G\mathbf{0}_q = \mathbf{0}_n\). Hence \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{F\mathbf{x} = \mathbf{0}_n}. \end{equation*} By assumption \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\text{the columns of} \ \ F \ \ \text{are linearly independent}}. \end{equation*} By background knowledge BK2 we deduce that \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{F\mathbf{x} = \mathbf{0}_n \quad \Rightarrow \quad \mathbf{x} = \mathbf{0}_p}. \end{equation*} In conclusion, the implication \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{H\mathbf{x} = \mathbf{0}_q} \quad \Rightarrow \quad \bbox[#FFC0C0, 6px, border:3px solid red]{\mathbf{x} = \mathbf{0}_p} \end{equation*} is proved. By background knowledge BK2 the last implication yields that \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\text{the columns of} \ \ H \ \ \text{are linearly independent}}. \end{equation*}
Step 3. By the final result of Step 2 \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\text{the columns of} \ \ H \ \ \text{are linearly independent}}. \end{equation*} and by background knowledge BK3 \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{ \text{If the columns of} \ H \ \text{are linearly independent, then} \ \ p \leq q. } \end{equation*} we conclude \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{p \leq q}. \end{equation*}
This completes the proof.
-
In this item I state Theorem 1 in English without using a single mathematical symbol.
Theorem 1. If two matrices have the same column space and one of them has linearly independent columns, then the matrix with linearly independent columns has no more columns than the other matrix. In particular, if two matrices have the same column space and both have linearly independent columns, then the matrices have the same size.
-
In this item I prove the fundamental theorem in linear algebra. First I state the theorem in English:
To proceed with a proof, it is essential to state the theorem in full mathematical detail. Note that I have formulated the theorem as an implication.
Theorem 2. With \(n\in\mathbb{N}\), any two bases of a subspace of \(\mathbb{R}^n\) have the same number of elements.
Theorem 2 Let $n, m, k \in \mathbb{N},$ and let $\mathcal{H}$ be a subspace of $\mathbb{R}^n$ such that \(\mathcal{H} \neq \{\mathbf{0}_n\}\). If the following two assumptions are satisfied:
A1. Vectors $\mathbf{a}_1, \ldots, \mathbf{a}_k$ form a basis for $\mathcal{H}$, (notice that there are $k$ vectors in this basis),
A2. Vectors $\mathbf{b}_1, \ldots, \mathbf{b}_m$ form a basis for $\mathcal{H}$, (notice that there are $m$ vectors in this basis),
then the following claim is true:
C. $m=k$.
Background Knowledge is as follows.
BK0. The definition of a basis for a subspace, the definition of a column space.
BK1. Theorem 1.
Proof. Introduce an \(n\times k\) matrix \(A\) whose columns are $\mathbf{a}_1, \ldots, \mathbf{a}_k$ and \(n\times m\) matrix \(B\) whose columns are $\mathbf{b}_1, \ldots, \mathbf{b}_m$. That is \[ A = \bigl[ \mathbf{a}_1 \ \cdots \ \mathbf{a}_k \bigr], \qquad B = \bigl[ \mathbf{b}_1 \ \cdots \ \mathbf{b}_m \bigr]. \]
Step 1. By background knowledge BK0 we have that \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\mathcal{H} = \operatorname{Col}(A) = \operatorname{Col}(B)}, \end{equation*} \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\text{the columns of} \ \ A \ \ \text{are linearly independent}}, \end{equation*} and \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\text{the columns of} \ \ B \ \ \text{are linearly independent}}. \end{equation*}
Step 2. In this step we apply BK1, that is Theorem 1 to the matrix \(A\) in the role of \(F\) and \(B\) in the role of \(G\). Since by Step 1 we have \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\operatorname{Col}(A) = \operatorname{Col}(B)} \quad \text{and} \quad \bbox[lightgreen, 6px, border:3px solid green]{\text{the columns of} \ \ A \ \ \text{are linearly independent}}, \end{equation*} we deduce \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{k \leq m}. \end{equation*}
Step 3. In this step we apply BK1, that is Theorem 1 to the matrix \(B\) in the role of \(F\) and \(A\) in the role of \(G\). Since by Step 1 we have \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{\operatorname{Col}(B) = \operatorname{Col}(A)} \quad \text{and} \quad \bbox[lightgreen, 6px, border:3px solid green]{\text{the columns of} \ \ B \ \ \text{are linearly independent}}, \end{equation*} we deduce \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{m \leq k}. \end{equation*}
Step 4. In Step 2 and Step 3 we proved \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{k \leq m} \quad \text{and} \quad \bbox[lightgreen, 6px, border:3px solid green]{m \leq k}. \end{equation*} Consequently \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{k = m}. \end{equation*}
This completes the proof.
- Let $m, n \in \mathbb{N}.$ Let $A$ be an $n\!\times\!m$ matrix. The matrix $A$ has $n$ rows and $m$ columns. The columns of $A$ are vectors in $\mathbb{R}^n.$ The transpose of $A$, denoted by \(A^\top\), is an \(m\!\times\!n\) matrix. The matrix \(A^\top\) has $m$ rows and $n$ columns. The columns of \(A^\top\) are vectors in \(\mathbb{R}^m\). The columns of $A^\top$ have the identical entries as the rows of \(A\), just instead of being in rows they are written as columns. Two fundamental subspaces associated with the matrix $A$ are \begin{alignat*}{2} \operatorname{Col}(A) & = \operatorname{Row}(A^\top) \quad & & \left\{ \begin{array}{l} \text{this space is the span of the columns of} \ \ A; \\ \text{since each column of $A$ is a vector in} \ \mathbb{R}^n, \\ \text{this space is a subspace of} \ \ \mathbb{R}^n \end{array} \right. \\[10pt] \operatorname{Row}(A) &= \operatorname{Col}(A^\top) \quad & & \left\{ \begin{array}{l} \text{this space is the span of the columns of} \ A^\top; \\ \text{since each column of $A^\top$ is a vector in} \ \mathbb{R}^m, \\ \text{this space is a subspace of} \ \ \mathbb{R}^m \end{array} \right. \\[10pt] \operatorname{Nul}(A) & = \bigl\{ \mathbf{x} \in \mathbb{R}^m \, : \, & & A\mathbf{x} = \mathbf{0}_n \bigr\} \quad \text{this space is a subspace of} \ \ \mathbb{R}^m, \\[10pt] \operatorname{Nul}(A^\top) & = \bigl\{ \mathbf{y} \in \mathbb{R}^n \, : \, & & A^\top\mathbf{y} = \mathbf{0}_m \bigr\} \quad \text{this space is a subspace of} \ \ \mathbb{R}^n \end{alignat*} Thus \begin{equation*} \bbox[lightgreen, 6px, border:3px solid green]{ \begin{array}{cll} \operatorname{Row}(A) = \operatorname{Col}(A^\top) \quad & \text{and} \quad \operatorname{Nul}(A) \quad & \text{are subspaces of} \quad \mathbb{R}^m\\[3pt] \operatorname{Col}(A) = \operatorname{Row}(A^\top) \quad & \text{and} \quad \operatorname{Nul}(A^\top) \quad & \text{are subspaces of} \quad \mathbb{R}^n \end{array} } \end{equation*}
-
The concept of column space of a matrix is introduced inn Section 2.8. The concept of row space of a matrix is introduced in Section 4.6 in subsection entitled The Row Space. You can learn how to find a basis of the row space in An Ode to Reduced Row Echelon Form.
The rank theorem is covered both in Section 2.9 in subsection Dimension of a Subspace and in subsection The Rank Theorem in Section 4.6. Read both.
Suggested problems related to $\operatorname{Col}(A)$ and $\operatorname{Nul}(A)$ of a given matrix $A$ from Section 4.5 are: 3, 6, 12, 13, 15, 18.
More problems about $\operatorname{Col}(A)$, $\operatorname{Row}(A)$ and $\operatorname{Nul}(A)$ of a given matrix $A$ are in Section 4.6: 3, 4, 5, 6, 7, 8, 9, 11, 13, 15, 17, 18, 27, 28, 29.
Suggested problems for Section 2.9: 1, 2, 3, 5, 6, 7, 9, 11, 12, 14, 15, 19, 20, 21, 23, 24, and in particular 27 and 28.
-
All relevant properties of a column space its basis and dimension, of a row space, its basis and dimension, and of a null space its basis and dimension, you can find in my
- Below I show two examples of coordinate systems.
-
In the picture below we show a dark green basis in $\mathbb{R}^2$ and the corresponding coordinate system.
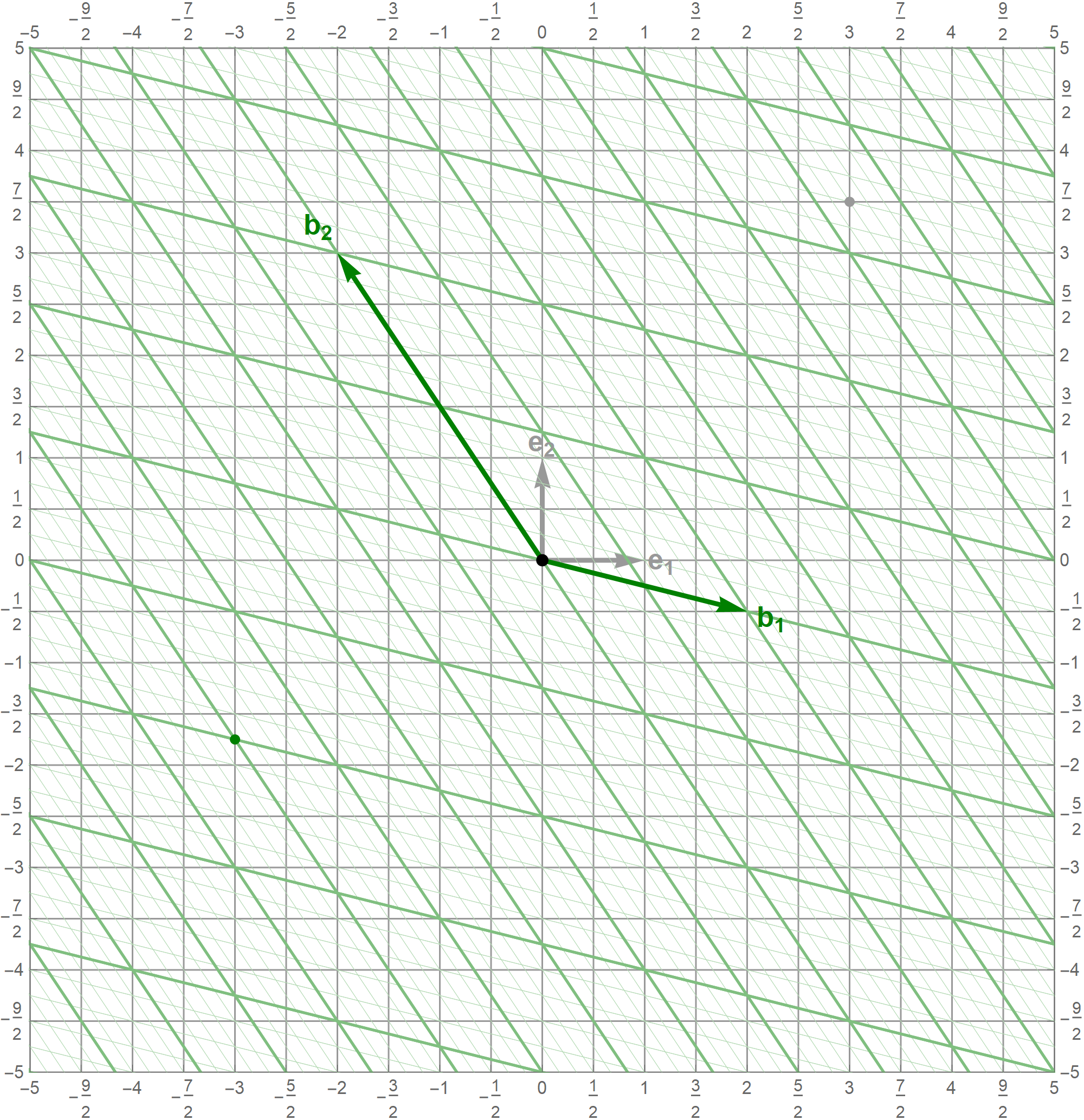
-
In the picture below we show two dark green vectors in $\mathbb{R}^3$. These vectors span a two-dimensional subspace of $\mathbb{R}^3.$ These two dark green vectors form a basis of this subspace. In the picture below I show the corresponding coordinate system.
 In the picture above, I used the vectors
\[
\left[\begin{array}{c} 1 \\ -3 \\ 1 \end{array}\right], \qquad
\left[\begin{array}{c} -4 \\ 1 \\ 2 \end{array}\right].
\]
In the picture above, I used the vectors
\[
\left[\begin{array}{c} 1 \\ -3 \\ 1 \end{array}\right], \qquad
\left[\begin{array}{c} -4 \\ 1 \\ 2 \end{array}\right].
\]
-
Today we started Section 2.8 Subspaces of $\mathbb{R}^n.$ Suggested problems for Section 2.8: 5, 6, 8, 9, 10, 11-20, 24, 25, 26, 30, 31-36.
Pay attention to the definitions of
- subspace of \(\mathbb{R}^n\), page 148.
- column space of a matrix, page 149.
- row space of a matrix, page 233 in Section 4.6.
- basis for a subspace \(\mathcal{H}\) of \(\mathbb{R}^n\), page 150.
-
Let me summarize the concepts of column space and row space.
Let $m, n \in \mathbb{N}.$ Let $A$ be an $n\!\times\!m$ matrix. The matrix $A$ has $n$ rows and $m$ columns. The columns of $A$ are vectors in $\mathbb{R}^n.$ The transpose of $A$, denoted by \(A^\top\), is an \(m\!\times\!n\) matrix. The matrix \(A^\top\) has $m$ rows and $n$ columns. The columns of \(A^\top\) are vectors in \(\mathbb{R}^m\). The columns of $A^\top$ have the identical entries as the rows of \(A\), just instead of being in rows they are written as columns. Two fundamental subspaces associated with the matrix $A$ are \begin{alignat*}{2} \operatorname{Col}(A) & = \operatorname{Row}(A^\top) \quad & & \left\{ \begin{array}{l} \text{this space is the span of the columns of} \ \ A \\ \text{this space is a subspace of} \ \ \mathbb{R}^n, \\ \text{since each column of $A$ is a vector in} \ \mathbb{R}^n \end{array} \right. \\ \operatorname{Row}(A) &= \operatorname{Col}(A^\top) \quad & & \left\{ \begin{array}{l} \text{this space is the span of the columns of} \ A^\top \\ \text{this space is a subspace of} \ \ \mathbb{R}^m, \\ \text{since each column of $A^\top$ is a vector in} \ \mathbb{R}^m \end{array} \right. \end{alignat*}
-
Important theorems related to these concepts are:
Theorem 13.(page 152) Let $m$ and $n$ be positive integers, and let $A$ be an $n\!\times\!m$ matrix. The column space of the matrix \(A\), denoted by \(\operatorname{Col}(A)\), is a subspace of \(\mathbb{R}^n\). The pivot columns of the matrix \(A\) form a basis for the column space of \(A\).
Theorem 13.(page 233) Let $m$ and $n$ be positive integers, and let $A$ be an $n\!\times\!m$ matrix. The row spaces of the matrix \(A\), denoted by \(\operatorname{Row}(A)\), is a subspace of \(\mathbb{R}^m\). The row spaces of the matrix \(A\) and the row space of its Reduced Row Echelon Form are the same. The nonzero rows of the Reduced Row Echelon Form of \(A\) form a basis for the row space of \(A\).
-
You will understand the above theorems better, after reading my writing about Reduced Row Echelon Form:
- Today we finished Section 2.2: The inverse of a matrix; suggested problems are: 1, 4, 5, 7, 12, 13, 21, 22, 23, 24, 28, 32, 33, 34, 38. In all bold face problems the textbook asks you to "explain why" something is true. In the text of the book and in class we offer proofs. Please try to organize your solutions as proofs, not explanations. State clearly what is known from theorems in the book and use logical reasoning to deduce what the problem claims.
-
The most interesting implication in the Invertibel Matrix Theorem is (b)$\Rightarrow$(a). In that implication we need to prove:
Let $n\in\mathbb{N}$ and let $A$ be an $n\!\times\!n$ matrix. If the RREF of $A$ is $I_n$, then $A$ is invertible.
I posted a proof of this implication on Saturday. I post it again because of its importance and since I think that the proof here is better than the proof given in the textbook; see Theorem 7.
The proof presented below uses only two facts: elementary matrices are invertible and matrix multiplication is associative. I also like that the proof below proves the invertibility by using the definition of invertibility. The proof below was suggested to me by a student during Fall Quarter 2021. Unfortunately I forgot who it was. In any case, please think on your own about each proof. You can come up with new proofs.
In the proof below we need to prove that a matrix is invertible. For that it is useful to recall the definition of invertibility.
Definition. Let $n\in \mathbb{N}$ and let $I_n$ be the $n\!\times\!n$ identity matrix. An $n\!\times\!n$ matrix $A$ is said to be invertible if there exists an $n\!\times\!n$ matrix $C$ such that \[ CA = I_n \quad \text{and} \quad AC = I_n. \]Proof.- Step 1. Let $n\in\mathbb{N}$ and let $A$ be an $n\!\times\!n$ matrix. Assume that the Reduced Row Echelon Form of $A$ is $I_n.$ This means that there exists a positive integer $p$ and $p$ row operators that row reduce $A$ to $I_n.$ Since each row operation can be represented by matrix multiplication from the left by an elementary matrix, there exist elementary matrices $E_1, E_2,\ldots, E_p$ such that the row reduction of the matrix $A$ looks like \[ A \sim E_1 A \sim E_2(E_1 A) \sim \cdots \sim E_p(E_{p-1} \cdots E_1A) = I_n. \] Since matrix multiplication is associative we have \[ (E_p \cdots E_1) A = I_n. \] Thus, we can set $C = E_p \cdots E_1$ in the definition of an invertible matrix and we have $CA = I_n.$
- Step 2. Since the matrices $E_1, E_2, \ldots, E_{p-1}, E_p$ are elementary matrices, they are invertible. Therefore we have the matrices $(E_1)^{-1}, (E_2)^{-1}, \ldots, (E_{p-1})^{-1}, (E_p)^{-1}.$ Recall the equality \[ (E_p \cdots E_1) A = I_n. \] from Step 1. Now we multiply the preceding equality from the left by $(E_p)^{-1}$ to get \[ (E_p)^{-1}(E_p E_{p-1} \cdots E_2 E_1) A = (E_p)^{-1} I_n. \] Since matrix multiplication is associative we get \[ (E_{p-1} \cdots E_2 E_1) A = (E_p)^{-1}. \] Next we keep multiplying the preceding equality consecutively by $(E_{p-1})^{-1}, \ldots, (E_2)^{-1}$ to get \[ E_1 A =(E_2)^{-1} \cdots (E_{p-1})^{-1} (E_p)^{-1}. \] Finally we multiply the preceding equality by $(E_1)^{-1}$ to get \[ A =(E_1)^{-1} (E_2)^{-1} \cdots (E_{p-1})^{-1} (E_p)^{-1}. \] Now we multiply the preceding equality from the right with $p$ matrices $E_p, E_{p-1},\ldots, E_2, E_1$ to get \[ A (E_p E_{p-1} \cdots E_2 E_1) = I_n. \] Recall that in Step 1 we set $C = E_p E_{p-1} \cdots E_2 E_1.$ Thus, the last displayed equality reads $AC = I_n.$ To summarize, we have proved that the following two matrix equalities hold \[ C A = I_n \quad \text{and} \quad A C = I_n. \] Therefore, by the definition of invertible matrix $A$ is invertible.
- QED.
- To fully understand the proof above, it is a good idea to work out a complete example.
-
Consider the following problem:
- Determine whether the matrix $A = \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 2 & 1 \\ 2 & 2 & 1 \end{array}\right]$ is invertible.
- If $A$ is invertible find its inverse $A^{-1}$.
- The first step is to row reduce $A$ to RREF. \begin{align*} \left[\!\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 2 & 1 \\ 2 & 2 & 1 \end{array}\right] & \sim \left[\!\begin{array}{rrr} 1 & 1 & 0 \\ -1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] \\ \end{align*}
-
To understand the proof of the implication
-
Each step in a row reduction can be achieved by multiplication by an elementary matrix.
Step the row operation the elementary matrix the inverse of elementary matrix 1st The second row is replaced by the the sum of the second row and the third row multiplied by (-1) $E_1 = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & -1 \\ 0 & 0 & 1 \end{array}\right]$ $E_1^{-1} = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 1 \end{array}\right]$ 2nd The second row scaled (multiplied) by (-1) $E_2 = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & -1 & 0 \\ 0 & 0 & 1 \end{array}\right]$ $E_2^{-1} = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & -1 & 0 \\ 0 & 0 & 1 \end{array}\right]$ 3rd The third row is replaced by the the sum of the third row and the first row multiplied by $(-2)$ $E_3 = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ -2 & 0 & 1 \end{array}\right]$ $E_3^{-1} = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 2 & 0 & 1 \end{array}\right]$ 4th The first row is replaced by the sum of the first row and the second row multiplied by (-1) $E_4 = \left[\!\begin{array}{rrr} 1 & -1 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right]$ $E_4^{-1} = \left[\!\begin{array}{rrr} 1 & 1 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right]$ 5th The first row and the second row are interchanged $E_5 = \left[\!\begin{array}{rrr} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right]$ $E_5^{-1} = \left[\!\begin{array}{rrr} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right]$ - Next we use the elementary matrices $E_1,$ $E_2,$ $E_3,$ $E_4$ and $E_5$ to reconstruct the row reduction above: \begin{align*} E_1 A & = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & -1 \\ 0 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 2 & 1 \\ 2 & 2 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 1 & 0 \\ -1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right], \\ E_2 (E_1 A) & = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & -1 & 0 \\ 0 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 1 & 0 \\ -1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right], \\ E_3 (E_2 E_1 A) & =\left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ -2 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right], \\ E_4 (E_3 E_2 E_1 A) & = \left[\!\begin{array}{rrr} 1 & -1 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right] = \left[\!\begin{array}{rrr} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right], \\ E_5 (E_4 E_3 E_2 E_1 A) & = \left[\!\begin{array}{rrr} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right] = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right]. \end{align*}
- Since matrix multiplication is associative, we have \[ (E_5 E_4 E_3 E_2 E_1) A = I_3. \] This equality is important, since I can set \(C= E_5 E_4 E_3 E_2 E_1\) and I have proved the first property \(CA = I_3\) in the definition of an invertible matrix.
- To prove the second property of \(C\), that is \(AC = I_3\), I start from already proven equality \[ (E_5 E_4 E_3 E_2 E_1) A = I_3 \] and multiply both sides on the left, first by $E_5^{-1}$, to get \[ E_4 E_3 E_2 E_1 A = E_5^{-1}, \] then by $E_4^{-1}$, to get \[ E_3 E_2 E_1 A = E_5^{-1}E_4^{-1}, \] then by $E_3^{-1}$, \[ E_2 E_1 A = E_5^{-1}E_4^{-1}E_3^{-1}, \] then by $E_2^{-1}$, to get \[ E_1 A = E_5^{-1}E_4^{-1}E_3^{-1}E_2^{-1}, \] then by $E_1^{-1}$, to finally we get \[ A = E_1^{-1} E_2^{-1} E_3^{-1} E_4^{-1} E_5^{-1}. \] This is an important equlity since it tells us that \(A\) can be written as a product of elementary matrices.
- To prove that \(AC = I_3\), we start with \[ A = E_1^{-1} E_2^{-1} E_3^{-1} E_4^{-1} E_5^{-1}, \] and multiply from the right by \(E_5\), then by \(E_4\), then by \(E_3\), then by \(E_2\), then by \(E_1\), to get \[ A (E_5 E_4 E_3 E_2 E_1) = I_3. \] Now recall that \(C= E_5 E_4 E_3 E_2 E_1\), and we have proved that \(AC= I_3\).
- Let me summarize: the row reduction of \(A\) produced five elementary matrices, which we used to define \(C\). From the row reduction algorithm, we concluded that \(CA = I_3\). Then, using matrix algebra and the facts that elementary matrices are invertible and matrix multiplication is associative, we proved that \(AC = I_3\). By the definition of an invertible matrix, we concluded that \(A\) is invertible.
- I hope this specific example helps clarify the abstract proof given above and in Saturday’s post.
-
In the preceding items we establishe the equality: \[ A = E_1^{-1} E_2^{-1} E_3^{-1} E_4^{-1} E_5^{-1}. \] This is interesting, we represented \(A\) as a product of elementary matrices.
Let us verify this claim: \begin{align*} E_5^{-1} & = \left[\!\begin{array}{rrr} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right], \\ E_4^{-1} E_5^{-1} & = \left[\!\begin{array}{rrr} 1 & 1 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right] = \left[\!\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right], \\ E_3^{-1} \bigl(E_4^{-1} E_5^{-1}\bigr) & =\left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 2 & 0 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right], \\ E_2^{-1} \bigl(E_3^{-1} E_4^{-1} E_5^{-1}\bigr) & = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & -1 & 0 \\ 0 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 1 & 0 \\ -1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right], \\ E_1^{-1} \bigl(E_2^{-1} E_3^{-1} E_4^{-1} E_5^{-1}\bigr) & = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 1 & 0 \\ -1 & 0 & 0 \\ 2 & 2 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 2 & 1 \\ 2 & 2 & 1 \end{array}\right] \end{align*} Thus, we confirmed that \[ A = \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 2 & 1 \\ 2 & 2 & 1 \end{array}\right] = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & -1 & 0 \\ 0 & 0 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 2 & 0 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 1 & 1 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 0 & 1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \end{array}\right] \] - What we presented above is of theoretical importance. But, just to calculate the inverse of \(A\) we use the algorithm presented in the next item.
- To calculate the inverse $A^{-1}$ we row reduce the $3\times 6$ matrix $[A | I_3]$: \begin{align*} \left[\!\begin{array}{rrr|rrr} 1 & 1 & 0 & 1 & 0 & 0 \\ 1 & 2 & 1 & 0 & 1 & 0 \\ 2 & 2 & 1 & 0 & 0 & 1 \end{array}\right] & \sim \left[\!\begin{array}{rrr|rrr} 1 & 1 & 0 & 1 & 0 & 0 \\ -1 & 0 & 0 & 0 & 1 & -1 \\ 2 & 2 & 1 & 0 & 0 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 1 & 1 & 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 & -1 & 1 \\ 2 & 2 & 1 & 0 & 0 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 1 & 1 & 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 & -1 & 1 \\ 0 & 0 & 1 & -2 & 0 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 0 & 1 & 0 & 1 & 1 & -1 \\ 1 & 0 & 0 & 0 & -1 & 1 \\ 0 & 0 & 1 & -2 & 0 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 1 & 0 & 0 & 0 & -1 & 1 \\ 0 & 1 & 0 & 1 & 1 & -1 \\ 0 & 0 & 1 & -2 & 0 & 1 \end{array}\right] \\ \end{align*}
- We pause here to celebrate the fact that we found the inverse of the matrix $A.$ Let us verify this claim: \[ \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 2 & 1 \\ 2 & 2 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 0 & -1 & 1 \\ 1 & 1 & -1 \\ -2 & 0 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] \]
-
After reading this post you should be able to solve a problem stated as follows:
Consider the matrix $M = \left[\begin{array}{rrr} 3 & 3 & 2 \\ 3 & 2 & 1 \\ 2 & 1 & 0 \end{array}\right]$.
- Determine whether it is possible to write the matrix $M$ as a product of elementary matrices.
- If you claim that it is possible to write $M$ as a product of elementary matrices, then find elementary matrices whose product is $M$. If you claim that it is not possible to write $M$ as a product of elementary matrices, justify your answer.
- The matrix $A = \left[\begin{array}{rrr} 1 & 1 & 0 \\ 1 & 2 & 1 \\ 2 & 2 & 1 \end{array}\right]$ whose inverse we found above and the matrix $M=\left[\begin{array}{rrr} 3 & 3 & 2 \\ 3 & 2 & 1 \\ 2 & 1 & 0 \end{array}\right]$ which I assigned in the problem above are very special matrices. These matrices have integer entries and all the entries of their inverses are also integers. In exercises it is often convenient to have such matrices: matrices with integer entries whose inverse is also a matrix with integer entries. Such matrices are called unimodular matrices. I was surprised that there are a lot of such matrices. Here is a pdf file with all unimodular matrices with entries $-1,0,1,2,3$ whose inverses have entries among the ten digits and their opposites. I have omitted the matrices with 3 or more zeros. This pdf file is huge, 3119 pages with over 80000 matrices. If you ever need a unimodular matrix I hope you find it here. You can use these matrices to practice row reduction since for every matrix listed in this file I list its inverse.
- It is a good idea to review Problems 23, 24, 25 from Section 2.1 before reading this section. Suggested problems for Section 2.3: 1, 3, 5, 8, 11, 12, 13, 15, 16, 17, 18, 19, 20, 21, 26, 27, 33.
-
Statements in Problems 23, 24, 25 in Section 2.1, Theorems in Section 2.2 and all statements in the Invertible Matrix Theorem can be expressed as implications.
-
In general, whenever you try to prove something, you should formulate the statement of the problem as a clear implication. That is, as a statement of the form
-
When talking abstractly about logical statements we denote the green space by a letter, say $p$ and the red space by another letter, say $q$. Then we write implication as
If $p$, then $q$.
-
The logical symbol for the implication is $\Rightarrow$ as in
$p \Rightarrow q$
-
The negation of the implication $p \Rightarrow q$isThe negation
-
With any implication you should be aware of its contrapositive. The contrapositive of the implication $p \Rightarrow q$ involves the negations of $q$ and $p$. Mathematical notation of the negation of $q$ is $\neg q$ and the negation of $p$ is $\neg p$. The contrapositive of the implication $p \Rightarrow q$ is
The contrapositive$\neg q \Rightarrow \neg p$
- Recall that the converse of the implication $p \Rightarrow q$ is the implication $q \Rightarrow p$. Also recall that the converse can be wrong when the original proposition is true.
-
Almost all mathematical statements can be stated as implications. A symbolic way to represent an implication is $p \Rightarrow q$, where $p$ and $q$ are mathematical statements. There are many ways to say $p \Rightarrow q$ in English.
- If $p$, then $q$.
- $q$ if $p$.
- $p$ is sufficient for $q$.
- $q$ is necessary for $p$.
- A sufficient condition for $q$ is $p$.
- A necessary condition for $p$ is $q$.
- $p$ implies $q$.
- $p$ only if $q$.
- $q$ whenever $p$.
- $q$ follows from $p$.
- Recall that the converse of the implication $p \Rightarrow q$ is the implication $q \Rightarrow p$. Also recall that the converse can be false when the original implication is true, like in my favorite example "If it rains, then the Red Square is wet." Like with all things in life, this validity of this statement is debatable (but I would argue that it is expensive to make this statement false). However, the converse is definitely not true. It is easy to make the converse false. However, I do not recommend that we do that without the approval of the Red Square authorities.
- Logic is essential for any mathematics class. I my essay Brief Review of Mathematical Logic, I introduce the basics of Mathematical Logic.
-
In general, whenever you try to prove something, you should formulate the statement of the problem as a clear implication. That is, as a statement of the form
-
All this logic introduction is for the better understanding of the Invertible Matrix Theorem. For easier comprehension of the
twelve parts of the Invertible Matrix Theorem I created this picture
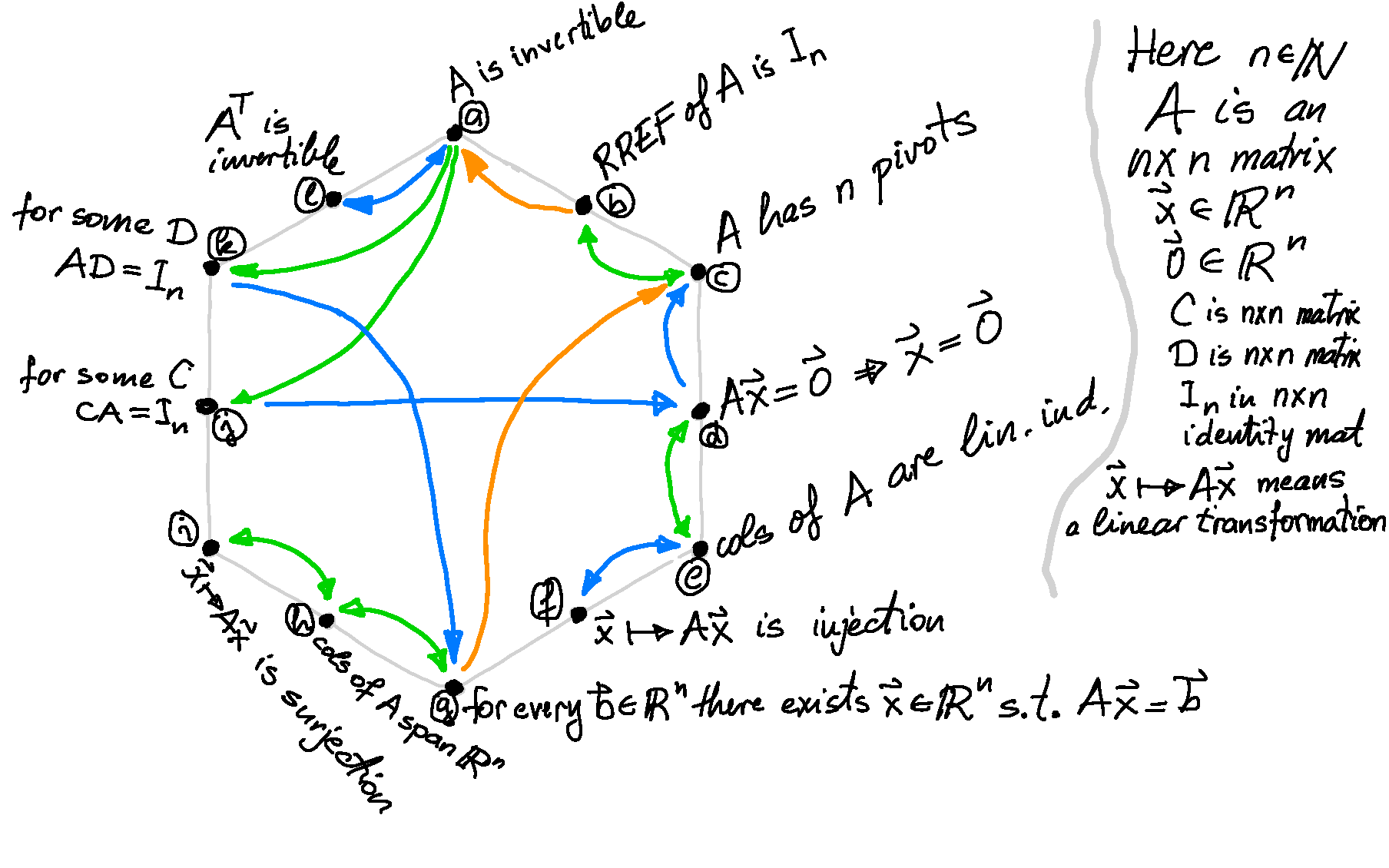 You should first understand the proofs of the implications corresponding to the green arrows in the picture above. Sometimes the proofs of the green implications are just restatements of the definitions. The next step is understanding the implications corresponding to the blue arrows. Finally, below I present the proofs of the implications corresponding to the orange arrows. Both of these proofs involve the fact that the process of the row reduction to the RREF can be represented as a product of a sequence of elementary matrices.
You should first understand the proofs of the implications corresponding to the green arrows in the picture above. Sometimes the proofs of the green implications are just restatements of the definitions. The next step is understanding the implications corresponding to the blue arrows. Finally, below I present the proofs of the implications corresponding to the orange arrows. Both of these proofs involve the fact that the process of the row reduction to the RREF can be represented as a product of a sequence of elementary matrices.
-
Now proof of the implication (g)$\Rightarrow$(c). That is we need to prove:
- Step 1. Assume that $A$ has $m$ pivot columns and $m \lt n.$ Then there are $m$ pivot positions in the RREF of $A.$ Since each pivot position occupies its own row, there are $m$ rows in the RREF of $A$ which contain pivot positions. The rows which contain the pivot positions are at the top of the RREF of $A.$ The remaining rows at the bottom of the RREF of $A$ are zero rows. Since $m \lt n$, the bottom row of the RREF of $A$ is a zero row.
- Step 2. Let $q \in\mathbb{N}.$ Assume that the RREF of $A$ has been obtained by performing $q$ row operations. Denote by $E_1,\ldots,E_q$ the corresponding elementary matrices. Then The matrix $E_q \cdots E_1 A$ is the RREF of $A$.
- Step 3. From Step 2 and Step 1 we conclude that The bottom row of the matrix $E_q \cdots E_1 A$ is the zero row. Therefore, The matrix equation $(E_q \cdots E_1 A) \mathbf{x} = \mathbf{e}_{n,n}$ is not consistent.
- Step 4. We know that changing a system of linear equations by performing row operations does not change the solution set of linear system. Therefore, the matrix equation $(E_q \cdots E_1 A) \mathbf{x} = \mathbf{e}_{n,n}$ and the matrix equation $ A \mathbf{x} = (E_1)^{-1} \cdots (E_q)^{-1}\mathbf{e}_{n,n}$ have the same solution set.
- Step 5. From Step 3 and Step 4 we deduce that the matrix equation $A \mathbf{x} = (E_1)^{-1} \cdots (E_q)^{-1}\mathbf{e}_{n,n}$ is not consistent.
- Step 6. From Step 5 we deduce that there exists $\mathbf{b} = (E_1)^{-1} \cdots (E_q)^{-1}\mathbf{e}_{n,n} \in \mathbb{R}^n$ such that the matrix equation $A \mathbf{x} = \mathbf{b}$ is not consistent.
- QED.
-
Next, I present a proof of the implication (b)$\Rightarrow$(a). That is we need to prove:
Let $n\in\mathbb{N}$ and let $A$ be an $n\!\times\!n$ matrix. If the RREF of $A$ is $I_n$, then $A$ is invertible.
This implication is proved in Theorem 7 in the textbook, but I prefer to give another proof which uses only the facts that elementary matrices are invertible and that matrix multiplication is associative. I also like that the proof below proves the invertibility by using the definition of invertibility. The proof below was suggested to me by a student during Fall Quarter 2021. Unfortunately I forgot who it was. In any case, please think on your own about each proof. You can come up with new proofs.
In the proof below we need to prove that a matrix is invertible. For that it is useful to recall the definition of invertibility.
Definition. Let $n\in \mathbb{N}$ and let $I_n$ be the $n\!\times\!n$ identity matrix. An $n\!\times\!n$ matrix $A$ is said to be invertible if there exists an $n\!\times\!n$ matrix $C$ such that \[ CA = I_n \quad \text{and} \quad AC = I_n. \]Proof.- Step 1. Let $n\in\mathbb{N}$ and let $A$ be an $n\!\times\!n$ matrix. Assume that the Reduced Row Echelon Form of $A$ is $I_n.$ This means that there exists a positive integer $p$ and $p$ row operators that row reduce $A$ to $I_n.$ Since each row operation can be represented by matrix multiplication from the left by an elementary matrix, there exist elementary matrices $E_1, E_2,\ldots, E_p$ such that the row reduction of the matrix $A$ looks like \[ A \sim E_1 A \sim E_2(E_1 A) \sim \cdots \sim E_p(E_{p-1} \cdots E_1A) = I_n. \] Since matrix multiplication is associative we have \[ (E_p \cdots E_1) A = I_n. \] Thus, we can set $C = E_p \cdots E_1$ in the definition of an invertible matrix and we have $CA = I_n.$
- Step 2. Since the matrices $E_1, E_2, \ldots, E_{p-1}, E_p$ are elementary matrices, they are invertible. Therefore we have the matrices $(E_1)^{-1}, (E_2)^{-1}, \ldots, (E_{p-1})^{-1}, (E_p)^{-1}.$ Recall the equality \[ (E_p \cdots E_1) A = I_n. \] from Step 1. Now we multiply the preceding equality from the left by $(E_p)^{-1}$ to get \[ (E_p)^{-1}(E_p E_{p-1} \cdots E_2 E_1) A = (E_p)^{-1} I_n. \] Since matrix multiplication is associative we get \[ (E_{p-1} \cdots E_2 E_1) A = (E_p)^{-1}. \] Next we keep multiplying the preceding equality consecutively by $(E_{p-1})^{-1}, \ldots, (E_2)^{-1}$ to get \[ E_1 A =(E_2)^{-1} \cdots (E_{p-1})^{-1} (E_p)^{-1}. \] Finally we multiply the preceding equality by $(E_1)^{-1}$ to get \[ A =(E_1)^{-1} (E_2)^{-1} \cdots (E_{p-1})^{-1} (E_p)^{-1}. \] Now we multiply the preceding equality from the right with $p$ matrices $E_p, E_{p-1},\ldots, E_2, E_1$ to get \[ A (E_p E_{p-1} \cdots E_2 E_1) = I_n. \] Recall that in Step 1 we set $C = E_p E_{p-1} \cdots E_2 E_1.$ Thus, the last displayed equality reads $AC = I_n.$ To summarize, we have proved that the following two matrix equalities hold \[ C A = I_n \quad \text{and} \quad A C = I_n. \] Therefore, by the definition of invertible matrix $A$ is invertible.
- QED.
- I think that the best way to prove the implication (d)$\Rightarrow$(c) is to prove its contrapositive. You can try this proof on your own. It is a blue proof.
- Today we did preliminaries for Section 2.3 Characterizations of invertible matrices. It is a good idea to review Exercises 23, 24, 25 from Section 2.1 before reading this section. Suggested problems for Section 2.3: 1, 3, 5, 8, 11, 12, 13, 15, 16, 17, 18, 19, 20, 21, 26, 27, 33.
- I will post the about Invertible Matrix Theorem tomorrow. Below I post about row reduction and its connection with elementary matrices.
- Recall the row reduction that we posted yesterday to find the inverse of $\displaystyle \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ -1 & 1 & 1 \end{array}\right]$: \begin{align*} \left[\!\begin{array}{rrr|rrr} 1 & 0 & -1 & 1 & 0 & 0 \\ 0 & 2 & 1 & 0 & 1 & 0 \\ -1 & 1 & 1 & 0 & 0 & 1 \end{array}\right] & \sim \left[\!\begin{array}{rrr|rrr} 1 & 0 & -1 & 1 & 0 & 0 \\ 0 & 2 & 1 & 0 & 1 & 0 \\ 0 & 1 & 0 & 1 & 0 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 1 & 0 & -1 & 1 & 0 & 0 \\ 0 & 1 & 0 & 1 & 0 & 1 \\ 0 & 2 & 1 & 0 & 1 & 0 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 1 & 0 & -1 & 1 & 0 & 0 \\ 0 & 1 & 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & -2 & 1 & -2 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 1 & 0 & 0 & -1 & 1 & -2 \\ 0 & 1 & 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & -2 & 1 & -2 \end{array}\right] \\ \end{align*}
-
Now recall that each step in a row reduction can be achieved by multiplication by an elementary matrix.
Step the row operation the elementary matrix the inverse of elementary matrix 1st The third row is replaced by the the sum of the first row and the third row $E_1 = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 1 & 0 & 1 \end{array}\right]$ $E_1^{-1} = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ -1 & 0 & 1 \end{array}\right]$ 2nd The third row and the second row are interchanged $E_2 = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & 1 & 0 \end{array}\right]$ $E_2^{-1} = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & 1 & 0 \end{array}\right]$ 3rd The third row is replaced by the the sum of the third row and the second row multiplied by $(-2)$ $E_3 = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & -2 & 1 \end{array}\right]$ $E_3^{-1} = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 2 & 1 \end{array}\right]$ 4th The first row is replaced by the the sum of the first row and the third row $E_4 = \left[\!\begin{array}{rrr} 1 & 0 & 1 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right]$ $E_4^{-1} = \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right]$ - Next we use the elementary matrices $E_1$, $E_2$, $E_3$ and $E_4$ to reconstruct the row reduction above: \begin{align*} E_1 A & = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 1 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ -1 & 1 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ 0 & 1 & 0 \end{array}\right], \\ E_2 (E_1 A) & = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & 1 & 0 \end{array}\right] \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ 0 & 1 & 0 \end{array}\right] = \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0\\ 0 & 2 & 1 \end{array}\right], \\ E_3 (E_2 E_1 A) & =\left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & -2 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0\\ 0 & 2 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0\\ 0 & 0 & 1 \end{array}\right], \\ E_4 (E_3 E_2 E_1 A) & = \left[\!\begin{array}{rrr} 1 & 0 & 1 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0\\ 0 & 0 & 1 \end{array}\right] = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right]. \end{align*}
- Since matrix multiplication is associative, we have \[ (E_4 E_3 E_2 E_1) A = I_3. \]
- The reason that I wrote all the above detailed steps is to show that we can write $A$ as a product of elementary matrices. Recall the preceding equality: \[ (E_4 E_3 E_2 E_1) A = I_3. \] Multiplying the last equality consecutively by $E_4^{-1}$, $E_3^{-1}$, $E_2^{-1}$, $E_1^{-1}$ we get \[ A = E_1^{-1} E_2^{-1} E_3^{-1} E_4^{-1}. \] Let us verify this claim: \begin{align*} E_4^{-1}& = \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right], \\ E_3^{-1} E_4^{-1} & = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 2 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] = \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0 \\ 0 & 2 & 1 \end{array}\right], \\ E_2^{-1} \bigl(E_3^{-1} E_4^{-1}\bigr) & =\left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & 1 & 0 \end{array}\right] \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0 \\ 0 & 2 & 1 \end{array}\right] = \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ 0 & 1 & 0 \end{array}\right], \\ E_1^{-1} \bigl(E_2^{-1} E_3^{-1} E_4^{-1}\bigr) & = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ -1 & 0 & 1 \end{array}\right] \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ 0 & 1 & 0 \end{array}\right] = \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ -1 & 1 & 1 \end{array}\right]. \end{align*} Thus, we confirmed that \[ A = \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ -1 & 1 & 1 \end{array}\right] = \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ -1 & 0 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 0 & 1 \\ 0 & 1 & 0 \end{array}\right] \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 2 & 1 \end{array}\right] \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] \]
-
The importance of the preceding item is that we found an expression for the matrix $A$ as a product of elementary matrices. In fact, the reasoning presented above for a specific $3\!\times\!3$ matrix $A$ holds for an arbitrary $n\!\times\!n$ matrix $A$ which can be row reduced to the identity matrix $I_n.$ The above reasoning is used as a model for a proof of the following important implication:
If Reduced Row Echelon Form of $A$ is $I_n$, then $A$ is invertible.
This implication is proved in Theorem 7 in Section 2.2. -
After reading this post you should be able to solve a problem stated as follows:
Consider the matrix $M = \left[\begin{array}{rrr} 3 & 3 & 2 \\ 3 & 2 & 1 \\ 2 & 1 & 0 \end{array}\right]$.
- Determine whether it is possible to write the matrix $M$ as a product of elementary matrices.
- If you claim that it is possible to write $M$ as a product of elementary matrices, then find elementary matrices whose product is $M$. If you claim that it is not possible to write $M$ as a product of elementary matrices, justify your answer.
- Today we started Section 2.2: The inverse of a matrix; suggested problems are: 1, 4, 5, 7, 12, 13, 21, 22, 23, 24, 28, 32, 33, 34, 38. In all bold face problems, the textbook asks you to "explain why" something is true. In the text of the book and in class we offer proofs. Please try to organize your solutions as proofs, not explanations. State clearly what is known from theorems in the book and use logical reasoning to deduce what the problem claims.
-
My approach to the inverse of a $2\!\times\!2$ matrix is a little different from the approach in the textbook. I look at the process of seeking: Given a $2\!\times\!2$ matrix $\displaystyle \left[\!\begin{array}{cc}
a & b \\ c & d \end{array}\!\right]$ we seek another $2\!\times\!2$ matrix $\displaystyle \left[\!\begin{array}{cc}
x & y \\ z & w \end{array}\!\right]$ such that
\[
\left[\!\begin{array}{cc}
a & b \\ c & d \end{array}\!\right]\left[\!\begin{array}{cc}
x & y \\ z & w \end{array}\!\right] = \left[\!\begin{array}{cc}
ax+bz & ay+bw \\ cx+dz & cy+dw \end{array}\!\right] = \left[\!\begin{array}{cc}
1 & 0 \\ 0 & 1 \end{array}\!\right].
\]
At the first step we focus on the zeros and seek $y$ and $w$ such that $ay+bw = 0$, and $x$ and $z$ such that $cx+dz = 0.$
One of the simplest solution of $ay+bw = 0$ is $a(-b)+b\,a = 0$ and one of the simplest solution of $cx+dz = 0$ is $c\,d+d(-b) = 0.$ (This might take some guessing since you have another choice of $c(-d)+d\,b = 0.$) Now try $\displaystyle \left[\!\begin{array}{cc}
d & -b \\ -c & a \end{array}\!\right]$:
\[
\left[\!\begin{array}{cc}
a & b \\ c & d \end{array}\!\right]\left[\!\begin{array}{cc}
d & -b \\ -c & a \end{array}\!\right] = \left[\!\begin{array}{cc}
ad-bc & 0 \\ 0 & c(-b)+da \end{array}\!\right] = (ad-bc) \left[\!\begin{array}{cc}
1 & 0 \\ 0 & 1 \end{array}\!\right].
\]
From the last equality we see that if $ad-bc \neq 0$, then the matrix $\displaystyle \left[\!\begin{array}{cc}
a & b \\ c & d \end{array}\!\right]$ is invertible and its inverse is
\[
\displaystyle \left[\!\begin{array}{cc}
a & b \\ c & d \end{array}\!\right]^{-1} = \frac{1}{ad-bc}\left[\!\begin{array}{cc}
d & -b \\ -c & a \end{array}\!\right].
\]
My point here is that you do not have to memorize the inverse, you can construct it on your own just playing with the equations $ay+bw = 0$ and $cx+dz = 0$ and their simple solutions.
The number $ad-bc$ is called the determinant of the matrix $\displaystyle \left[\!\begin{array}{cc} a & b \\ c & d \end{array}\!\right]$. We write \[ \det \left[\!\begin{array}{cc} a & b \\ c & d \end{array}\!\right] = \left|\!\begin{array}{cc} a & b \\ c & d \end{array}\!\right| = ad-bc. \] - It is important for you to perfect calculation of the inverse of an invertible matrix. For a $2\!\times\!2$ matrix one should use Theorem 4, that is the method explained in the preceding item. For a $3\!\times\!3$ matrix one uses the method presented in Example 7.
-
Consider the following problem:
- Determine whether the matrix $A = \left[\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ -1 & 1 & 1 \end{array}\right]$ is invertible.
- If $A$ is invertible find its inverse $A^{-1}$.
-
To answer the first question in the problem we use the implication
If RREF of $A$ is $I_3$, then $A$ is invertible.
This implication is proved in Theorem 7 in Section 2.2 . This proof is important! - So, we just row reduce $A$ to RREF and that will answer the first question in the exercise: \begin{align*} \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ -1 & 1 & 1 \end{array}\right] & \sim \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 2 & 1 \\ 0 & 1 & 0 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0 \\ 0 & 2 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr} 1 & 0 & -1 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right] \\ \end{align*}
- The row reduction above shows that $A$ is row equivalent to $I_3$. Therefore, by Theorem 7 in Section 2.2 , $A$ is invertible.
- To calculate the inverse $A^{-1}$ we row reduce the $3\times 6$ matrix $[A | I_3]$: \begin{align*} \left[\!\begin{array}{rrr|rrr} 1 & 0 & -1 & 1 & 0 & 0 \\ 0 & 2 & 1 & 0 & 1 & 0 \\ -1 & 1 & 1 & 0 & 0 & 1 \end{array}\right] & \sim \left[\!\begin{array}{rrr|rrr} 1 & 0 & -1 & 1 & 0 & 0 \\ 0 & 2 & 1 & 0 & 1 & 0 \\ 0 & 1 & 0 & 1 & 0 & 1 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 1 & 0 & -1 & 1 & 0 & 0 \\ 0 & 1 & 0 & 1 & 0 & 1 \\ 0 & 2 & 1 & 0 & 1 & 0 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 1 & 0 & -1 & 1 & 0 & 0 \\ 0 & 1 & 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & -2 & 1 & -2 \end{array}\right] \\ & \sim \left[\!\begin{array}{rrr|rrr} 1 & 0 & 0 & -1 & 1 & -2 \\ 0 & 1 & 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & -2 & 1 & -2 \end{array}\right] \\ \end{align*}
- The matrix whose inverse we found above is a very special matrix. It is a matrix whose entries are integers and all the entries of its inverse are integers. In exercises it is often convenient to have such matrices: matrices with integer entries whose inverse is also a matrix with integer entries. Such matrices are called unimodular matrices. I was surprised that there are a lot of such matrices. Here is a pdf file with all unimodular matrices with entries $-1,0,1,2,3$ whose inverses have entries among the ten digits and their opposites. I have omitted the matrices with 3 or more zeros. This pdf file is huge, 3119 pages with over 80000 matrices. If you ever need a unimodular matrix I hope you find it here. You can use these matrices to practice row reduction since for every matrix listed in this file I list its inverse.
- We finished Section 2.1: Matrix Operations and started Section 2.2: The Inverse Of a Matrix
-
Please pay special attention to problems 27, 28. The pattern that you are asked to explore in these problems we encountered in explorations related to Matrix Multiplication. But here that pattern is put in context of vectors from the same space.
- For example if we are given two vectors in \(\mathbb{R}^4\): \[ \mathbf{u} = \left[\! \begin{array}{c} 4 \\ 3\\ 2 \\ 1 \end{array} \!\right], \quad \mathbf{v} = \left[\! \begin{array}{c} a \\ b \\ c \\ d \end{array} \!\right]. \] Notice that these vectors are \(4\times 1\) matrices. Therefore, their transposes are \(1\times 4\) matrices \[ \mathbf{u}^\top = \bigl[\! \begin{array}{cccc} 4 & 3 & 2 & 1 \end{array} \!\bigr], \quad \mathbf{v}^\top = \bigl[\! \begin{array}{c} a & b & c & d \end{array} \!\bigr]. \]
- Now we can calculate \(1\times 1\) matrices, which are just scalars, and which I called "rotated Ts" in my handwritten posts: \begin{align*} \mathbf{u}^\top \mathbf{u} & = \bigl[\! \begin{array}{cccc} 4 & 3 & 2 & 1 \end{array} \!\bigr] \left[\! \begin{array}{c} 4 \\ 3\\ 2 \\ 1 \end{array} \!\right] = 4^2 + 3^2 + 2^2 + 1^2 = 30, \\ \mathbf{u}^\top \mathbf{v} & = \bigl[\! \begin{array}{cccc} 4 & 3 & 2 & 1 \end{array} \!\bigr] \left[\! \begin{array}{c} a \\ b \\ c \\ d \end{array} \!\right] = 4a+3b+2c+1d, \\ \mathbf{v}^\top \mathbf{u} & = \bigl[\! \begin{array}{c} a & b & c & d \end{array} \!\bigr] \left[\! \begin{array}{c} 4 \\ 3\\ 2 \\ 1 \end{array} \!\right] = 4a + 3b + 2c + 1 d, \\ \mathbf{v}^\top \mathbf{v} & = \bigl[\! \begin{array}{c} a & b & c & d \end{array} \!\bigr] \left[\! \begin{array}{c} a \\ b \\ c \\ d \end{array} \!\right] = a^2 + b^2 + c^2 + d^2. \end{align*} Such products are called inner products or dot products.
- We can also calculate \(4\times 4\) matrices: \begin{align*} \mathbf{u} \mathbf{u}^\top & = \left[\! \begin{array}{c} 4 \\ 3\\ 2 \\ 1 \end{array} \!\right] \bigl[\! \begin{array}{cccc} 4 & 3 & 2 & 1 \end{array} \!\bigr] = \left[\! \begin{array}{cccc} 16 & 12 & 8 & 4 \\ 12 & 9 & 6 & 3 \\ 8 & 6 & 4 & 2 \\ 4 & 3 & 2 & 1 \end{array} \!\right], \\ \mathbf{v} \mathbf{u}^\top & = \left[\! \begin{array}{c} a \\ b \\ c \\ d \end{array} \!\right] \bigl[\! \begin{array}{cccc} 4 & 3 & 2 & 1 \end{array} \!\bigr] = \left[\! \begin{array}{cccc} 4a & 3a & 2a & 1a \\ 4b & 3b & 2b & 1b \\ 4c & 3c & 2c & 1c \\ 4d & 3d & 2d & 1d \end{array} \!\right] , \\ \mathbf{u} \mathbf{v}^\top & = \left[\! \begin{array}{c} 4 \\ 3\\ 2 \\ 1 \end{array} \!\right] \bigl[\! \begin{array}{c} a & b & c & d \end{array} \!\bigr] = \left[\! \begin{array}{cccc} 4a & 4b & 4c & 4d \\ 3a & 3b & 3c & 3d \\ 2a & 2b & 2c & 2d \\ 1a & 1b & 1c & 1d \end{array} \!\right], \\ \mathbf{v} \mathbf{v}^\top & = \left[\! \begin{array}{c} a \\ b \\ c \\ d \end{array} \!\right] \bigl[\! \begin{array}{c} a & b & c & d \end{array} \!\bigr] = \left[\! \begin{array}{cccc} aa & ab & ac & ad \\ ba & bb & bc & bd \\ ca & cb & cc & cd \\ da & db & dc & dd \end{array} \!\right]. \end{align*} Such products are called outer products.
- Please pay special attention to problems 22, 23, 24, 25 from Section 2.1. In each of these problems you are asked to prove an implication.
-
For each of these problems, and in general whenever you try to prove something, you should rewrite the statement of the problem as a clear implication. That is, as a statement of the form
- Recall that the converse of the implication $p \Rightarrow q$ is the implication $q \Rightarrow p$. Also recall that the converse can be wrong when the original proposition is true.
- For Problem 22 in Section 2.1 write down the converse and answer whether it is true or false. Justify your answer.
- For Problem 24 in Section 2.1 write down the converse and answer whether it is true or false. Justify your answer. This problem is closely related to Problem 26 in Section 2.1.
-
Here is my another attempt to illustrate how matrix multiplication works. Notice that in the illustration below I lifted matrix \(A\) into a gray cloud. I did this to be able to "cross" the rows of \(A\) with the columns of \(B\) to get the colored rotated Ts, understanding of which is essential for understanding the matrix multiplication algorithm.
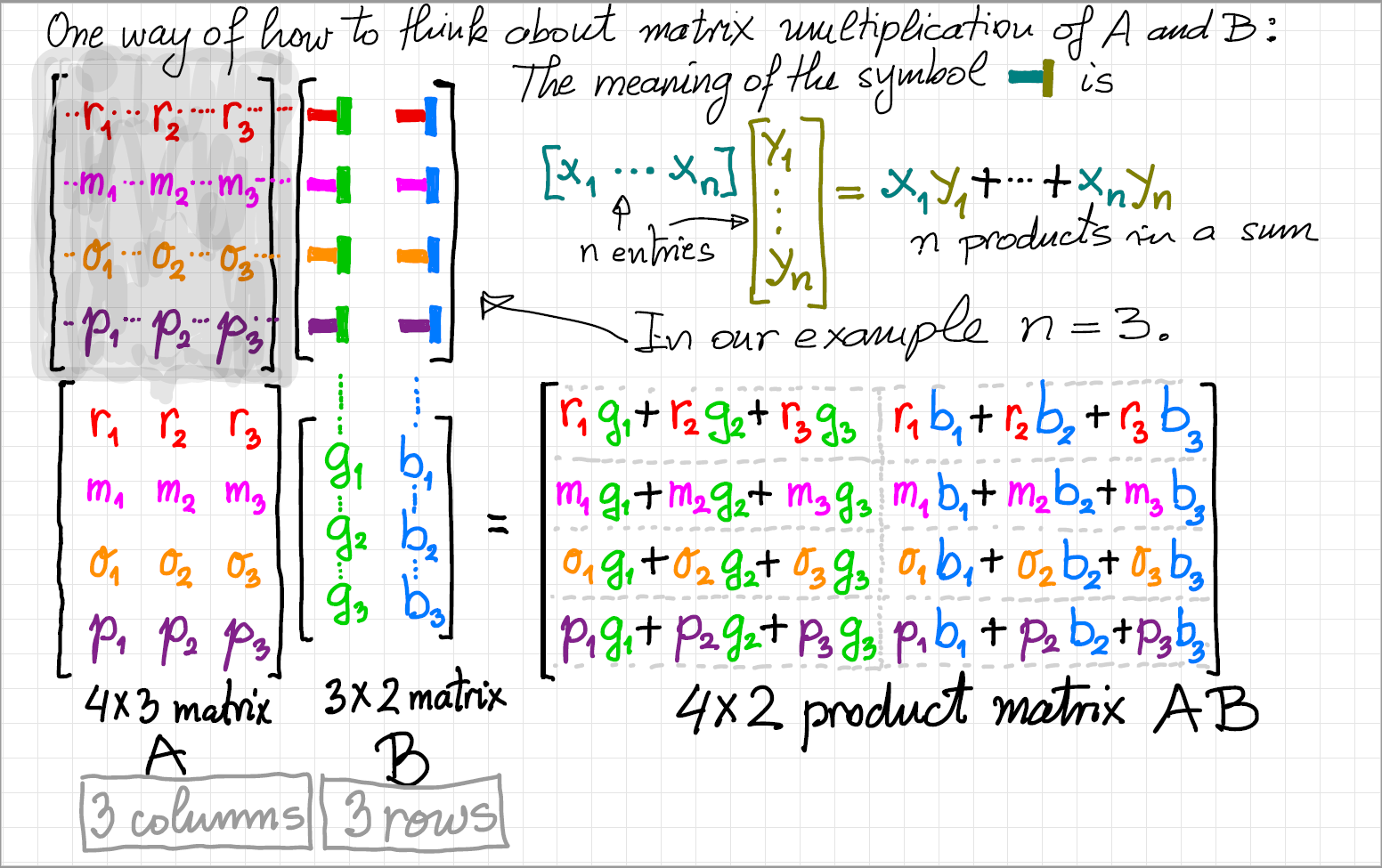
- In this item I will illustrate the multiplication of two matrices by emphasising the pattern of "rotated Ts" between $\mathbb{R}^3$ vectors: \[ \require{bbox} \bbox[#7FBFBF, 8px, border: 3px solid teal]{ \left[\! \begin{array}{rrr} 1 & 3 & 2 \\ 2 & 0 & 1 \\ 2 & 1 & 1 \\ 1 & 4 & 2 \end{array} \!\right] \left[\! \begin{array}{rrrrr} 1 & 0 & -1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 1 \\ 0 & 0 & 0 & 1 & -1 \\ \end{array} \!\right] = \left[\! \begin{array}{rrrrr} 1 & 3 & 2 & 2 & 2 \\ 2 & 0 & -2 & 1 & 1 \\ 2 & 1 & -1 & 1 & 2 \\ 1 & 4 & 3 & 2 & 3 \end{array} \!\right] }. \] Here the left matrix in the product is a $4\times\!3$ matrix with the rows: \[ \left[\! \begin{array}{r} 1 \\ 3 \\ 2 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 2 \\ 0 \\ 1 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 2 \\ 1 \\ 1 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 1 \\ 4 \\ 2 \end{array} \!\right], \] and right matrix in the product is a $3\times\!5$ matrix with the columns: \[ \left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right], \qquad \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right]. \] It is useful to think of the matrix multiplication as follows (as you read through the matrix-vector arithmetic below always look for dot products in different forms, always): \begin{align*} & \left[\!\! \begin{array}{r} \phantom{\biggl|\biggr.} \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr] \\ \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr] \\ \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr] \\ \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr] \end{array} \!\right] \left[\! \begin{array}{rrrrr} \left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \end{array} \!\right] \\ & = \left[\! \begin{array}{rrrrr} \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \end{array} \!\right] \\ & = \left[\! \begin{array}{ccccc} 1\!\cdot\!1 + 3\!\cdot\!0 + 2\!\cdot\!0 & 1\!\cdot\!0 + 3\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!(-1) + 3\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!0 + 3\!\cdot\!0 + 2\!\cdot\!1 & 1\!\cdot\!1 + 3\!\cdot\!1 + 2\!\cdot\!(-1) \\ 2\!\cdot\!1 + 0\!\cdot\!0 + 1\!\cdot\!0 & 2\!\cdot\!0 + 0\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!(-1) + 0\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!0 + 0\!\cdot\!0 + 1\!\cdot\!1 & 2\!\cdot\!1 + 0\!\cdot\!1 + 1\!\cdot\!(-1) \\ 2\!\cdot\!1 + 1\!\cdot\!0 + 1\!\cdot\!0 & 2\!\cdot\!0 + 1\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!(-1) + 1\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!0 + 1\!\cdot\!0 + 1\!\cdot\!1 & 2\!\cdot\!1 + 1\!\cdot\!1 + 1\!\cdot\!(-1) \\ 1\!\cdot\!1 + 4\!\cdot\!0 + 2\!\cdot\!0 & 1\!\cdot\!0 + 4\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!(-1) + 4\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!0 + 4\!\cdot\!0 + 2\!\cdot\!1 & 1\!\cdot\!1 + 4\!\cdot\!1 + 2\!\cdot\!(-1) \end{array} \!\right] \\ &= \left[\! \begin{array}{rrrrr} 1 & 3 & 2 & 2 & 2 \\ 2 & 0 & -2 & 1 & 1 \\ 2 & 1 & -1 & 1 & 2 \\ 1 & 4 & 3 & 2 & 3 \end{array} \!\right]. \end{align*}
-
Here is my attempt to improve Figures 2 and 3 in Section 2.1: Matrix Multiplication (page 96).
At the bottom of the snippet that I present below is a proof that for all vectors \(\mathbf{x} \in \mathbb{R}^n\) we have \((AB)\mathbf{x} = A(B\mathbf{x})\). In the proof, I use the definition of the matrix product \(AB\), the definition of the matrix vector multiplication, the linearity property of the matrix-vector multiplication, and the definition of the matrix-vector multiplication.
This proof is given in the book below Figures 2 and 3 on pages 96 and 97. I present it here in hope that you will enjoy it and understand it better in color.
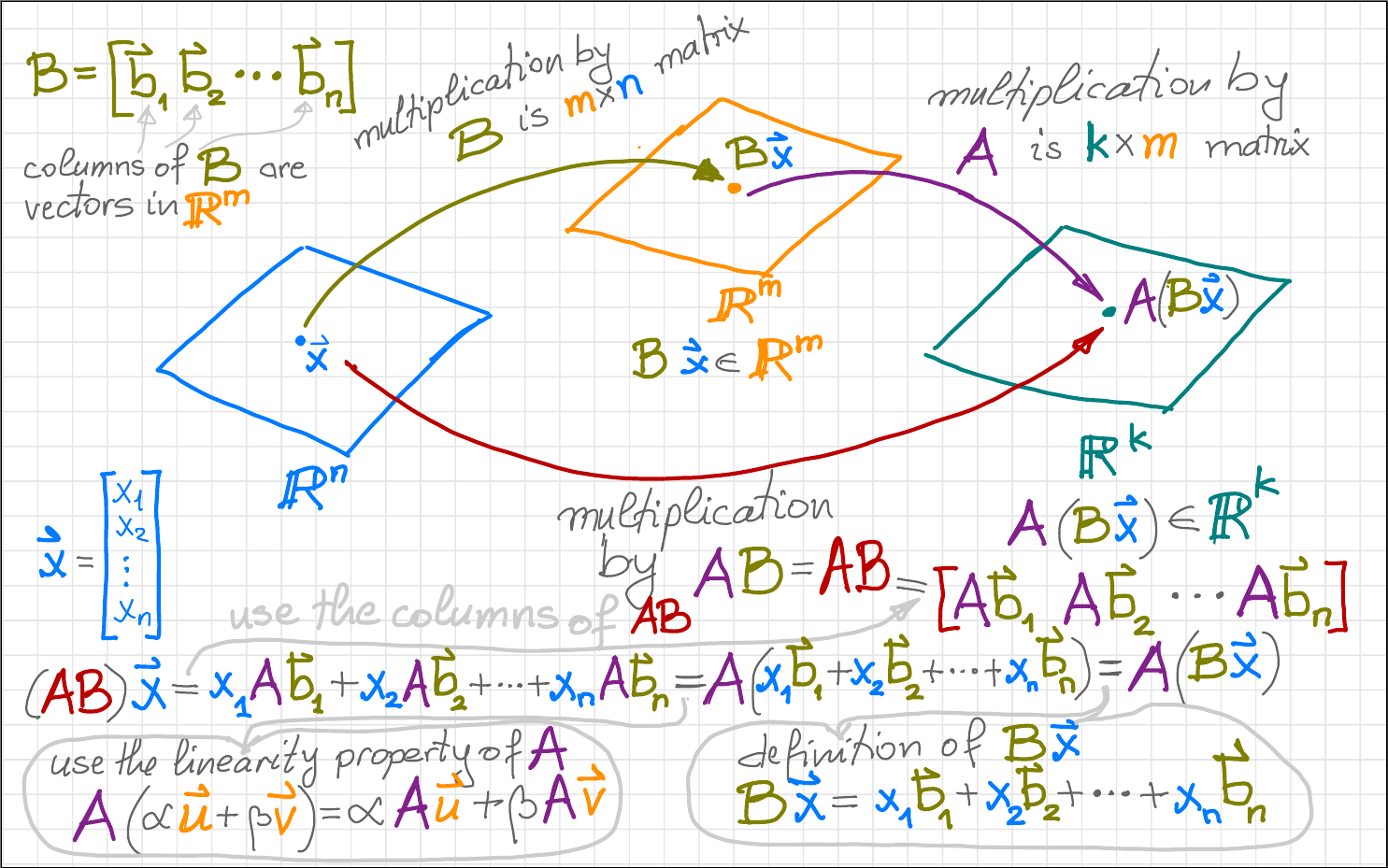
- Today we discussed Section 2.1: Matrix operations. For now, the objective is to learn matrix multiplication and how it is connected to the Reduced Row Echelon Form. Suggested problems for Section 2.1: 1, 4, 5, 7, 9, 10, 11, 12, 17, 20, 22, 23, 24, 25, 26, 27, 28, 34. The jewel of this section is Matrix Multiplication. It is a beautiful and rich concept.
-
Here is my attempt to illustrate matrix multiplication with colors:

-
Here is another attempt to illustrate matrix multiplication with colors. This time the number the matrix $A$ on the left has $n$ columns and the matrix $B$ on the right has $n$ rows. I illustrated this by representing the rows of $A$ as wide narrow rectangles and by representing the columns of $B$ as tall narrow rectangles.
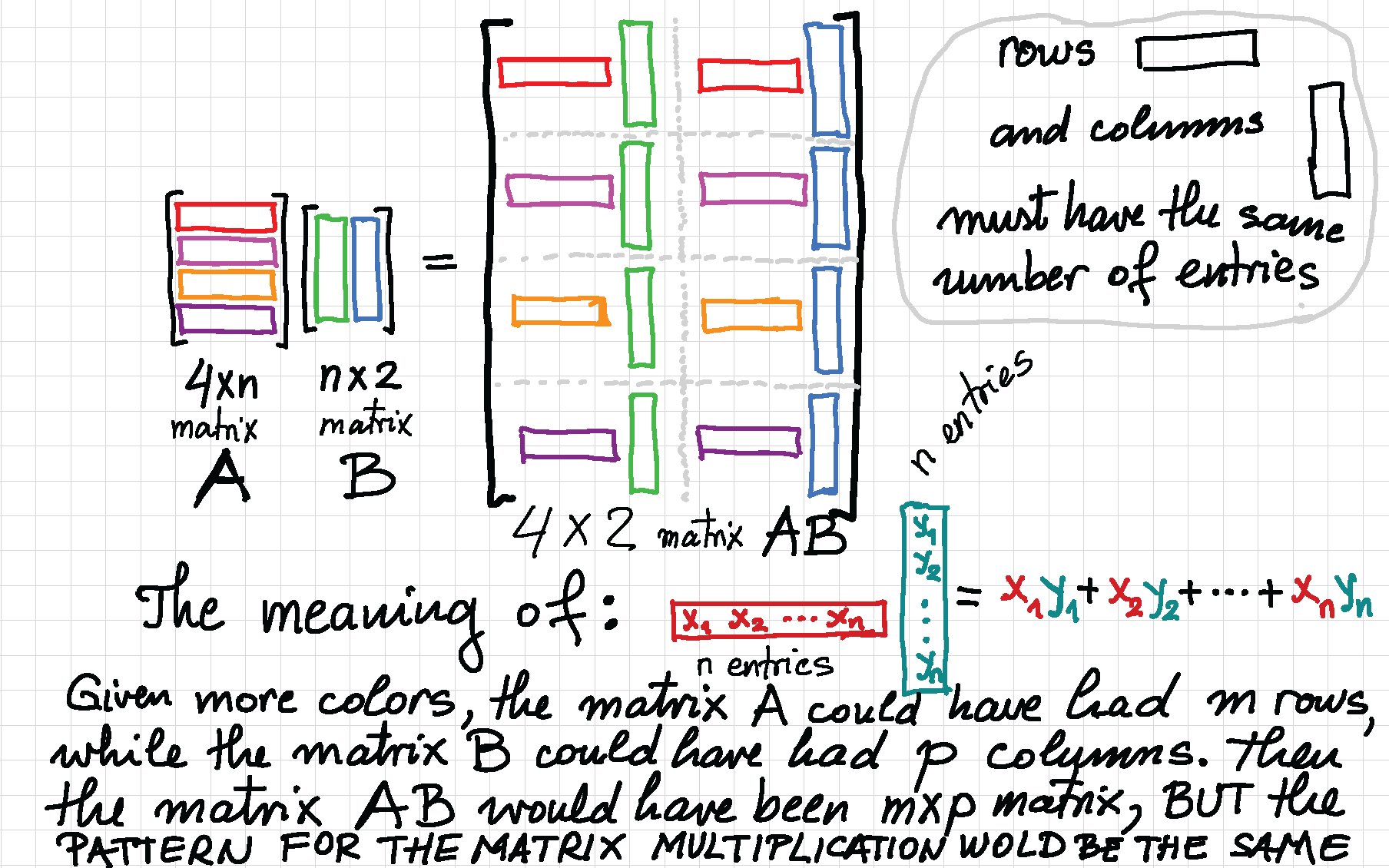
- In this item I will illustrate the multiplication of two matrices below by emphasising the pattern between $\mathbb{R}^3$ vectors: \[ \require{bbox} \bbox[#7FBFBF, 8px, border: 3px solid teal]{ \left[\! \begin{array}{rrr} 1 & 3 & 2 \\ 2 & 0 & 1 \\ 2 & 1 & 1 \\ 1 & 4 & 2 \end{array} \!\right] \left[\! \begin{array}{rrrrr} 1 & 0 & -1 & 0 & 1 \\ 0 & 1 & 1 & 0 & 1 \\ 0 & 0 & 0 & 1 & -1 \\ \end{array} \!\right] = \left[\! \begin{array}{rrrrr} 1 & 3 & 2 & 2 & 2 \\ 2 & 0 & -2 & 1 & 1 \\ 2 & 1 & -1 & 1 & 2 \\ 1 & 4 & 3 & 2 & 3 \end{array} \!\right] }. \] Here the left matrix in the product is a $4\times\!3$ matrix with the rows: \[ \left[\! \begin{array}{r} 1 \\ 3 \\ 2 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 2 \\ 0 \\ 1 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 2 \\ 1 \\ 1 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 1 \\ 4 \\ 2 \end{array} \!\right], \] and right matrix in the product is a $3\times\!5$ matrix with the columns: \[ \left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right], \qquad \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right], \qquad \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right]. \] It is useful to think of the matrix multiplication as follows (as you read through the matrix-vector arithmetic below always look for dot products in different forms, always): \begin{align*} & \left[\!\! \begin{array}{r} \phantom{\biggl|\biggr.} \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr] \\ \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr] \\ \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr] \\ \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr] \end{array} \!\right] \left[\! \begin{array}{rrrrr} \left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \end{array} \!\right] \\ & = \left[\! \begin{array}{rrrrr} \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 3 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 0 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 2 & 1 & 1 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 0 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} -1 \\ 1 \\ 0 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 0 \\ 0 \\ 1 \end{array} \!\right] & \bigl[\!\begin{array}{ccc} 1 & 4 & 2 \end{array} \!\bigr]\!\left[\! \begin{array}{r} 1 \\ 1 \\ -1 \end{array} \!\right] \\ \end{array} \!\right] \\ & = \left[\! \begin{array}{ccccc} 1\!\cdot\!1 + 3\!\cdot\!0 + 2\!\cdot\!0 & 1\!\cdot\!0 + 3\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!(-1) + 3\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!0 + 3\!\cdot\!0 + 2\!\cdot\!1 & 1\!\cdot\!1 + 3\!\cdot\!1 + 2\!\cdot\!(-1) \\ 2\!\cdot\!1 + 0\!\cdot\!0 + 1\!\cdot\!0 & 2\!\cdot\!0 + 0\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!(-1) + 0\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!0 + 0\!\cdot\!0 + 1\!\cdot\!1 & 2\!\cdot\!1 + 0\!\cdot\!1 + 1\!\cdot\!(-1) \\ 2\!\cdot\!1 + 1\!\cdot\!0 + 1\!\cdot\!0 & 2\!\cdot\!0 + 1\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!(-1) + 1\!\cdot\!1 + 1\!\cdot\!0 & 2\!\cdot\!0 + 1\!\cdot\!0 + 1\!\cdot\!1 & 2\!\cdot\!1 + 1\!\cdot\!1 + 1\!\cdot\!(-1) \\ 1\!\cdot\!1 + 4\!\cdot\!0 + 2\!\cdot\!0 & 1\!\cdot\!0 + 4\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!(-1) + 4\!\cdot\!1 + 2\!\cdot\!0 & 1\!\cdot\!0 + 4\!\cdot\!0 + 2\!\cdot\!1 & 1\!\cdot\!1 + 4\!\cdot\!1 + 2\!\cdot\!(-1) \end{array} \!\right] \\ &= \left[\! \begin{array}{rrrrr} 1 & 3 & 2 & 2 & 2 \\ 2 & 0 & -2 & 1 & 1 \\ 2 & 1 & -1 & 1 & 2 \\ 1 & 4 & 3 & 2 & 3 \end{array} \!\right]. \end{align*}
- Suggested problems for Section 1.8: 1-4, 12, 13-17, 19, 20, 25, 27, 28.
- Suggested problems for Section 1.9: 1, 3, 4, 5, 7, 8, 11, 12, 18, 19, 23 Notice that we did not discuss Definitions on page 76 and the content after these definitions.
- On each in-class exam, I assign four problems. Often these problems have several parts (a), (b), and sometimes (c) parts. In this PDF file you can find some problems in the form that they could appear on the exam.
- In the textbook the authors list several reflections transformations across some popular lines like: $x_2 = 0$ (this is $x_1$-axis), $x_1 = 0$ (this is $x_2$-axis), $x_2 = x_1$ (this is the diagonal of the first and the third quadrant), and $x_2 = -x_1$ (this is the diagonal of the second and the fourth quadrant). But why not establish the standard matrix of the reflection across the line which makes the angle $\theta$ with the positive $x_1$-semi-axis? It is not more difficult than the standard matrix of the rotation by the angle $\theta$ in counterclockwise direction, which is \[ \left[\! \begin{array}{cc} \cos(\theta) & -\sin(\theta) \\[5pt] \sin(\theta) & \cos(\theta) \end{array}\!\right] \]
-
The picture below will help us determine the standard matrix of the reflection across the blue line which makes angle $\theta$ with the positive $x_1$-semi-axis. Denote this reflection by
\[
F:\mathbb{R}^2 \to \mathbb{R}^2.
\]
To determine the standard matrix of this reflection we need to calculate the coordinates of the vectors
\[
F \mathbf{e}_1 = F \left[\! \begin{array}{c}
1 \\[3pt]
0
\end{array}\!\right] \quad \text{and} \quad F \mathbf{e}_2 = F \left[\! \begin{array}{c}
0 \\[3pt]
1
\end{array}\!\right]
\]
In the picture below the vector $F \mathbf{e}_1$ is dark orange and the vector $F \mathbf{e}_2$ dark purple.
- By the definition of the reflection $F$, the angle formed by the light orange coordinate vector $\mathbf{e}_1$ and its reflection the dark orange vector $F \mathbf{e}_1$ is $2\theta.$ Therefore, \[ F \mathbf{e}_1 = F \left[\! \begin{array}{c} 1 \\[3pt] 0 \end{array}\!\right] = \left[\! \begin{array}{c} \cos(2\theta) \\[3pt] \sin(2\theta) \end{array}\!\right]. \]
- In this item we calculate the coordinates of the dark purple vector $F \mathbf{e}_2$ which is the reflection of the light purple coordinate vector $\mathbf{e}_2.$ First, we observe that the light gray right triangles in the picture below are congruent. This claim follows from the fact that the hypothenuse of each of these triangles is of length $1$ and the triangles have the same angle $2\theta$ at the origin. That the angle at the origin of the top light gray triangle is $2\theta$ follows from the definition of the reflection. To calculate the angle at the origin for the lower light gray triangle we calculate the angle between the light purple coordinate vector $\mathbf{e}_2$ and its reflection, the dark purple vector $F \mathbf{e}_2;$ since the angle between the light purple coordinate vector $\mathbf{e}_2$ and the blue line is $\displaystyle \frac{\pi}{2} - \theta$, the angle between is $\mathbf{e}_2$ and $F \mathbf{e}_2$ is \[ 2 \left(\frac{\pi}{2} - \theta\right) = \pi - 2 \theta. \] Since the sum of this angle and the angle at the origin for the lower light gray triangle equals $\pi,$ we have proven that the angle at the origin for the lower light gray triangle equals $2\theta.$ In the preceding item we proved that the horizontal side of the top light gray right triangle is $\cos(2\theta)$ and its vertical side is $\sin(2\theta)$. As a consequence, the horizontal side of the lower light gray right triangle is $\sin(2\theta)$ and its vertical side is $\cos(2\theta)$. Adjusting for the positioning in the coordinate system we get \[ F \mathbf{e}_2 = F \left[\! \begin{array}{c} 0 \\[3pt] 1 \end{array}\!\right] = \left[\! \begin{array}{c} \sin(2\theta) \\[3pt] -\cos(2\theta) \end{array}\!\right]. \] Finally we have that the standard matrix of the reflection across the blue line which makes an angle $\theta$ with the positive $x_1$-semi-axis is \[ \left[\! \begin{array}{cc} \cos(2\theta) & \sin(2\theta) \\[5pt] \sin(2\theta) & -\cos(2\theta) \end{array}\!\right]. \] Enjoy Reflections!
 Enjoy Reflections!
Enjoy Reflections!
-
In the following examples, I demonstrate the geometric interpretation of various matrices. The textbook provides additional illustrations for a broader range of matrices.
In the examples below, the happy face is designed by the heads of the following vectors: For the face I used the circle centered at the head of the vector \(\left[\! \begin{array}{c} 1 \\ 1 \end{array} \!\right]\) and with radius \(4/5\). That is the set of the following vectors \[ \Biggl\{ \left[\! \begin{array}{c} 1 \\ 1 \end{array} \!\right] + \frac{4}{5} \left[\! \begin{array}{c} \cos t \\ \sin t \end{array} \!\right] \, : \, t \in [0, 2 \pi) \Biggr\}. \] The navy eyes are at the heads of the following two vectors \[ \frac{1}{5} \left[\! \begin{array}{c} 4 \\ 7 \end{array} \!\right], \quad \frac{1}{5} \left[\! \begin{array}{c} 6 \\ 7 \end{array} \!\right]. \] The red smile, I used the set of the following vectors \[ \Biggl\{ \left[\! \begin{array}{c} 1 \\ 1/2 \end{array} \!\right] + \frac{1}{2} \left[\! \begin{array}{c} 2 t \\ 3 t^2 \end{array} \!\right] \, : \, t \in \left[-\frac{1}{3},\frac{1}{3}\right] \Biggr\}. \]
-
The matrix resulting in the image transformation below is
\[
A = \left[\! \begin{array}{cc} 1 & 1 \\ 0 & 1 \end{array} \!\right].
\]
This transformation is called shear.
-
Below is an illustration of a rotation about the origin by the angle \(\theta = \dfrac{5 \pi}{8}\) counterclockwise. Recall that the rotation matrix about the origin by the angle \(\theta\) is
\[
R(\theta) = \left[\! \begin{array}{cc} \cos \theta & - \sin \theta \\ \sin \theta & \cos \theta \end{array} \!\right].
\]
Thus, the matrix used in the following illustration is
\[
\left[\! \begin{array}{cc} \cos\left(\dfrac{5 \pi}{8}\right) & - \sin\left(\dfrac{5 \pi}{8}\right) \\[5pt]
\sin\left(\dfrac{5 \pi}{8}\right) & \cos\left(\dfrac{5 \pi}{8}\right) \end{array} \!\right] =
- \frac{1}{2} \left[\! \begin{array}{cc} \sqrt{2-\sqrt{2}} & \sqrt{2+\sqrt{2}} \\[5pt]
- \sqrt{2+\sqrt{2}} & \sqrt{2-\sqrt{2}} \end{array} \!\right] .
\]
-
In this item we show another rotation. It is the rotation about the origin by the angle \(\theta = \dfrac{\pi}{8}\) counterclockwise. The matrix used in the following illustration is
\[
\left[\! \begin{array}{cc} \cos\left(\dfrac{\pi}{8}\right) & - \sin\left(\dfrac{\pi}{8}\right) \\[5pt]
\sin\left(\dfrac{\pi}{8}\right) & \cos\left(\dfrac{\pi}{8}\right) \end{array} \!\right] =
\frac{1}{2} \left[\! \begin{array}{cc}
\sqrt{2+\sqrt{2}} & - \sqrt{2-\sqrt{2}} \\[5pt]
\sqrt{2-\sqrt{2}} & \sqrt{2+\sqrt{2}} \end{array} \!\right] .
\]
 Notice the relationship between the rotation used in this item and the rotation in the preceding item: The angle used in the rotation in the preceding item is the sum of the angle in this item and \(\pi/2\):
\[
\dfrac{5 \pi}{8} = \dfrac{\pi}{2} + \dfrac{\pi}{8}.
\]
In the language of rotations, the rotation in the preceding item can be obtained by performing the rotation from this item and then performing the rotation by the angle \(\theta = \pi/2\). Notice that the standard matrix of the rotation by the angle \(\theta = \pi/2\) is
\[
\left[\! \begin{array}{cc} 0 & -1 \\ 1 & 0 \end{array} \!\right].
\]
Later on we will establish a close connection between the following three matrices:
\[
\frac{1}{2} \left[\! \begin{array}{cc} -\sqrt{2-\sqrt{2}} & -\sqrt{2+\sqrt{2}} \\[5pt]
\sqrt{2+\sqrt{2}} & -\sqrt{2-\sqrt{2}} \end{array} \!\right] , \quad
\left[\! \begin{array}{cc} 0 & -1 \\ 1 & 0 \end{array} \!\right],
\quad
\frac{1}{2} \left[\! \begin{array}{cc}
\sqrt{2+\sqrt{2}} & - \sqrt{2-\sqrt{2}} \\[5pt]
\sqrt{2-\sqrt{2}} & \sqrt{2+\sqrt{2}} \end{array} \!\right].
\]
To eliminate the suspense, the first matrix is the product of the second and the third matrix. We will define matrix product next week.
Notice the relationship between the rotation used in this item and the rotation in the preceding item: The angle used in the rotation in the preceding item is the sum of the angle in this item and \(\pi/2\):
\[
\dfrac{5 \pi}{8} = \dfrac{\pi}{2} + \dfrac{\pi}{8}.
\]
In the language of rotations, the rotation in the preceding item can be obtained by performing the rotation from this item and then performing the rotation by the angle \(\theta = \pi/2\). Notice that the standard matrix of the rotation by the angle \(\theta = \pi/2\) is
\[
\left[\! \begin{array}{cc} 0 & -1 \\ 1 & 0 \end{array} \!\right].
\]
Later on we will establish a close connection between the following three matrices:
\[
\frac{1}{2} \left[\! \begin{array}{cc} -\sqrt{2-\sqrt{2}} & -\sqrt{2+\sqrt{2}} \\[5pt]
\sqrt{2+\sqrt{2}} & -\sqrt{2-\sqrt{2}} \end{array} \!\right] , \quad
\left[\! \begin{array}{cc} 0 & -1 \\ 1 & 0 \end{array} \!\right],
\quad
\frac{1}{2} \left[\! \begin{array}{cc}
\sqrt{2+\sqrt{2}} & - \sqrt{2-\sqrt{2}} \\[5pt]
\sqrt{2-\sqrt{2}} & \sqrt{2+\sqrt{2}} \end{array} \!\right].
\]
To eliminate the suspense, the first matrix is the product of the second and the third matrix. We will define matrix product next week.
-
The purple line in the image below makes an angle of \(\theta = \pi/8\) with the horizontal axis. The image illustrates the reflection transformation across the purple line. As shown in an earlier item, the reflection matrix used in the image below is
\[
\left[\! \begin{array}{cc} \cos\left(2\theta\right) & \sin\left(2\theta\right) \\[5pt]
\sin\left(2\theta\right) & -\cos\left(2\theta\right) \end{array} \!\right]
= \left[\! \begin{array}{cc} \cos\left(\dfrac{\pi}{4}\right) & \sin\left(\dfrac{\pi}{4}\right) \\[5pt]
\sin\left(\dfrac{\pi}{4}\right) & -\cos\left(\dfrac{\pi}{4}\right) \end{array} \!\right] =
\left[\! \begin{array}{cc}
\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\[5pt]
\frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \end{array} \!\right].
\]
-
The teal line in the image below makes an angle of \(\theta = 7\pi/8\) with the positive horizontal semi-axis. The image illustrates the reflection transformation across the teal line. As shown in an earlier item, the reflection matrix used in the image below is
\[
\left[\! \begin{array}{cc} \cos\left(2\theta\right) & \sin\left(2\theta\right) \\[5pt]
\sin\left(2\theta\right) & -\cos\left(2\theta\right) \end{array} \!\right]
= \left[\! \begin{array}{cc} \cos\left(\dfrac{7\pi}{4}\right) & \sin\left(\dfrac{7\pi}{4}\right) \\[5pt]
\sin\left(\dfrac{7\pi}{4}\right) & -\cos\left(\dfrac{7\pi}{4}\right) \end{array} \!\right] =
\left[\! \begin{array}{cc}
\frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\[5pt]
-\frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \end{array} \!\right].
\]
- An interesting problem is to find the standard matrix of the linear transformation obtained by first reflecting across the teal line, then reflecting across the purple line, in the two preceding items. How would we find that standard matrix? To find that standard matrix we need to track the images of the standard coordinate vectors \[ \mathbf{e}_1 = \left[\! \begin{array}{c} 1 \\ 0 \end{array} \!\right] \quad \text{and} \quad \mathbf{e}_2 = \left[\! \begin{array}{c} 0 \\ 1 \end{array} \!\right]. \] Consider first the vector \(\mathbf{e}_1 = \left[\! \begin{array}{c} 1 \\ 0 \end{array} \!\right]\): Reflecting this vector across the teal line we get the vector: \[ \left[\! \begin{array}{cc} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\[5pt] -\frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \end{array} \!\right] \left[\! \begin{array}{c} 1 \\ 0 \end{array} \!\right] = \left[\! \begin{array}{c} \frac{\sqrt{2}}{2} \\[5pt] - \frac{\sqrt{2}}{2} \end{array} \!\right]. \] Reflecting the last vector across the purple line we get the vector: \[ \left[\! \begin{array}{cc} \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\[5pt] \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \end{array} \!\right] \left[\! \begin{array}{c} \frac{\sqrt{2}}{2} \\[5pt] -\frac{\sqrt{2}}{2}\end{array} \!\right] = \left[\! \begin{array}{c} 0 \\ 1 \end{array} \!\right]. \] Now, consider the vector \(\mathbf{e}_2 = \left[\! \begin{array}{c} 0 \\ 1 \end{array} \!\right]\): Reflecting this vector across the teal line we get the vector: \[ \left[\! \begin{array}{cc} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\[5pt] -\frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \end{array} \!\right] \left[\! \begin{array}{c} 0 \\ 1 \end{array} \!\right] = \left[\! \begin{array}{c} -\frac{\sqrt{2}}{2} \\[5pt] -\frac{\sqrt{2}}{2} \end{array} \!\right]. \] Reflecting the last vector across the purple line we get the vector: \[ \left[\! \begin{array}{cc} \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\[5pt] \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \end{array} \!\right] \left[\! \begin{array}{c} -\frac{\sqrt{2}}{2} \\[5pt] -\frac{\sqrt{2}}{2} \end{array} \!\right] = \left[\! \begin{array}{c} -1 \\ 0 \end{array} \!\right]. \] Thus, we have that the linear transformation obtained by first reflecting across the teal line, then reflecting across the purple line maps \[ \left[\! \begin{array}{c} 1 \\ 0 \end{array} \!\right] \quad \text{to} \quad \left[\! \begin{array}{c} 0 \\ 1 \end{array} \!\right] \qquad \text{and} \qquad \left[\! \begin{array}{c} 0 \\ 1 \end{array} \!\right] \quad \text{to} \quad \left[\! \begin{array}{c} -1 \\ 0 \end{array} \!\right]. \] Hence, the standard matrix of the linear transformation obtained by first reflecting across the purple line, then reflecting across the teal line is \[ \left[\! \begin{array}{cc} 0 & -1 \\ 1 & 0 \end{array} \!\right]. \] We have seen this matrix before. This is the rotation matrix by the angle \(\theta = \pi/2\). That is \[ \left[\! \begin{array}{cc} \cos\left(\dfrac{\pi}{2}\right) & -\sin\left(\dfrac{\pi}{2}\right) \\[5pt] \sin\left(\dfrac{\pi}{2}\right) & \cos\left(\dfrac{\pi}{2}\right) \end{array} \!\right] = \left[\! \begin{array}{cc} 0 & -1 \\ 1 & 0 \end{array} \!\right]. \] In conclusion, in this example, the composition of two reflections is a rotation. We will later prove this fact for any two rotations.
-
The image below illustrates the linear transformation from \(\mathbb{R}^2\) into \(\mathbb{R}^3\) given by the matrix
\[
A = \left[\! \begin{array}{cc} 0 & 0 \\[5pt]
1 & 0 \\ 0 & 1 \end{array} \!\right].
\]
-
The image below illustrates the linear transformation from \(\mathbb{R}^2\) into \(\mathbb{R}^3\) given by the matrix
\[
A = \left[\! \begin{array}{cc} 1 & -1 \\[5pt]
2 & 0 \\ 1 & 1 \end{array} \!\right].
\]
-
Here is my attempt to illustrate matrix-vector multiplication with colors:
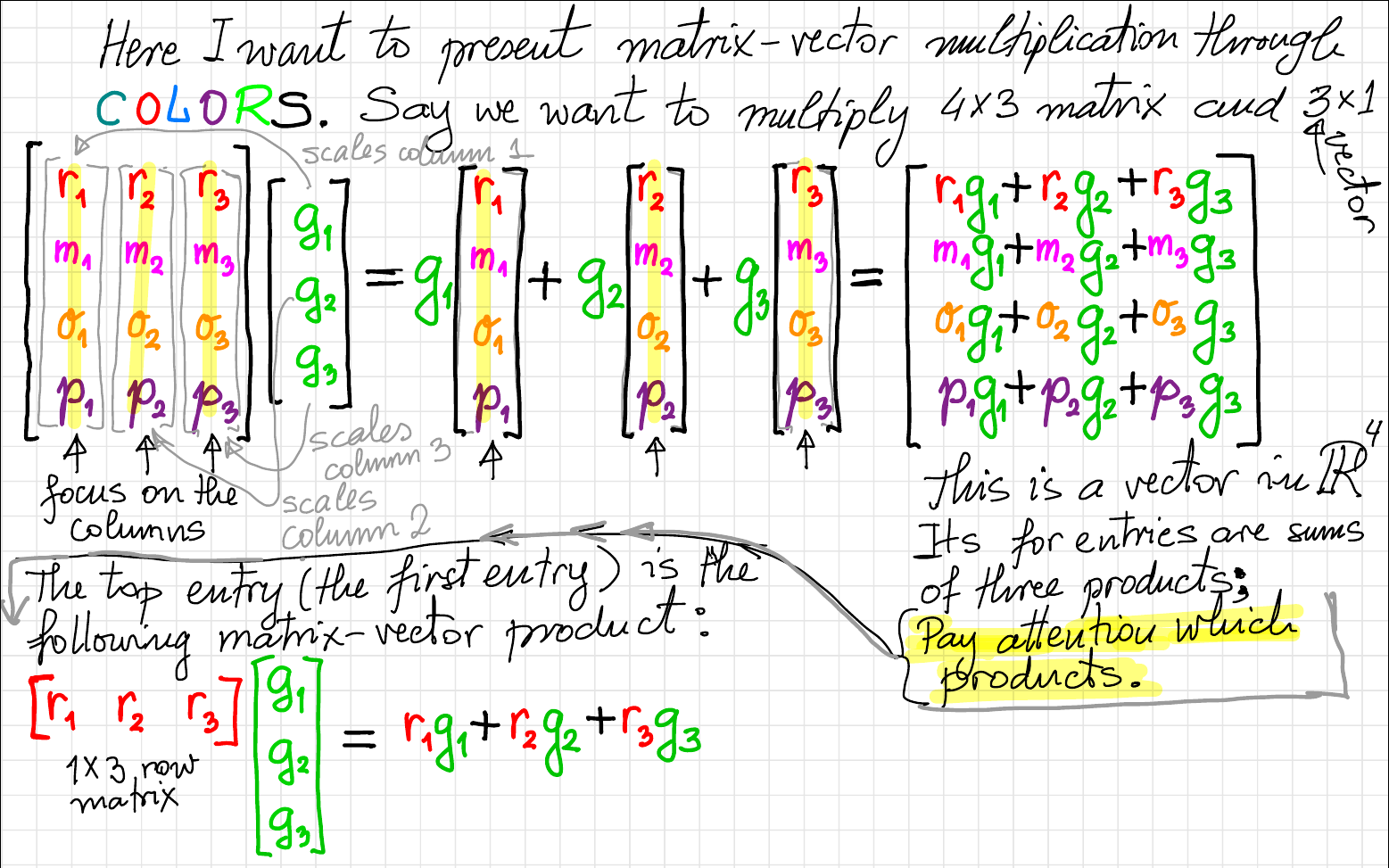
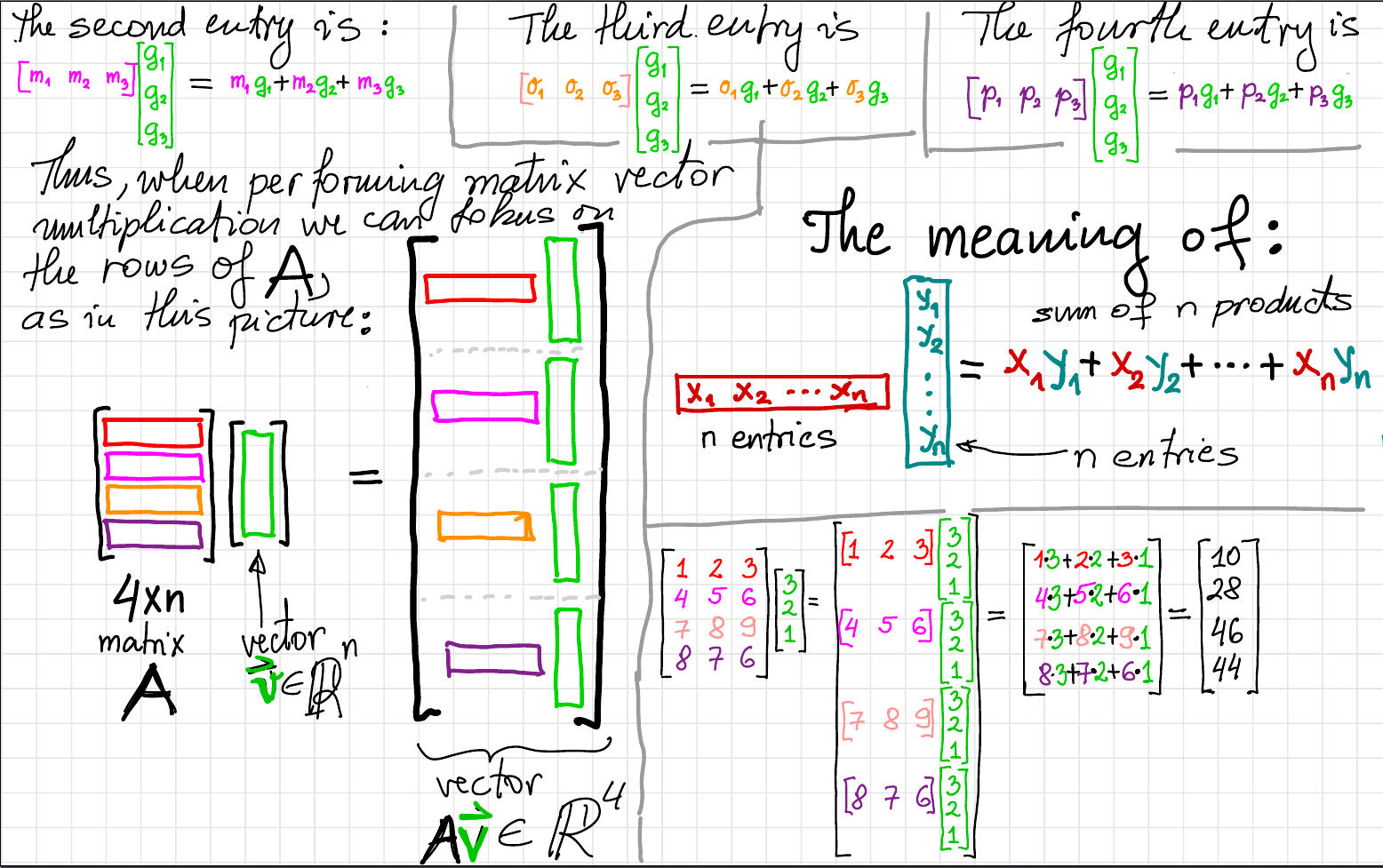
- We did a part of Section 1.8 on Friday. We will continue on Monday and also do Section 1.9.
- Suggested problems for Section 1.8: 1-4, 12, 13-17, 19, 20, 25, 27, 28
- We discussed Section 1.7: Linear independence today. Suggested problems: 2, 4, 5, 8, 10, 11, 17, 21, 23, 24, 25, 26, 27, 28, 29, 32, 33, 34, 35, 36, 37, 38, 39, 40 and read the next item.
-
Problems 41, 42, 43, 44 in Section 1.7: Linear independence are very interesting and important. The matrices in these problems are not easy to row reduce by hand, so the textbook recommends that we use a calculator. Below I calculated RREFs for the matrices given in Problems 41 and 42. Based on these RREFs you should be able to answer Problems 41, 42, 43, 44.
Problem 41 \[ \left[ \begin{array}{rrrrrr} 8 & -3 & 0 & -7 & 2 \\ -9 & 4 & 5 & 11 & -7 \\ 6 & -2 & 2 & -4 & 4 \\ 5 & -1 & 7 & 0 & 10 \\ \end{array} \right] \sim \quad \cdots \quad \sim \left[ \begin{array}{ccccc} 1 & 0 & 3 & 1 & 0 \\ 0 & 1 & 8 & 5 & 0 \\ 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 & 0 \\ \end{array} \right] \]
Problem 42 \[ \left[ \begin{array}{rrrrrr} 12 & 10 & -6 & -3 & 7 & 10 \\ -7 & -6 & 4 & 7 & -9 & 5 \\ 9 & 9 & -9 & -5 & 5 & -1 \\ -4 & -3 & 1 & 6 & -8 & 9 \\ 8 & 7 & -5 & -9 & 11 & -8 \\ \end{array} \right] \sim \quad \cdots \quad \sim \left[ \begin{array}{rrrrrr} 1 & 0 & 2 & 0 & 2 & 0 \\ 0 & 1 & -3 & 0 & -2 & 0 \\ 0 & 0 & 0 & 1 & -1 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ \end{array} \right] \]
-
Below I am offering a simpler matrix and more detailed guidance for the calculations needed for Problems 41, 42, 43, 44 in Section 1.7. This is my version of these four problems.
Problem. Consider the following $4\times 6$ matrix \[ A = \left[ \begin{array}{cccccc} 1 & 1 & 4 & 1 & 0 & 6 \\ 2 & 1 & 3 & 0 & 1 & 4 \\ 3 & 1 & 2 & 1 & 0 & 8 \\ 4 & 1 & 1 & 0 & 1 & 6 \\ \end{array} \right]. \] Denote the columns of $A$ by $\mathbf{a}_1,$ $\mathbf{a}_2,$ $\mathbf{a}_3,$ $\mathbf{a}_4,$ $\mathbf{a}_5,$ and $\mathbf{a}_6.$ That is, \[ \mathbf{a}_1 = \left[ \begin{array}{cccccc} 1 \\ 2 \\ 3 \\ 4 \\ \end{array} \right], \ \mathbf{a}_2 = \left[ \begin{array}{c} 1\\ 1 \\ 1 \\ 1 \\ \end{array} \right], \ \mathbf{a}_3 = \left[ \begin{array}{c} 4 \\ 3 \\ 2 \\ 1 \\ \end{array} \right], \ \mathbf{a}_4 = \left[ \begin{array}{c} 1 \\ 0 \\ 1 \\ 0 \\ \end{array} \right], \ \mathbf{a}_5 = \left[ \begin{array}{c} 0\\ 1\\ 0\\ 1 \\ \end{array} \right], \ \mathbf{a}_6 = \left[ \begin{array}{c} 6 \\ 4 \\ 8 \\ 6 \\ \end{array} \right]. \] Answer the following questions:
- Find the Reduced Row Echelon Form of $A$. (Please make sure that it is done correctly.)
- Is the vector $\mathbf{a}_1$ linearly independent? Explain using the definition.
- Are the vectors $\mathbf{a}_1,$ $\mathbf{a}_2$ linearly independent? Explain using the definition.
- Are the vectors $\mathbf{a}_1,$ $\mathbf{a}_2,$ $\mathbf{a}_3$ linearly independent? Explain using the definition. If the answer is No, then express $\mathbf{a}_3$ as a linear combination of $\mathbf{a}_1$ and $\mathbf{a}_2.$ That is, find the real numbers $\alpha_1$ and $\alpha_2$ such that \[ \mathbf{a}_3 = \alpha_1 \mathbf{a}_1+ \alpha_2 \mathbf{a}_2. \] Make a record of the numbers $\alpha_1$ and $\alpha_2.$
- Are the vectors $\mathbf{a}_1,$ $\mathbf{a}_2,$ $\mathbf{a}_4$ linearly independent? Explain using the definition.
- Are the vectors $\mathbf{a}_1,$ $\mathbf{a}_2,$ $\mathbf{a}_4,$ $\mathbf{a}_5$ linearly independent? Explain using the definition. If the answer is No, then express $\mathbf{a}_5$ as a linear combination of $\mathbf{a}_1,$ $\mathbf{a}_2$ and $\mathbf{a}_4.$ That is, find the real numbers $\beta_1,$ $\beta_2$ and $\beta_4$ such that \[ \mathbf{a}_5 = \beta_1 \mathbf{a}_1+ \beta_2 \mathbf{a}_2 + \beta_4 \mathbf{a}_4. \] Make a record of the numbers $\beta_1,$ $\beta_2$ and $\beta_4.$
- Are the vectors $\mathbf{a}_1,$ $\mathbf{a}_2,$ $\mathbf{a}_4,$ $\mathbf{a}_6$ linearly independent? Explain using the definition. If the answer is No, then express $\mathbf{a}_6$ as a linear combination of $\mathbf{a}_1,$ $\mathbf{a}_2$ and $\mathbf{a}_4.$ That is, find the real numbers $\gamma_1,$ $\gamma_2$ and $\gamma_4$ such that \[ \mathbf{a}_6 = \gamma_1 \mathbf{a}_1+ \gamma_2 \mathbf{a}_2 + \gamma_4 \mathbf{a}_4. \] Make a record of the numbers $\gamma_1,$ $\gamma_2$ and $\gamma_4.$
- The moral of this problem is that all the information you found about the linear independence and dependence of the columns of $A$ is contained in the Reduced Row Echelon Form of $A$. I would like you to carefully review your findings and discover how are all the facts about the columns of $A$ that you found in this problem encoded in the Reduced Row Echelon Form of $A$.
-
Let me answer some of the questions asked in the above boxed Problem.
- The row reduction algorithm applied to the matrix $A$ gives its Reduced Row Echelon Form: \[ A = \Bigl[ \begin{array}{cccccc} \mathbf{a}_1 & \mathbf{a}_2 & \mathbf{a}_3 & \mathbf{a}_4 & \mathbf{a}_5 & \mathbf{a}_6 \end{array} \Bigr] = \left[ \begin{array}{cccccc} 1 & 1 & 4 & 1 & 0 & 6 \\ 2 & 1 & 3 & 0 & 1 & 4 \\ 3 & 1 & 2 & 1 & 0 & 8 \\ 4 & 1 & 1 & 0 & 1 & 6 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{ccrcrc} 1 & 0 & -1 & 0 & 0 & 1 \\ 0 & 1 & 5 & 0 & 1 & 2 \\ 0 & 0 & 0 & 1 & -1 & 3 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ \end{array} \right]. \] Remark We obtained the preceding RREF by performing row operations on the rows of $A.$ It is important to realize that the same row operations would lead to the following Reduced Row Echelon Forms: \[ \Bigl[ \begin{array}{cc} \mathbf{a}_1 & \mathbf{a}_2 \end{array} \Bigr] = \left[ \begin{array}{cc} 1 & 1 \\ 2 & 1 \\ 3 & 1 \\ 4 & 1 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right] \] and \[ \Bigl[ \begin{array}{ccc} \mathbf{a}_1 & \mathbf{a}_2 & \mathbf{a}_3 \end{array} \Bigr] = \left[ \begin{array}{ccc} 1 & 1 & 4 \\ 2 & 1 & 3 \\ 3 & 1 & 2 \\ 4 & 1 & 1 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{ccrcrc} 1 & 0 & -1 \\ 0 & 1 & 5 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \\ \end{array} \right] \] and \[ \Bigl[ \begin{array}{ccc} \mathbf{a}_1 & \mathbf{a}_2 & \mathbf{a}_4 \end{array} \Bigr] = \left[ \begin{array}{ccc} 1 & 1 & 1 \\ 2 & 1 & 0 \\ 3 & 1 & 1 \\ 4 & 1 & 0 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \\ \end{array} \right] \] and \[ \Bigl[ \begin{array}{cccc} \mathbf{a}_1 & \mathbf{a}_2 & \mathbf{a}_4 & \mathbf{a}_5 \end{array} \Bigr] = \left[ \begin{array}{cccc} 1 & 1 & 1 & 0 \\ 2 & 1 & 0 & 1 \\ 3 & 1 & 1 & 0 \\ 4 & 1 & 0 & 1 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{ccrcrc} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & -1 \\ 0 & 0 & 0 & 0 \\ \end{array} \right] \] and \[ \Bigl[ \begin{array}{cccc} \mathbf{a}_1 & \mathbf{a}_2 & \mathbf{a}_4 & \mathbf{a}_5 \end{array} \Bigr] = \left[ \begin{array}{cccc} 1 & 1 & 1 & 0 \\ 2 & 1 & 0 & 1 \\ 3 & 1 & 1 & 0 \\ 4 & 1 & 0 & 1 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{ccrcrc} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & -1 \\ 0 & 0 & 0 & 0 \\ \end{array} \right] \] and \[ \Bigl[ \begin{array}{cccc} \mathbf{a}_1 & \mathbf{a}_2 & \mathbf{a}_4 & \mathbf{a}_6 \end{array} \Bigr] = \left[ \begin{array}{cccc} 1 & 1 & 1 & 6 \\ 2 & 1 & 0 & 4 \\ 3 & 1 & 1 & 8 \\ 4 & 1 & 0 & 6 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{ccrcrc} 1 & 0 & 0 & 1 \\ 0 & 1 & 0 & 2 \\ 0 & 0 & 1 & 3 \\ 0 & 0 & 0 & 0 \\ \end{array} \right]. \]
- The vector $\mathbf{a}_1$ is linearly independent. Recall the definition of linear independence. A vector $\mathbf{v}_1$ is linearly independent if the homogeneous equation $x_1 \mathbf{v}_1 = \mathbf{0}$ has only the trivial solution. Consider the homogeneous equation $x_1 \mathbf{a}_1 = \mathbf{0}.$ The preceding equation is equivalent to \[ x_1 \left[ \begin{array}{cccccc} 1 \\ 2 \\ 3 \\ 4 \\ \end{array} \right] = \left[ \begin{array}{cccccc} 0 \\ 0 \\ 0 \\ 0 \\ \end{array} \right], \] which in turn is equivalent to $x_1 = 0.$ Hence the equation $x_1 \mathbf{a}_1 = \mathbf{0}$ has only the trivial solution. This proves that the vector $\mathbf{a}_1$ is linearly independent.
- The vectors $\mathbf{a}_1$ and $\mathbf{a}_2$ are linearly independent. To prove this claim we need to prove that the homogeneous vector equation $x_1 \mathbf{a}_1 + x_2 \mathbf{a}_2 = \mathbf{0}$ has only the trivial solution. Since we already know that \[ \Bigl[ \begin{array}{cc} \mathbf{a}_1 & \mathbf{a}_2 \end{array} \Bigr] = \left[ \begin{array}{cc} 1 & 1 \\ 2 & 1 \\ 3 & 1 \\ 4 & 1 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right], \] the equation $x_1 \mathbf{a}_1 + x_2 \mathbf{a}_2 = \mathbf{0}$ is equivalent to the equation \[ x_1 \left[ \begin{array}{c} 1 \\ 0 \\ 0 \\ 0 \\ \end{array} \right] + x_2 \left[ \begin{array}{c} 0 \\ 1 \\ 0 \\ 0 \\ \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \\ 0 \\ 0 \\ \end{array} \right] \] and the last equation is equivalent to $x_1 = 0$ and $x_2 =0$. Hence $\mathbf{a}_1$ and $\mathbf{a}_2$ are linearly independent.
- The vectors $\mathbf{a}_1,$ $\mathbf{a}_2,$ $\mathbf{a}_3$ are not linearly independent. These vectors are linearly dependent. We claim that the homogeneous vector equation $x_1 \mathbf{a}_1 + x_2 \mathbf{a}_2 + x_3 \mathbf{a}_3 = \mathbf{0}$ has infinitely many solution. Since we already know that \[ \Bigl[ \begin{array}{ccc} \mathbf{a}_1 & \mathbf{a}_2 & \mathbf{a}_3 \end{array} \Bigr] = \left[ \begin{array}{ccc} 1 & 1 & 4 \\ 2 & 1 & 3 \\ 3 & 1 & 2 \\ 4 & 1 & 1 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{ccr} 1 & 0 & -1 \\ 0 & 1 & 5 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \\ \end{array} \right], \] the equation $x_1 \mathbf{a}_1 + x_2 \mathbf{a}_2 + x_3 \mathbf{a}_3= \mathbf{0}$ is equivalent to the equation \[ x_1 \left[ \begin{array}{c} 1 \\ 0 \\ 0 \\ 0 \\ \end{array} \right] + x_2 \left[ \begin{array}{c} 0 \\ 1 \\ 0 \\ 0 \\ \end{array} \right] + x_2 \left[ \begin{array}{r} -1 \\ 5 \\ 0 \\ 0 \\ \end{array} \right]= \left[ \begin{array}{c} 0 \\ 0 \\ 0 \\ 0 \\ \end{array} \right]. \] In the last equation the variable $x_3$ is free. All solutions of this equation are given by $x_1 = s,$ $x_2 = -5s,$ $x_3 = s$ where $s$ is any real number. For $s=1$ we get a specific linear dependence relation \[ 1 \mathbf{a}_1 + (-5) \mathbf{a}_2 + 1 \mathbf{a}_3 = \mathbf{0}. \] A different way to get the same relation is to solve the nonhomogeneous equation $x_1 \mathbf{a}_1 + x_2 \mathbf{a}_2 = \mathbf{a}_3.$ It is very interesting to observe that we already have everything that we need to solve this equation. We already know that \[ \Bigl[ \begin{array}{cc|c} \mathbf{a}_1 & \mathbf{a}_2 & \mathbf{a}_3 \end{array} \Bigr] = \left[ \begin{array}{ccc} 1 & 1 & 4 \\ 2 & 1 & 3 \\ 3 & 1 & 2 \\ 4 & 1 & 1 \\ \end{array} \right] \sim \cdots \sim \left[ \begin{array}{cc|r} 1 & 0 & -1 \\ 0 & 1 & 5 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \\ \end{array} \right]. \] Therefore, $x_1 \mathbf{a}_1 + x_2 \mathbf{a}_2 = \mathbf{a}_3$ is equivalent to the equation \[ x_1 \left[ \begin{array}{c} 1 \\ 0 \\ 0 \\ 0 \\ \end{array} \right] + x_2 \left[ \begin{array}{c} 0 \\ 1 \\ 0 \\ 0 \\ \end{array} \right] = \left[ \begin{array}{r} -1 \\ 5 \\ 0 \\ 0 \\ \end{array} \right]. \] Hence the only solution of the nonhomogeneous equation $x_1 \mathbf{a}_1 + x_2 \mathbf{a}_2 = \mathbf{a}_3$ is $x_1 = -1$ and $x_2 = 5.$ That is \[ \mathbf{a}_3 = (-1) \mathbf{a}_1 +5 \mathbf{a}_2. \] Verify! \[ \left[ \begin{array}{r} 4 \\ 3 \\ 2 \\ 1 \\ \end{array} \right] = (-1) \left[ \begin{array}{c} 1 \\ 2 \\ 3 \\ 4 \\ \end{array} \right] + 5 \left[ \begin{array}{c} 1 \\ 1 \\ 1 \\ 1 \\ \end{array} \right]. \]
- Similar to III.
- Similar to IV.
- Similar to IV and VI.
- Would you please think about this? The connections that are present in RREF are beautiful. We will discuss these many times in future classes.
- We discussed Section 1.6: Applications of Linear Systems. We did four applications. Two from this section: Balancing Chemical Equations and Network Flow. Suggested problems for Section 1.6: 5-8, 11-14. Please pay attention to Problem 11.
-
The third application was finding an approximation for the steady-state temperature distribution of a thin plate when the temperature around the boundary is known. This is explained in Problems 33 and 34 in Section 1.1. These problems explain how to find an approximation for the steady-state temperature distribution of a thin plate when the temperature around the boundary is known. In Problems 33 and 34, approximations for the steady-state temperature distribution are found at only four points. However, this problem gives a blueprint on how to find the approximations at any rectangular grid of points. Below, I do it for a \(2\times 3\) grid of six points and a \(3\times 4\) grid of twelve points
-
Consider the following grid which represents a heated plate:
-
Consider the following grid which represents a heated plate:
-
The following grid has \(20\times 30 = 600\) unknowns and \(2\times (20+30) = 100\) given temperature values.

I did not try it, but I believe that Mathematica would solve the corresponding system of \(600\) equations with \(600\) unknowns relatively quickly and that would give a good approximation of the heat distribution in this plate, The advantage of this system us that it has a lot of zeros. The matrix of this system is of the size \(600\times 600\). Thus it has \(360,000\) entries. Based on the patterns that we observed for small matrices above, I estimate that this \(600\times 600\) matrix has less than \(3,000\) nonzero entries. That is less than 1 in 120 entries is nonzero; that is less than 0.083%.
Matrices with a small percentage of nonzero entries are called sparse matrices. Mathematicians have developed super efficient methods of doing calculations with sparse matrices of huge size.
- In Math 430 we show how to find the steady-state temperature distribution in a thin plate when the temperature around the boundary is known using partial differential equations.
-
Consider the following grid which represents a heated plate:
-
My favorite application of vectors: COLORS. In fact, I love this application so much that I wrote a webpage to celebrate it: Color Cube.
One exercise in this context would be to ask you to find three colors which are between teal and yellow, one in the middle between teal and yellow and the other two in the middle between teal and the mid-color and in the middle of mid-color and yellow.
- Today we finished Section 1.4: The Matrix Equation: $A\mathbf{x} = \mathbf{b}$ and Section 1.5: Solution Sets Of Linear Systems.
-
Section 1.5 talks about writing solution sets of linear systems in parametric vector form.
We explained the relationship between the solution set of the homogeneous equation \[ \color{green}{A}\color{red}{\mathbf{x}} = \mathbf{0} \] and the solution set of a consistent nonhomogeneous equation \[ \color{green}{A}\color{red}{\mathbf{x}} = \color{green}{\mathbf{b}}. \] This is explained in Theorem 6 in the book. Please recognize how this theorem is reflected when the solution of $A \mathbf x = \mathbf b$ is written in parametric vector form.
Suggested problems for Section 1.5: 1, 3, 5, 6, 7, 9, 11, 12, 13-16, 19, 21, 23, 24, 26, 29, 32, 35, 37-40. When you write a formula for the solution of a nonhomogeneous equation in parametric form, try to recognize a particular solution $\color{purple}{\mathbf{p}}$ of the nonhomogeneous equation and a span of one, or two, or three vectors which is the solution of the corresponding homogeneous equation.
-
Let $m, n \in \mathbb{N}.$ Let $\color{green}{A}$ be an $m\times n$ matrix. A few points about the solution set of a homogeneous equation
\[
\color{green}{A}\color{red}{\mathbf{x}} = \mathbf{0}.
\]
The preceding matrix equation can be rewritten as a homogenous system with $m$ equations and $n$ unknowns. The unknowns are collected in the vector $\color{red}{\mathbf{x}} \in \mathbb{R}^n.$ Here $\mathbf{0}$ is the zero vector in $\mathbb{R}^m.$
- The homogeneous equation $\color{green}{A}\color{red}{\mathbf{x}} = \mathbf{0}$ always has a solution (it is consistent). One solution is always the zero vector in $\mathbb{R}^n.$
- Another explanation why the homogeneous equation $\color{green}{A}\color{red}{\mathbf{x}} = \mathbf{0}$ always has a solution is to consider its augmented matrix \[ \bigl[\begin{array}{c|c} \color{green}{A} & \mathbf{0} \end{array} \bigr]. \] As we perform row reduction, the last column will always be $\mathbf{0}.$ Therefore the last column of the reduced row echelon form of the matrix $\bigl[\begin{array}{c|c} \color{green}{A} & \mathbf{0} \end{array} \bigr]$ will not be a pivot column. Hence the matrix equation $\color{green}{A}\color{red}{\mathbf{x}} = \mathbf{0}$ is consistent.
-
We have the following dichotomy for the solution:
- The zero vector in $\mathbb{R}^n$ is a unique solution. This case occurs if and only if each column of the reduced row echelon form of $\color{green}{A}$ is a pivot column. In other words, there are no free variables.
- There are infinitely many solutions. This case occurs if and only if there are free variables. In this case the solution set can be written as a span of several vectors. In fact, we can write the solution set as a span of as many vectors as there are free variables.
- For example, let $\color{green}{A}$ be a $3\times 4$ matrix and assume that \[ \bigl[\begin{array}{c|c} \color{green}{A} & \mathbf{0} \end{array} \bigr] \sim \cdots \sim \left[\!\begin{array}{rrrr|r} 1 & -2 & 0 & -1 & 0 \\ 0 & 0 & 1 & 2 & 0 \\ 0 & 0 & 0 & 0 & 0 \end{array}\! \right] \] In this case we have two free variables and the solution set of the matrix equation $\color{green}{A}\color{red}{\mathbf{x}} = \mathbf{0}$ can be written as a span of two vectors in $\mathbb{R}^4.$ To find those vectors we need to solve the corresponding system of linear equations: \begin{alignat*}{10} &x_1 & & - &&2 x_2 & & && && && - && && x_4 && = &&0\\ & & & && & & && &&x_3 && + && 2 && x_4 && = &&0 \end{alignat*} The solution of this system in parametric vector form is \[ \left[\!\begin{array}{c} x_1 \\ x_2 \\ x_3 \\ x_4 \end{array}\! \right] = \left[\!\begin{array}{c} 2 s + t \\ s \\ -2 t \\ t \end{array}\! \right] = \left[\!\begin{array}{c} 2 s + 1 t \\ 1 s + 0 t \\ 0 s -2 t \\ 0 s + 1 t \end{array}\! \right] = s \left[\!\begin{array}{c} 2 \\ 1 \\ 0 \\ 0 \end{array}\! \right] + t \left[\!\begin{array}{r} 1 \\ 0 \\ -2 \\ 1 \end{array}\! \right], \] where $s$ and $t$ are arbitrary real numbers. Hence, the solution set of the homogeneous matrix equation $\color{green}{A}\color{red}{\mathbf{x}} = \mathbf{0}$ can be written as \[ \operatorname{Span}\left\{ \left[\!\begin{array}{c} 2 \\ 1 \\ 0 \\ 0 \end{array}\! \right], \left[\!\begin{array}{r} 1 \\ 0 \\ -2 \\ 1 \end{array}\! \right] \right\}. \]
-
At the beginning of class today you asked me about my favorite color. The answer is TEAL. I love using colors on my websites. On my websites, or in Mathematica, to chose colors I always use RGB (red-green-blue) color encoding. That is expression which encodes each color as a triple of numbers. In HTML the triple for TEAL is written as a #008080. Here HTML uses two three two digit numbers in hexadecimal number system. The hexadecimal digits are 0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F. HTML encodes colors with triples of integers between 0, which they write as 00 and 255 which in hexadecimal number system is FF. In hexadecimal number system, the number 80 stands for 128, half-way between 0 and 255.
It is hard to see a vector in #008080. However, in CSS, the triple for TEAL can be written as rgb(0%,50%,50%). This is getting closer to a vector, when you view percentages as their fractional values. So, the vector (0%,50%,50%) is (0,1/2,1/2). So, each color can be identified by a vector whose components are real numbers between 0 and 1.
So I started the class by talking about the colors in relation to linear algebra. I love the application of vectors to COLORS so much that I wrote a webpage to celebrate it: Color Cube.
-
Did you work on Problem 32 in Section 1.3? I find this problem interesting. I like it so much that I decided to rewrite it and give more information in the associated pictures. I do it in the next item.
An interesting feature of the Problem in the next item is that you do not need to know the specific coordinates of the vectors in the picture to answer the questions. You only need to record the linear relationships among vectors that are clear from the given grids: the vectors $\color{green}{\mathbf{a}_3},$ and $\color{#00FF00}{\mathbf{b}}$ are linear combinations of $\color{green}{\mathbf{a}_1},$ $\color{green}{\mathbf{a}_2}.$ At this point you can solve items (i) and (iii) in Problem in the next item. After you solved item (iii), you can reconstruct (ii) But, you will have more information to answer solve (ii) as we learn more about RREF. An important note: The Problem in the next item will be on the final assignment. So, solving it early, and ask for clarifications if there is something not clear, assures success.
The content of Section 1.5 is very useful for the Problem below.
-
Problem
Consider the vectors $\color{green}{\mathbf{a}_1},$ $\color{green}{\mathbf{a}_2},$ $\color{green}{\mathbf{a}_3},$ and $\color{#00FF00}{\mathbf{b}}$ in $\mathbb{R}^2$ as shown in the picture below.
- Is the vector equation \[ \color{red}{x_1} \color{green}{\mathbf{a}_1} + \color{red}{x_2} \color{green}{\mathbf{a}_2} + \color{red}{x_3} \color{green}{\mathbf{a}_3} = \color{#00FF00}{\mathbf{b}} \] consistent or inconsistent? Explain your reasoning.
- Find the reduced row echelon form of the augmented matrix \[ \left[\begin{array}{ccc|c} \color{green}{\mathbf{a}_1} & \color{green}{\mathbf{a}_2} & \color{green}{\mathbf{a}_3} & \color{#00FF00}{\mathbf{b}} \end{array} \right]. \]
- Find the solution set of the vector equation \[ \color{red}{x_1} \color{green}{\mathbf{a}_1} + \color{red}{x_2} \color{green}{\mathbf{a}_2} + \color{red}{x_3} \color{green}{\mathbf{a}_3} = \color{#00FF00}{\mathbf{b}} \] and represent the solution set in parametric vector form.
- We finished Section 1.4 and started Section 1.5. Suggested problems for Section 1.4: 1, 5, 13, 14, 15, 16,17-20, 21, 22, 23, 24, 25, 26, 32, 34, 35, 36 and for Section 1.5: 1, 3, 5, 6, 7, 9, 11, 12, 13-16, 19, 21, 23, 24, 26, 29, 32, 35, 37-40.
- Notice that Problems 25 26, 27, and 28 in Section 1.1 are related to Theorem 4 in Section 1.4. These are interesting deep problems. Also notice that how these problems are related to the concept of span. I wrote about this in an item on October 3; the box starting with "Find a relationship between the coordinates ..."
- On Friday, I illustrated content of Sections 1.4 and 1.5 on the following modification of an example that we did before: \begin{alignat*}{5} \require{amsmath} 3 \color{red}{x_{1}} & + & 0 \color{red}{x_{2}} & + & (-1) \color{red}{x_{3}} & + & 1 \color{red}{x_{4}} & = & -2& \\ 1 \color{red}{x_{1}} & + & 1 \color{red}{x_{2}} & + & (-2) \color{red}{x_{3}} & + & 2 \color{red}{x_{4}} & = & 3& \\ 2 \color{red}{x_{1}} & + & (-1) \color{red}{x_{2}} & + & 1 \color{red}{x_{3}} & + & 3 \color{red}{x_{4}} & = & 8 & \\ \end{alignat*} Let us rewrite the above system as a vector equation: \begin{equation*} \color{red}{x_{1}} \left[\! \begin{array}{r} 3 \\ 1\\ 2 \end{array} \!\right] + \color{red}{x_{2}} \left[\! \begin{array}{r} 0 \\1\\ -1 \end{array} \!\right] + \color{red}{x_{3}} \left[\! \begin{array}{r} -1 \\-2\\ 1 \end{array} \!\right] + \color{red}{x_{4}} \left[\! \begin{array}{r} 1 \\ 2\\ 3 \end{array} \!\right] = \left[\! \begin{array}{r} -2 \\ 3 \\ 8 \end{array} \!\right] . \end{equation*} Let us rewrite the above vector equation as a matrix equation: \begin{equation*} \left[\!\begin{array}{rrrr} 3 & 0 & -1 & 1 \\ 1 & 1 & -2 & 2 \\ 2 & -1 & 1 & 3 \end{array}\! \right] \left[\! \begin{array}{c} \color{red}{x_{1}} \\ \color{red}{x_{2}}\\ \color{red}{x_{3}} \\ \color{red}{x_{4}} \end{array} \!\right] = \left[\! \begin{array}{r} -2 \\ 3 \\ 8 \end{array} \!\right] . \end{equation*} To solve any of the any of the above, the system, the vector equation, the matrix equation we form the augmented matrix and row reduce it: \begin{equation*} \left[\!\begin{array}{rrrr|r} 3 & 0 & -1 & 1 & -2 \\ 1 & 1 & -2 & 2 & 3 \\ 2 & -1 & 1 & 3 & 8 \end{array}\! \right] \ \ \sim \quad \cdots \quad \sim \ \ \left[\!\begin{array}{rrrr|r} 1 & 0 & -\frac{1}{3} & 0 & -\frac{7}{4} \\ 0 & 1 & -\frac{5}{3} & 0 & -\frac{7}{4} \\ 0 & 0 & 0 & 1 & \frac{13}{4} \end{array}\! \right] \end{equation*} Thus, the solution exists since the augmented column is not a pivot column. There is one free variable, so \(\color{red}{x_{3}} = s\) is free. To find the solution, we write the system corresponding to the RREF: \begin{alignat*}{5} \require{amsmath} 1 \color{red}{x_{1}} & + & 0 \color{red}{x_{2}} & + & (-\tfrac{1}{3}) \color{red}{x_{3}} & + & 0 \color{red}{x_{4}} & = & -\tfrac{7}{4}& \\ 0 \color{red}{x_{1}} & + & 1 \color{red}{x_{2}} & + & (-\tfrac{5}{3}) \color{red}{x_{3}} & + & 0 \color{red}{x_{4}} & = & -\tfrac{7}{4}& \\ 0 \color{red}{x_{1}} & + & 0 \color{red}{x_{2}} & + & 0 \color{red}{x_{3}} & + & 1 \color{red}{x_{4}} & = & \tfrac{13}{4} & \\ \end{alignat*} Hence, the solution is \begin{alignat*}{3} \color{red}{x_{1}} & = & -\tfrac{7}{4} & + & \tfrac{1}{3} s & \\ \color{red}{x_{2}} & = & -\tfrac{7}{4} & + & \tfrac{5}{3} s & \\ \color{red}{x_{3}} & = & 0 & + & 1 s & \\ \color{red}{x_{4}} & = & \tfrac{13}{4} & + & 0 s & \end{alignat*} where \(s\) is any real number. The simplest way to write this solution is in parametric vector form: \[ \color{red}{\mathbf{x}} = \left[\! \begin{array}{r} -\tfrac{7}{4} \\ -\tfrac{7}{4} \\ 0 \\ \tfrac{13}{4} \end{array} \!\right] + \left[\! \begin{array}{r} \tfrac{1}{3} s \\ \tfrac{5}{3} s \\ 1 s \\ 0 s \end{array} \!\right] = \frac{1}{4} \left[\! \begin{array}{r} - 7 \\ - 7 \\ 0 \\ 13 \end{array} \!\right] + s \frac{1}{3} \left[\! \begin{array}{r} 1 \\ 5 \\ 3 \\ 0 \end{array} \!\right] = \mathbf{p} + s \mkern 3mu \mathbf{v}, \] where we set \[ \mathbf{p} = \frac{1}{4} \left[\! \begin{array}{r} - 7 \\ - 7 \\ 0 \\ 13 \end{array} \!\right] \quad \text{and} \quad \mathbf{v} = \frac{1}{3} \left[\! \begin{array}{r} 1 \\ 5 \\ 3 \\ 0 \end{array} \!\right]. \]
- I used Wolfram Mathematica to help me with the row reduction in the preceding item.
- Computer algebra system Wolfram Mathematica will be very useful in this class. To get started with Mathematica see my Mathematica page. Please watch the videos that are on my Mathematica page. Watching the movies is very helpful to get started with Mathematica efficiently! Mathematica is available in the computer labs in BH 215, HH 233 and in the Math Center BH 209/211A.
- In class I created a small Mathematica notebook 20241004.nb in which I performed the above row reduction. I also created 20241004.pdf, for you to enjoy this file without access to Mathematica.
- Today we discussed Section 1.3: Vector Equations. Suggested problems for Section 1.3: 1, 5, 9, 15, 17, 18, 19, 21-25, 32. We are a liitle late. We did mention how Section 1.3: The Matrix Equation \(A \mathbf{x} = \mathbf{b}\) ties into this. More about it tomorrow.
- To internalize algebraic operations with vectors it is useful to draw pictures in $\mathbb{R}^2$ (the Cartesian plane) and $\mathbb{R}^3$ (the Euclidean space). That is what I will do below.
-
Consider two specific vectors in $\mathbb{R}^3$
\[
\bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1
\end{array} \!\right]} \quad \text{and} \quad \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2
\end{array} \!\right]}
\]
as given in the picture below:
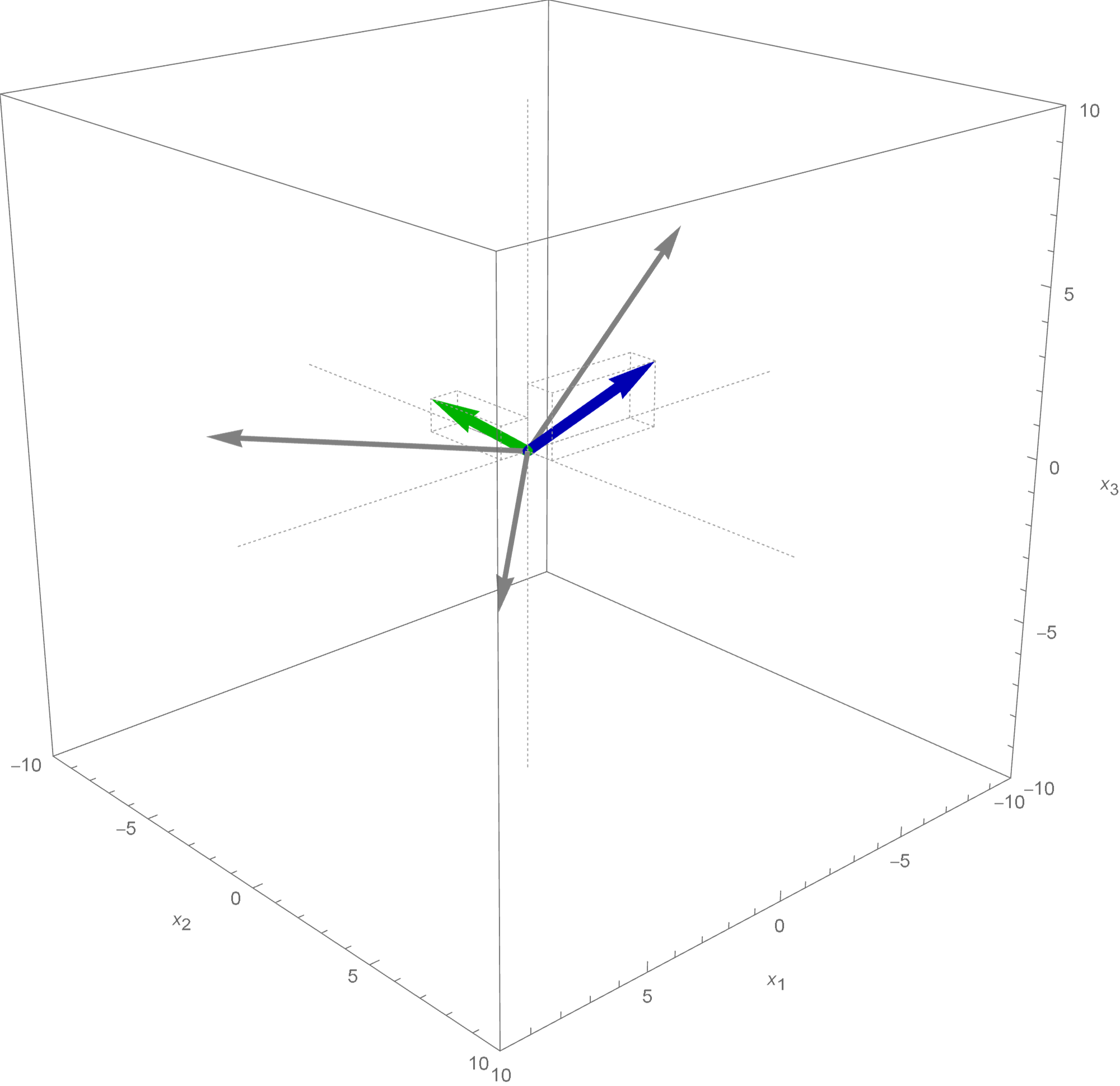
- We ask the question: Is the vector $\left[\! \begin{array}{r} 2 \\ 1 \\ -4 \end{array} \!\right]$ in the span of the vectors $\bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1 \end{array} \!\right]}$ and $\bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2 \end{array} \!\right]}$? Or, the same question in mathematical notation: Is the following statement true \[ \left[\begin{array}{r} 2 \\ 1 \\ -4 \end{array} \right] \in \operatorname{Span}\left\{ \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1 \end{array} \!\right]}, \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2 \end{array} \!\right]} \right\}? \] And two more questions: Is the following statement true \[ \left[\begin{array}{r} 6 \\ -7 \\ 0 \end{array} \right] \in \operatorname{Span}\left\{ \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1 \end{array} \!\right]}, \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2 \end{array} \!\right]} \right\}? \qquad \left[\begin{array}{r} -7 \\ -1 \\ 5 \end{array} \right] \in \operatorname{Span}\left\{ \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1 \end{array} \!\right]}, \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2 \end{array} \!\right]} \right\}? \]
-
Really interesting aspect of linear algebra is that these three questions are just vector equations in disguise. In fact, we are asking if the following vector equations have solutions (are consistent):
\[
x_1 \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1
\end{array} \!\right]} +x_2 \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2
\end{array} \!\right]} = \left[\begin{array}{r} 2 \\ 1 \\ -4
\end{array} \right], \quad
x_1 \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1
\end{array} \!\right]} +x_2 \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2
\end{array} \!\right]} = \left[\begin{array}{r} 6 \\ -7 \\ 0
\end{array} \right], \quad
x_1 \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1
\end{array} \!\right]} +x_2 \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2
\end{array} \!\right]} = \left[\begin{array}{r} -7 \\ -1 \\ 5
\end{array} \right].
\]
In turn, these vector equations are in fact systems of linear equations, like we did on the first day of classes:
These systems are solved by row reducing the augmented matrices. But, this is huge, we can do three row reductions in one go: \begin{align*} \left[\!\begin{array}{rr|rrr} 1 & -4 & 2 & 6& -7 \\ -3 & 1 & 1 & -7& -1 \\ 1 & 2 & -4& 0& 5 \end{array}\! \right] & \sim \left[\!\begin{array}{rr|rrr} 1 & -4 & 2 & 6& -7 \\ 0 & -11 & 7 & 11 & -22 \\ 0 & 6 & -6& -6 & 12 \end{array}\! \right] \\ & \sim \left[\!\begin{array}{rr|rrr} 1 & -4 & 2 & 6& -7 \\ 0 & 1 & -\frac{7}{11} & -1 & 2 \\ 0 & 1 & -1& -1 & 2 \end{array}\! \right] \\ & \sim \left[\!\begin{array}{rr|rrr} 1 & -4 & 2 & 6& -7 \\ 0 & 1 & -\frac{7}{11} & -1 & 2 \\ 0 & 0 & -\frac{4}{11}& 0 & 0 \end{array}\! \right] \\ & \sim \left[\!\begin{array}{rr|rrr} 1 & -4 & 2 & 6& -7 \\ 0 & 1 & -\frac{7}{11} & -1 & 2 \\ 0 & 0 & 1 & 0 & 0 \end{array}\! \right] \\ & \sim \left[\!\begin{array}{rr|rrr} 1 & -4 & 0 & 6& -7 \\ 0 & 1 & 0 & -1 & 2 \\ 0 & 0 & 1 & 0 & 0 \end{array}\! \right] \\ & \sim \left[\!\begin{array}{rr|rrr} 1 & 0 & 0 & 2 & 1 \\ 0 & 1 & 0 & -1 & 2 \\ 0 & 0 & 1 & 0 & 0 \end{array}\! \right] \qquad \text{this matrix is in RREF} \end{align*}System 1 Systems 2 Systems 3 \begin{alignat*}{8} &x_1 & & - 4 &x_2 & &=&& 2\\ -3 &x_1 & & + &x_2 & & =&& 1 \\ &x_1 & & + 2 &x_2 & & =&& -4 \end{alignat*} \begin{alignat*}{8} &x_1 & & - 4 &x_2 & &=&& 6\\ -3 &x_1 & & + &x_2 & & =&&-7 \\ &x_1 & & + 2 &x_2 & & =&& 0 \end{alignat*} \begin{alignat*}{8} &x_1 & & - 4 &x_2 & &=&& -7\\ -3 &x_1 & & + &x_2 & & =&& -1 \\ &x_1 & & + 2 &x_2 & & =&& 5 \end{alignat*} -
Conclusions:
- Since the the first augmented column of the RREF is a pivot column and this augmented column corresponds to System 1, we conclude that System 1 is inconsistent. Therefore, it is true that \[ \left[\begin{array}{r} 2 \\ 1 \\ -4 \end{array} \right] \not\in \operatorname{Span}\left\{ \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1 \end{array} \!\right]}, \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2 \end{array} \!\right]} \right\}. \]
- Since the second augmented column of the RREF is not a pivot column and this augmented column corresponds to System 2, we conclude that System 2 is consistent. From the RREF we can read even more \[ \left[\begin{array}{r} 6 \\ -7 \\ 0 \end{array} \right] = 2 \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1 \end{array} \!\right]} - \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2 \end{array} \!\right]}. \] Therefore, it is true that \[ \left[\begin{array}{r} 6 \\ -7 \\ 0 \end{array} \right] \in \operatorname{Span}\left\{ \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1 \end{array} \!\right]}, \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2 \end{array} \!\right]} \right\}. \]
- Since the third augmented column of the RREF is not a pivot column and this augmented column corresponds to System 3, we conclude that System 3 is consistent. From the RREF we can read even more \[ \left[\begin{array}{r} -7 \\ -1 \\ 5 \end{array} \right] = \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1 \end{array} \!\right]} + 2 \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2 \end{array} \!\right]}. \] Therefore, it is true that \[ \left[\begin{array}{r} -7 \\ -1 \\ 5 \end{array} \right] \in \operatorname{Span}\left\{ \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1 \end{array} \!\right]}, \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2 \end{array} \!\right]} \right\}. \]
The questions which are answered in the previous items can be answered by stating a universal problem:
-
The picture below is an attempt to illustrate
\[
\operatorname{Span}\left\{ \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1
\end{array} \!\right]}, \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2
\end{array} \!\right]} \right\}
\]
geometrically. In the picture below this span is represented by the yellow translucent plane in $\mathbb{R}^3$. In this plane I placed a grid imposed by the green and the blue vector. To indicate that there are many vectors in this plane, I placed nine gray vectors in the picture all of which are in the span.
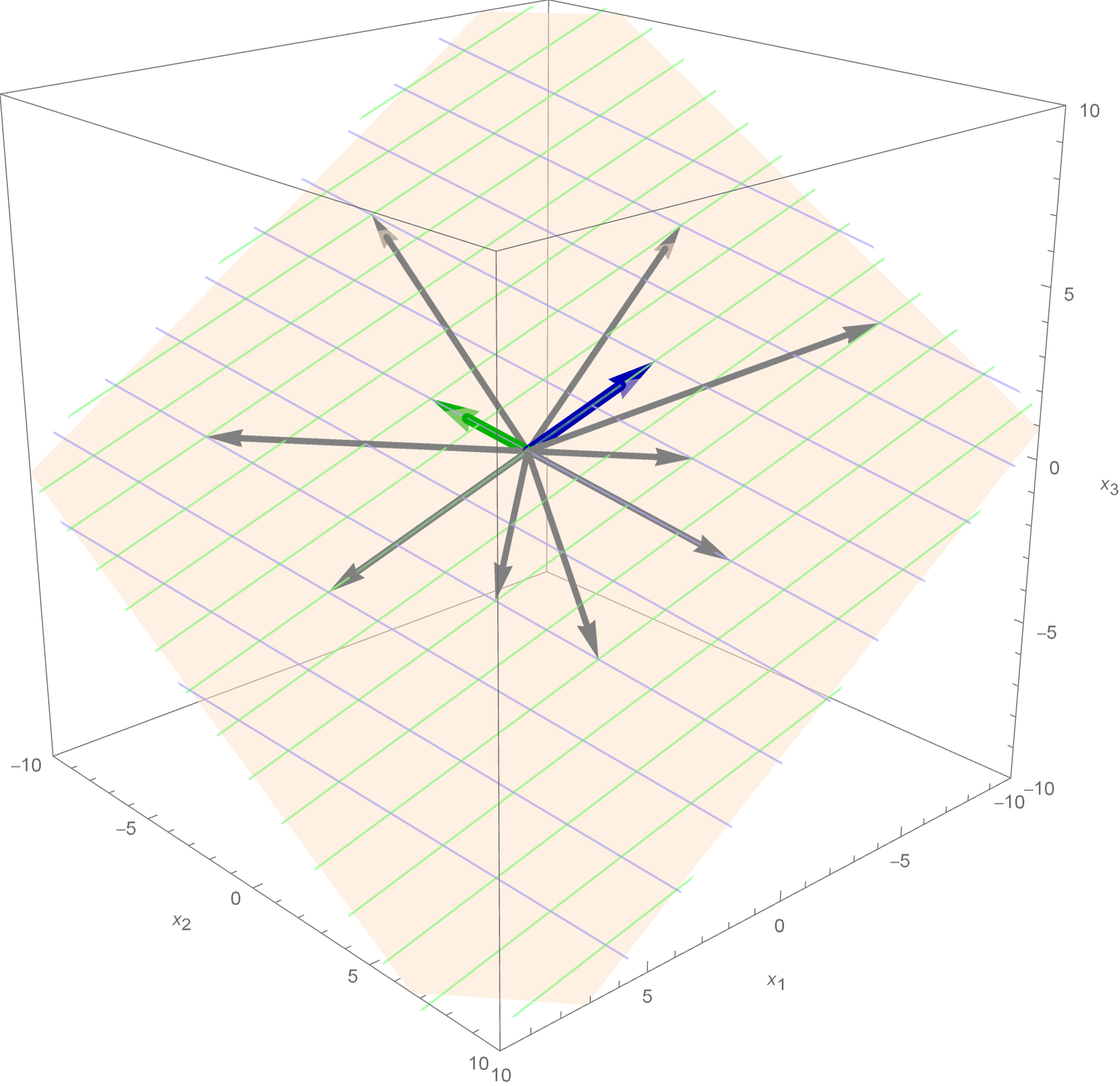
-
Above, we focused primarily on practical calculations. However, the key takeaway from today's presentation is that three concepts—a system of linear equations, a linear vector equation, and a matrix equation—are mathematically equivalent.
In the following items, I will provide all the details behind the reasoning for this claim.
-
Let \( m \) and \( n \) be positive integers. Using set notation, we write: \( m, n \in \mathbb{N} \). This is read as: \( m \) and \( n \) are elements of the set of positive integers.
- Linear System. Consider a linear system with $m$ linear equations each with $n$ unknowns. A linear system with $m$ equations each with $n$ unknowns can be written as follows: \begin{equation} \label{eq:LS} \tag{LS} \require{amsmath} \begin{array}{ccccccccc} \color{green}{a_{11}} \color{red}{x_{1}} & + & \color{green}{a_{12}} \color{red}{x_{2}} & + & \cdots & + & \color{green}{a_{1n}} \color{red}{x_{n}} & = & \color{green}{b_{1}} \\ \color{green}{a_{21}} \color{red}{x_{1}} & + & \color{green}{a_{22}} \color{red}{x_{2}} & + & \cdots & + & \color{green}{a_{2n}} \color{red}{x_{n}} & = & \color{green}{b_{2}} \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ \color{green}{a_{m1}} \color{red}{x_{1}} & + & \color{green}{a_{m2}} \color{red}{x_{2}} & + & \cdots & + & \color{green}{a_{mn}} \color{red}{x_{n}} & = & \color{green}{b_{m}} \end{array} \end{equation}
- Steps towards Vector Equation. These \(m\) equations we can write as one vector equation \begin{equation*} \require{amsmath} \left[\!\begin{array}{c} \color{green}{a_{11}} \color{red}{x_{1}}+ \color{green}{a_{12}} \color{red}{x_{2}} + \cdots + \color{green}{a_{1n}} \color{red}{x_{n}} \\ \color{green}{a_{21}} \color{red}{x_{1}} + \color{green}{a_{22}} \color{red}{x_{2}} + \cdots + \color{green}{a_{2n}} \color{red}{x_{n}} \\ \vdots \\ \color{green}{a_{m1}} \color{red}{x_{1}} + \color{green}{a_{m2}} \color{red}{x_{2}} + \cdots + \color{green}{a_{mn}} \color{red}{x_{n}} \end{array} \!\right] = \left[\! \begin{array}{c} \color{green}{b_{1}} \\ \color{green}{b_{2}} \\ \vdots \\ \color{green}{b_{m}} \end{array} \!\right] \end{equation*} Using the definition of the vector addition, the vector on the left-hand side of the preceding equation can be written as a sum of \(n\) vectors: \begin{equation*} \left[\!\begin{array}{c} \color{red}{x_{1}} \color{green}{a_{11}} \\ \color{red}{x_{1}} \color{green}{a_{21}} \\ \vdots \\ \color{red}{x_{1}}\color{green}{a_{m1}} \end{array} \!\right] + \left[\!\begin{array}{c} \color{red}{x_{2}} \color{green}{a_{12}} \\ \color{red}{x_{2}} \color{green}{a_{22}} \\ \vdots \\ \color{red}{x_{2}}\color{green}{a_{m2}} \end{array}\!\right] + \cdots + \left[\!\begin{array}{c} \color{red}{x_{n}} \color{green}{a_{1n}} \\ \color{red}{x_{n}} \color{green}{a_{2n}} \\ \vdots \\ \color{red}{x_{n}}\color{green}{a_{mn}} \end{array}\!\right] = \left[\! \begin{array}{c} \color{green}{b_{1}} \\ \color{green}{b_{2}} \\ \vdots \\ \color{green}{b_{m}} \end{array}\!\right] \end{equation*} Using the definition of vector scaling, we can factor out the common red scalar in each of the \(n\) vector on the left-hand side of the preceding equation: \begin{equation*} \color{red}{x_{1}} \left[\! \begin{array}{c} \color{green}{a_{11}} \\ \color{green}{a_{21}} \\ \vdots \\ \color{green}{a_{m1}} \end{array} \!\right] + \color{red}{x_{2}} \left[\! \begin{array}{c} \color{green}{a_{12}} \\ \color{green}{a_{22}} \\ \vdots \\ \color{green}{a_{m2}} \end{array} \!\right] + \cdots + \color{red}{x_{n}} \left[\! \begin{array}{c} \color{green}{a_{1n}} \\ \color{green}{a_{2n}} \\ \vdots \\ \color{green}{a_{mn}} \end{array} \!\right] = \left[\! \begin{array}{c} \color{green}{b_{1}} \\ \color{green}{b_{2}} \\ \vdots \\ \color{green}{b_{m}} \end{array} \!\right] \end{equation*}
- Vector Equation.Now we introduce short boldface names for \(n+1\) vectors in the space \(\mathbb{R}^m\): \begin{equation*} \color{green}{\mathbf{a}_1} = \left[\! \begin{array}{c} \color{green}{a_{11}} \\ \color{green}{a_{21}} \\ \vdots \\ \color{green}{a_{m1}} \end{array} \!\right], \quad \color{green}{\mathbf{a}_2} = \left[\! \begin{array}{c} \color{green}{a_{12}} \\ \color{green}{a_{22}} \\ \vdots \\ \color{green}{a_{m2}} \end{array} \!\right], \quad \cdots , \quad \color{green}{\mathbf{a}_n} = \left[\! \begin{array}{c} \color{green}{a_{1n}} \\ \color{green}{a_{2n}} \\ \vdots \\ \color{green}{a_{mn}} \end{array} \!\right], \quad \color{green}{\mathbf{b}} = \left[\! \begin{array}{c} \color{green}{b_{1}} \\ \color{green}{b_{2}} \\ \vdots \\ \color{green}{b_{m}} \end{array} \!\right]. \end{equation*} Notice that the vectors in the preceding displayed expression are vectors in \(\mathbb{R}^m\). Using these vectors we can rewrite the system \eqref{eq:LS} as one vector equation: \begin{equation} \label{eq:VE} \tag{VE} \color{red}{x_{1}} \color{green}{\mathbf{a}_1} + \color{red}{x_{2}} \color{green}{\mathbf{a}_2} + \cdots + \color{red}{x_{n}} \color{green}{\mathbf{a}_n} = \color{green}{\mathbf{b}}. \end{equation}
- Matrix Equation. One more step: We introduce a \(m\times n\) matrix, call it \(\color{green}{A}\), whose columns are the vectors \(\color{green}{\mathbf{a}_1}, \color{green}{\mathbf{a}_2}, \ldots, \color{green}{\mathbf{a}_n}\), which, as we know are vectors in \(\mathbb{R}^m\): \begin{equation*} \color{green}{A} = \left[\!\begin{array}{cccc} \color{green}{a_{11}} & \color{green}{a_{12}} & \cdots & \color{green}{a_{1n}} \\ \color{green}{a_{21}} & \color{green}{a_{22}} & \cdots & \color{green}{a_{2n}} \\ \vdots & \vdots & \ddots & \vdots \\ \color{green}{a_{m1}} & \color{green}{a_{m2}} & \cdots & \color{green}{a_{mn}} \\ \end{array}\! \right] = \bigl[ \begin{array}{cccc} \color{green}{\mathbf{a}_1} & \color{green}{\mathbf{a}_2} & \cdots & \color{green}{\mathbf{a}_n} \end{array} \bigr] \end{equation*} We also introduce a red vector with \(n\) components, that is a vector in \(\mathbb{R}^n\), which consists of the unknowns \(\color{red}{x_{1}}, \color{red}{x_{2}}, \ldots, \color{red}{x_{n}}\): \begin{equation*} \color{red}{\mathbf{x}} = \left[\! \begin{array}{c} \color{red}{x_{1}} \\ \color{red}{x_{2}} \\ \vdots \\ \color{red}{x_{n}} \end{array} \!\right]. \end{equation*} Using the definition of matrix-vector multiplication we can write the vector equation \eqref{eq:VE} as a matrix equation \begin{equation} \label{eq:ME} \tag{ME} \color{green}{A} \color{red}{\mathbf{x}} = \color{green}{\mathbf{b}}. \end{equation} The connection between the vector equation \eqref{eq:VE} and the matrix equation \eqref{eq:ME} is the definition of the matrix-vector multiplication: the product of the matrix \begin{equation*} \color{green}{A} = \left[\!\begin{array}{cccc} \color{green}{a_{11}} & \color{green}{a_{12}} & \cdots & \color{green}{a_{1n}} \\ \color{green}{a_{21}} & \color{green}{a_{22}} & \cdots & \color{green}{a_{2n}} \\ \vdots & \vdots & \ddots & \vdots \\ \color{green}{a_{m1}} & \color{green}{a_{m2}} & \cdots & \color{green}{a_{mn}} \\ \end{array}\! \right] = \bigl[ \begin{array}{cccc} \color{green}{\mathbf{a}_1} & \color{green}{\mathbf{a}_2} & \cdots & \color{green}{\mathbf{a}_n} \end{array} \bigr] \end{equation*} and the vector \begin{equation*} \color{red}{\mathbf{x}} = \left[\! \begin{array}{c} \color{red}{x_{1}} \\ \color{red}{x_{2}} \\ \vdots \\ \color{red}{x_{n}} \end{array} \!\right] \end{equation*} equals the linear combination of the columns of \(\color{green}{A} = \bigl[ \begin{array}{cccc} \color{green}{\mathbf{a}_1} & \color{green}{\mathbf{a}_2} & \cdots & \color{green}{\mathbf{a}_n} \end{array} \bigr]\) which are scaled by scalars \(\color{red}{x_{1}}, \color{red}{x_{2}}, \ldots, \color{red}{x_{n}}\). That is \begin{equation*} \require{amsmath} \require{graphicx} \color{green}{A} \color{red}{\mathbf{x}} = \bigl[ \begin{array}{cccc} \color{green}{\mathbf{a}_1} & \color{green}{\mathbf{a}_2} & \cdots & \color{green}{\mathbf{a}_n} \end{array} \bigr] \left[\! \begin{array}{c} \color{red}{x_{1}} \\ \color{red}{x_{2}} \\ \vdots \\ \color{red}{x_{n}} \end{array} \!\right] \overset{\text{definition}}{=\mkern -1.5mu=\mkern -1.5mu=\mkern -1.5mu=} \ \color{red}{x_{1}} \color{green}{\mathbf{a}_1} + \color{red}{x_{2}} \color{green}{\mathbf{a}_2} + \cdot + \color{red}{x_{n}} \color{green}{\mathbf{a}_n}. \end{equation*}
-
Finally: To solve any of the three equations: the linear system in \eqref{eq:LS}, the linear vector equation \eqref{eq:VE}, or the matrix equation \eqref{eq:ME}, we form the augmented matrix:
\begin{equation} \label{eq:AM} \tag{AM}
\left[\!\begin{array}{cccc|c}
\color{green}{a_{11}} & \color{green}{a_{12}} & \cdots & \color{green}{a_{1n}} & \color{green}{b_{1}} \\
\color{green}{a_{21}} & \color{green}{a_{22}} & \cdots & \color{green}{a_{2n}} & \color{green}{b_{2}} \\
\vdots & \vdots & \ddots & \vdots & \vdots \\
\color{green}{a_{m1}} & \color{green}{a_{m2}} & \cdots & \color{green}{a_{mn}} & \color{green}{b_{m}} \\
\end{array}\! \right]
\end{equation}
and row reduce it.
It is important to note that the above augmented matrix \eqref{eq:AM} is completely green matrix with $m$ rows and $n+1$ columns. The last column is the augmented column.
It is important to note that the above augmented matrix \eqref{eq:AM} is completely green matrix with $m$ rows and $n+1$ columns. The last column is the augmented column.
Find a relationship between the coordinates $b_1,$ $b_2$ and $b_3$ such that the following relationship is satisfied:
\[
\left[\begin{array}{c} b_1 \\ b_2 \\ b_3
\end{array} \right] \in \operatorname{Span}\left\{ \bbox[#50FF50]{\left[\! \begin{array}{r} 1 \\ -3 \\ 1
\end{array} \!\right]}, \bbox[#8080FF]{\left[\! \begin{array}{r} -4 \\ 1 \\ 2
\end{array} \!\right]} \right\}.
\]
- We have moved on to Section 1.3: Vector Equations, but since the Reduced Row Echelon Form of a matrix is a key concept introduced in this class, I will summarize its important aspects in today's post.
- In the items below I will define the Reduced Row Echelon Form (RREF) of a matrix.
- A useful link is Wikipedia's Row echelon form.
- A matrix whose all entries are zero is called a zero matrix. A row of a matrix is said to be a zero row if all the entries in that row are zero. The leftmost nonzero entry of a nonzero row is called the leading entry of a row. The zeros preceding the leading entry are called the leading zeros of a row. All entries of a zero row are leading zeros.
- This is a restatement of Wikipidia's definition of reduced row echelon form:
Each zero matrix is in Reduced Row Echelon Form. A nonzero matrix is in Reduced Row Echelon Form if it satisfies the following three conditions:
- Each nonzero row has strictly more leading zeros then the row above it.
- The leading entry of each nonzero row is equal to $1$.
- The leading entry of each nonzero row is the only nonzero entry in its column.
- Some consequences of the definition of Reduced Row Echelon Form in the preceding item are:
- If a nonzero matrix is in Reduced Row Echelon Form, then all its zero rows are at the bottom.
- If a nonzero matrix is in Reduced Row Echelon Form, then its first row has the fewest leading zeros. The second row has more leading zeros than the first row, the third row has more leading zeros than the second row, and so on, ...
- Let $m, n, k \in \mathbb{N}.$ If a nonzero $m\!\times\!n$ matrix is in Reduced Row Echelon Form and it has $k$ leading entries, then its columns containing the leading entries are the first $k$ columns of the identity matrix $I_m$ in exactly the same order as in the identity matrix $I_m$. In other words, the pivot columns are the first $k$ columns of the identity matrix $I_m$.
-
To illustrate the definition of the reduced row echelon form I made a picture of a $12\times 25$ matrix (that is a matrix with $12$ rows and $25$ columns which is in reduced row echelon form. To emphasize the role of the leading zeros, I colored them blue. To emphasize the role of leading $1$s, I colored them green. I also colored in green the each pivot column. The entries of the matrix that are not specifically written as $0$s or $1$s can be any real numbers. Please notice how blue leading zeros form steps which climb from right to left. Also notice that each stair hosts a pivot position, that is the leading $1$ in a nonzero row.
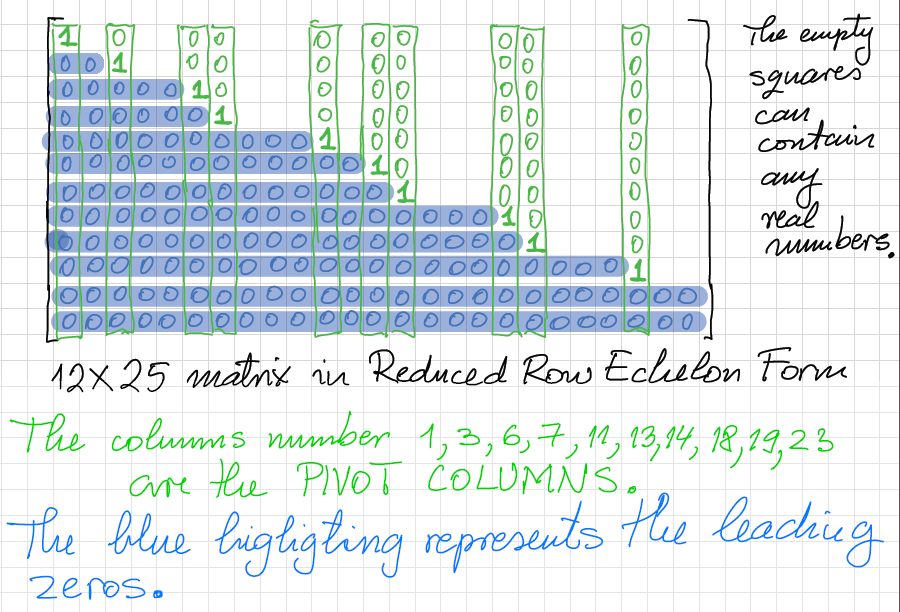
- A very good exercise in understanding RREF (reduced row echelon form) is to write down all $2\!\times\!3$ matrices which are in RREF. There are seven of them. Below I list the matrix with no pivot columns, then all matrices with one pivot column, then the matrices with two pivot columns. Those are all possibilities since each pivot column has pivot position occupied by the leading entry which needs its own row and we are studying matrices with only two rows. In the matrices below stars ($*$) stand for arbitrary real numbers. \begin{align*} & \begin{bmatrix} 0 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix}, \\ & \begin{bmatrix} 0 & 0 & 1 \\ 0 & 0 & 0 \end{bmatrix},\quad \begin{bmatrix} 0 & 1 & * \\ 0 & 0 & 0 \end{bmatrix},\quad \begin{bmatrix} 1 & * & * \\ 0 & 0 & 0 \end{bmatrix},\\ & \begin{bmatrix} 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix}, \quad \begin{bmatrix} 1 & * & 0 \\ 0 & 0 & 1 \end{bmatrix}, \quad \begin{bmatrix} 1 & 0 & * \\ 0 & 1 & * \end{bmatrix}, \quad \end{align*}
- Here are all possible $3\!\times\!4$ matrices in RREF (reduced row echelon form). There are fifteen of them. \begin{align*} & \begin{bmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix}, \\ & \begin{bmatrix} 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix}, \ \begin{bmatrix} 0 & 0 & 1 & * \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix},\ \begin{bmatrix} 0 & 1 & * & * \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix}, \ \begin{bmatrix} 1 & * & * & * \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix},\\ & \begin{bmatrix} 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 \end{bmatrix}, \ \begin{bmatrix} 0 & 1 & * & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 \end{bmatrix}, \ \begin{bmatrix} 1 & * & * & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 \end{bmatrix}, \ \begin{bmatrix} 0 & 1 & 0 & * \\ 0 & 0 & 1 & * \\ 0 & 0 & 0 & 0 \end{bmatrix}, \ \begin{bmatrix} 1 & * & 0 & * \\ 0 & 0 & 1 & * \\ 0 & 0 & 0 & 0 \end{bmatrix}, \ \begin{bmatrix} 1 & 0 & * & * \\ 0 & 1 & * & * \\ 0 & 0 & 0 & 0 \end{bmatrix}, \\ & \begin{bmatrix} 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}, \ \begin{bmatrix} 1 & * & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix},\ \begin{bmatrix} 1 & 0 & * & 0 \\ 0 & 1 & * & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}, \ \begin{bmatrix} 1 & 0 & 0 & * \\ 0 & 1 & 0 & * \\ 0 & 0 & 1 & * \end{bmatrix}, \end{align*}
- Here are all possible $4\!\times\!3$ matrices in RREF (reduced row echelon form). There are eight of them. \begin{align*} & \begin{bmatrix} 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix}, \\ & \begin{bmatrix} 0 & 0 & 1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix}, \quad \begin{bmatrix} 0 & 1 & * \\ 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix},\quad \begin{bmatrix} 1 & * & * \\ 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix}, \\ & \begin{bmatrix} 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix}, \quad \begin{bmatrix} 1 & * & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix}, \quad \begin{bmatrix} 1 & 0 & * \\ 0 & 1 & * \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{bmatrix}, \\ & \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \end{bmatrix}. \end{align*}
- Notice that in all the matrices listed in the preceding item the bottom row is the zero row. By removing that zero row we would get all possible $3\!\times\!3$ matrices in RREF (reduced row echelon form). Thus, there is eight different types of $3\!\times\!3$ matrices in RREF (reduced row echelon form). This is true in general: If $m\geq n$, than the number of different types of $m\!\times\!n$ matrices in RREF is the same as the number of different types of $n\!\times\!n$ matrices in RREF.
- Another good exercise is to think of the above matrices as augmented matrices of systems of equations and state for each corresponding system whether it has: No Solutions (NS), Unique Solution (US), Infinitely Many Solutions (MS).
- Another interesting exercise, but for Math 309, is to calculate how many $m\!\times\!n$ matrices are in RREF. Just for the record: Let $k$ be a nonnegative integer and let $m, n$ be positive integers such that $k \leq m \leq n.$ It turns out that there are exactly \[ \displaystyle \binom{n}{k} = \frac{n!}{k!(n-k)!} \] matrices of size $m\!\times\!n$ with $k$ pivots (leading $1$s). The symbol $\displaystyle \binom{n}{k}$ is the standard notation for the binomial coefficient $n$-choose-$k$. Since an arbitrary $m\!\times\!n$ matrix can have $k \in \{0,1,\ldots,m\}$ pivots, it follows that the number of possible RREF types for an $m\!\times\!n$ matrix is \[ \sum_{k=0}^m \binom{n}{k}. \] For example, with $m=3$ and $n=4$, as seen above, there are \[ \binom{4}{0} + \binom{4}{1} + \binom{4}{2} + \binom{4}{3} = 1 + 4 + 6 + 4 = 15. \] possible RREF types of matrices. It is interesting to observe that for an $n\!\times\!n$ matrix there are \[ \sum_{k=0}^n \binom{n}{k} = \binom{n}{0} + \binom{n}{1} + \cdots + \binom{n}{n-1} + \binom{n}{n} = 2^n \] possible RREF types. If you take Math 309 you will understand the background of these formulas.
- In conclusion, for an $m\!\times\!n$ matrix with $m\lt n$ there are \[ \sum_{k=0}^m \binom{n}{k} \] possible RREF types and if $m \geq n$ there are \[ 2^n \] possible RREF types.
- This post is lengthy because it repeats all the arguments from last week's classes. Please read it carefully, especially the conclusion. I've also illustrated the equations with pictures, using the fact that that the graph of a linear equation in three variables is a plane in three-dimensional space \(\mathbb{R}^3\). If you're not yet familiar with this setting, please revisit this post when we cover vectors in \(\mathbb{R}^3\). Most of the post is independent of the geometric illustrations.
- Read Section 1.1 and Section 1.2. Assigned problems for Section 1.1: 3, 6, 7, 5, 9, 11,12, 16, 17, 18, 21, 22, 23, 24, 25, 27, 31, 33, 34. Assigned problems for Section 1.2: 3, 5, 6, 7, 8, 12, 17-31.
-
Today we solved the following system of linear equations:
\begin{alignat*}{8}
&x_1 & & + &&x_2 & & - &&2 &&x_3 &&= -&&5\\
2 &x_1 & & - &&x_2 & & + && &&x_3 &&= &&8 \\
3 &x_1 & & && & & - && && x_3 &&= &&3
\end{alignat*}
I will give all the details of this solution and illustrate wth pictures. This system is solved by row reducing its augmented matrix:
\begin{align*}
\left[\!\begin{array}{crr|r}
1 & 1 & -2 & -5 \\
2 & -1 & 1 & 8 \\
3 & 0 & -1 & 3
\end{array}\! \right] & \sim
\left[\!\begin{array}{crr|r}
1 & 1 & -2 & -5 \\
0 & -3 & 5 & 18 \\
0 & -3 & 5 & 18
\end{array}\! \right] \quad \begin{array}{l}
\text{(two row replacements)}
\end{array} \\
& \sim
\left[\!\begin{array}{crr|r}
1 & 1 & -2 & -5 \\
0 & -3 & 5 & 18 \\
0 & 0 & 0 & 0
\end{array}\! \right] \quad \begin{array}{l}
\text{(one row replacements)} \end{array} \\
& \sim
\left[\!\begin{array}{crr|r}
1 & 1 & -2 & -5 \\
0 & 1 & -5/3 & -6 \\
0 & 0 & 0 & 0
\end{array}\! \right] \quad \begin{array}{l}
\text{(one row scaling)} \\[-5pt]
\text{(and one row replacements to obtain} \\[-6pt]
\text{the matrix below)}
\end{array} \\
& \sim
\left[\!\begin{array}{crr|r}
1 & 0 & -1/3 & 1 \\
0 & 1 & -5/3 & -6 \\
0 & 0 & 0 & 0
\end{array}\! \right] \quad \begin{array}{l}
\text{This matrix is in Reduced Row Echelon Form.} \\[-5pt]
\text{I always like to row reduce a matrix} \\[-5pt]
\text{to its RREF - Reduced Row Echelon Form.} \\[-5pt]
\text{For the definition of RREF see the end of this post.}
\end{array}
\end{align*}
Why are the matrices presented above row equivalent?
- On the first line, the two matrices are row equivalent since the matrix on the right is obtained from the matrix on the left by performing two row operations. The first row operation was a row replacement: the second row $\left[\!\begin{array}{crr|r} 2 & -1 & 1 & 8 \end{array}\! \right]$ is replaced by the sum of itself and the multiple of the first row $ \left[\!\begin{array}{crr|r} 1 & 1 & -2 & -5 \end{array}\! \right]$ by $-2$: \begin{align*} \left[\!\begin{array}{crr|r} 2 & -1 & 1 & 8 \end{array}\! \right] + (-2) \left[\!\begin{array}{crr|r} 1 & 1 & -2 & -5 \end{array}\! \right] & = \left[\!\begin{array}{crr|r} 2 & -1 & 1 & 8 \end{array}\! \right] + \left[\!\begin{array}{crr|r} -2 & -2 & 4 & 10 \end{array}\! \right] \\ & = \left[\!\begin{array}{crr|r} 2 - 2 & -1 - 2 & 1 + 4 & 8 + 10 \end{array}\! \right] \\ & = \left[\!\begin{array}{crr|r} 0 & -3 & 5 & 18 \end{array}\! \right] \end{align*} The second row operation was again a row replacement: the third row $\left[\!\begin{array}{crr|r} 3 & 0 & -1 & 3 \end{array}\! \right]$ is replaced by the sum of itself and the multiple of the first row $ \left[\!\begin{array}{crr|r} 1 & 1 & -2 & -5 \end{array}\! \right]$ by $-3$: \begin{align*} \left[\!\begin{array}{crr|r} 3 & 0 & -1 & 3 \end{array}\! \right] + (-3) \left[\!\begin{array}{crr|r} 1 & 1 & -2 & -5 \end{array}\! \right] & = \left[\!\begin{array}{crr|r} 3 & 0 & -1 & 3 \end{array}\! \right] + \left[\!\begin{array}{crr|r} -3 & -3 & 6 & 15 \end{array}\! \right] \\ & = \left[\!\begin{array}{crr|r} 3 - 3 & 0 - 3 & -1 + 6 & 3 + 15 \end{array}\! \right] \\ & = \left[\!\begin{array}{crr|r} 0 & -3 & 5 & 18 \end{array}\! \right] \end{align*} Thinking about the corresponding system of linear equations, what we achieved at this step is that we eliminated unknown $x_1$ from the second and the third equation.
- The matrix on the second line is row equivalent to the matrix above it since it is obtained from the matrix above it by performing a row replacement: the third row $\left[\!\begin{array}{crr|r} 0 & -3 & 5 & 18 \end{array}\! \right]$ is replaced by the sum of itself and the second row $ \left[\!\begin{array}{crr|r} 0 & -3 & 5 & 18 \end{array}\! \right]$ multiplied by $-1$: \begin{align*} \left[\!\begin{array}{crr|r} 0 & -3 & 5 & 18 \end{array}\! \right] + (-1) \left[\!\begin{array}{crr|r} 0 & -3 & 5 & 18 \end{array}\! \right] & = \left[\!\begin{array}{crr|r} 0 & 0 & 0 & 0 \end{array}\! \right] \end{align*} Thinking about the corresponding system of linear equations, what we achieved at this step is that we reduced the number of equations from three to two.
- The matrix on the third line is row equivalent to the matrix above itself since it is obtained from the matrix above itself by performing a row scaling: the second row $\left[\!\begin{array}{crr|r} 0 & -3 & 5 & 18 \end{array}\! \right]$ is replaced by the multiple of itself $-1/3$: \[ (-1/3) \left[\!\begin{array}{crr|r} 0 & -3 & 5 & 18 \end{array}\! \right] = \left[\!\begin{array}{crr|r} 0 & 1 & -5/3 & -6 \end{array}\! \right] \] Thinking about the corresponding system of linear equations, what we achieved at this step is that we now have the coefficient $1$ with the unknown $x_2$ in the second equation.
- The matrix on the fourth line is row equivalent to the matrix above itself since it is obtained from the matrix above itself by performing a row replacement: the first row $\left[\!\begin{array}{crr|r} 1 & 1 & -2 & -5 \end{array}\! \right]$ is replaced by the sum of itself and the second row $ \left[\!\begin{array}{crr|r} 0 & 1 & -5/3 & -6 \end{array}\! \right]$ multiplied by $-1$: \begin{align*} \left[\!\begin{array}{crr|r} 1 & 1 & -2 & -5 \end{array}\! \right] + (-1) \left[\!\begin{array}{crr|r} 0 & 1 & -5/3 & -6 \end{array}\! \right] & = \left[\!\begin{array}{crr|r} 1 & 0 & -1/3 & 1 \end{array}\! \right] \end{align*} Thinking about the corresponding system of linear equations, what we achieved at this step is that we eliminated unknown $x_2$ from the first equation.
- Since the matrices \[ \left[\!\begin{array}{crr|r} 1 & 1 & -2 & -5 \\ 2 & -1 & 1 & 8 \\ 3 & 0 & -1 & 3 \end{array}\! \right] \sim \left[\!\begin{array}{crr|r} 1 & 0 & -1/3 & 1 \\ 0 & 1 & -5/3 & -6 \\ 0 & 0 & 0 & 0 \end{array}\! \right] \] are row equivalent, the corresponding systems are equivalent systems. That is, the solution set of the given system is the same as the solution set of the system \begin{alignat*}{8} &x_1 & & && & & - &&1/3 &&\, x_3 &&= &&1\\ & & & &&x_2 & & - &&5/3 &&\, x_3 &&= -&&6 \end{alignat*} In the preceding system there is no restriction on $x_3$; $x_3$ is so-called free variable. I like introducing a new name for the free variable, say $s$. Then the solution of the preceding system is given by \begin{equation*} x_1 = \frac{1}{3} s + 1, \quad x_2 = \frac{5}{3} s - 6, \quad x_3 = s, \end{equation*} where $s$ is an arbitrary real number. In set notation, $s \in \mathbb{R}.$ For example, with $s=3$ we obtain that \[ x_1 = 2, \quad x_2 = -1, \quad x_3 = 3, \] is a solution to the given system.
- It is always fun to verify whether the solution realy satisfies the given system. Substitute $x_1 = \frac{1}{3} s + 1,$ $x_2 = \frac{5}{3} s - 6$ and $x_3 = s,$ and see what we get: \begin{alignat*}{8} &(1/3 \, s + 1) & & + &&(5/3 \, s - 6) & & - &&2 &&s &&= 2s - 5 +2s = -&&5\\ 2 &(1/3 \, s + 1) & & - &&(5/3 \, s - 6) & & + && &&s &&= -s + 8 + s = &&8 \\ 3 &(1/3 \, s + 1) & & && & & - && && s &&= s + 3 - s = &&3 \end{alignat*} Hence we found all the solutions of the given system.
-
Finally, let us illustrate the system
\begin{alignat*}{8}
&x_1 & & + &&x_2 & & - &&2 &&x_3 &&= -&&5\\
2 &x_1 & & - &&x_2 & & + && &&x_3 &&= &&8 \\
3 &x_1 & & && & & - && && x_3 &&= &&3
\end{alignat*}
geometrically in $x_1x_2x_3$-space, that is in the space $\mathbb{R}^3.$ Each equation is represented by a plane. The first equation is represented by the brown plane, the second equation is represented by the blue plane and the third equation is represented by the green plane.
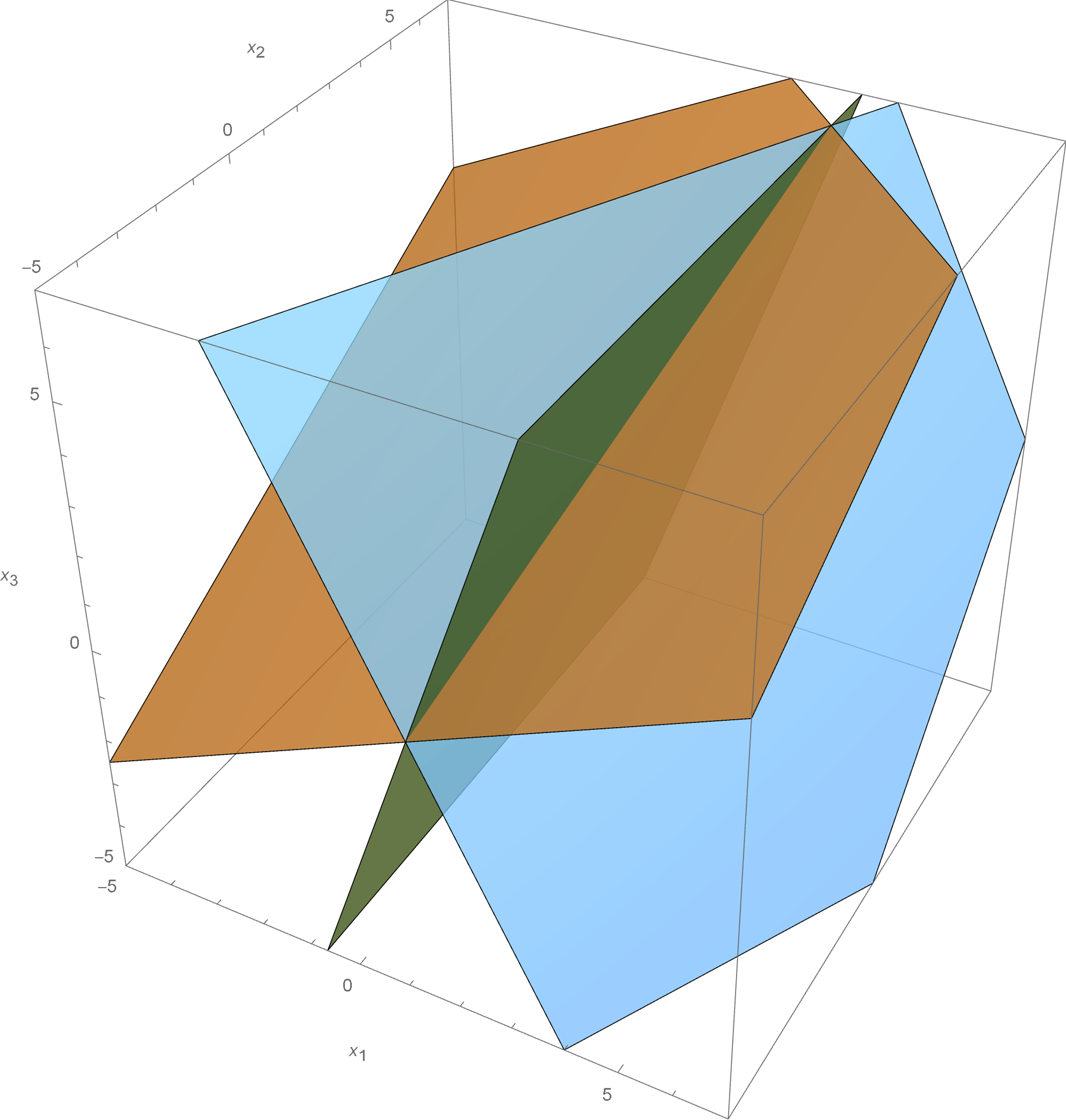
-
A natural question is: How are row operations reflected in the illustration of the system with planes?
The systems that correspond to the row equivalent matrices on lines 2 and 3 in the row reduction above are illustrated by the same picture; the planes do not change. The system corresponding to the last matrix in Reduced Row Echelon Form is represented by the simplest planes. What is the simplicity of these planes? The first plane is parallel to the coordinate axis $x_2.$ The second plane is parallel to the coordinate axis $x_1.$ (Being parallel to coordinate ases is a very desirable feature for a plane.)Given System Systems 2 and 3 "Row Reduced" System \begin{alignat*}{8} &x_1 & & + &&x_2 & & - &&2 &&x_3 &&= -&&5\\ 2 &x_1 & & - &&x_2 & & + && &&x_3 &&= &&8 \\ 3 &x_1 & & && & & - && && x_3 &&= &&3 \end{alignat*} \begin{alignat*}{8} &x_1 & & + &&x_2 & & - &&\phantom{5/} 2&&x_3 &&= -&&5\\ & & & &&x_2 & & - &&5/3 &&x_3 &&= -&&6 \\ & & & && & & && && && && \end{alignat*} \begin{alignat*}{8} &x_1 & & && & & - &&1/3 &&x_3 &&= &&1\\ & & & \phantom{+} &&x_2 & & - &&5/3 &&x_3 &&= -&&6 \\ & & & && & & && && && && \end{alignat*} 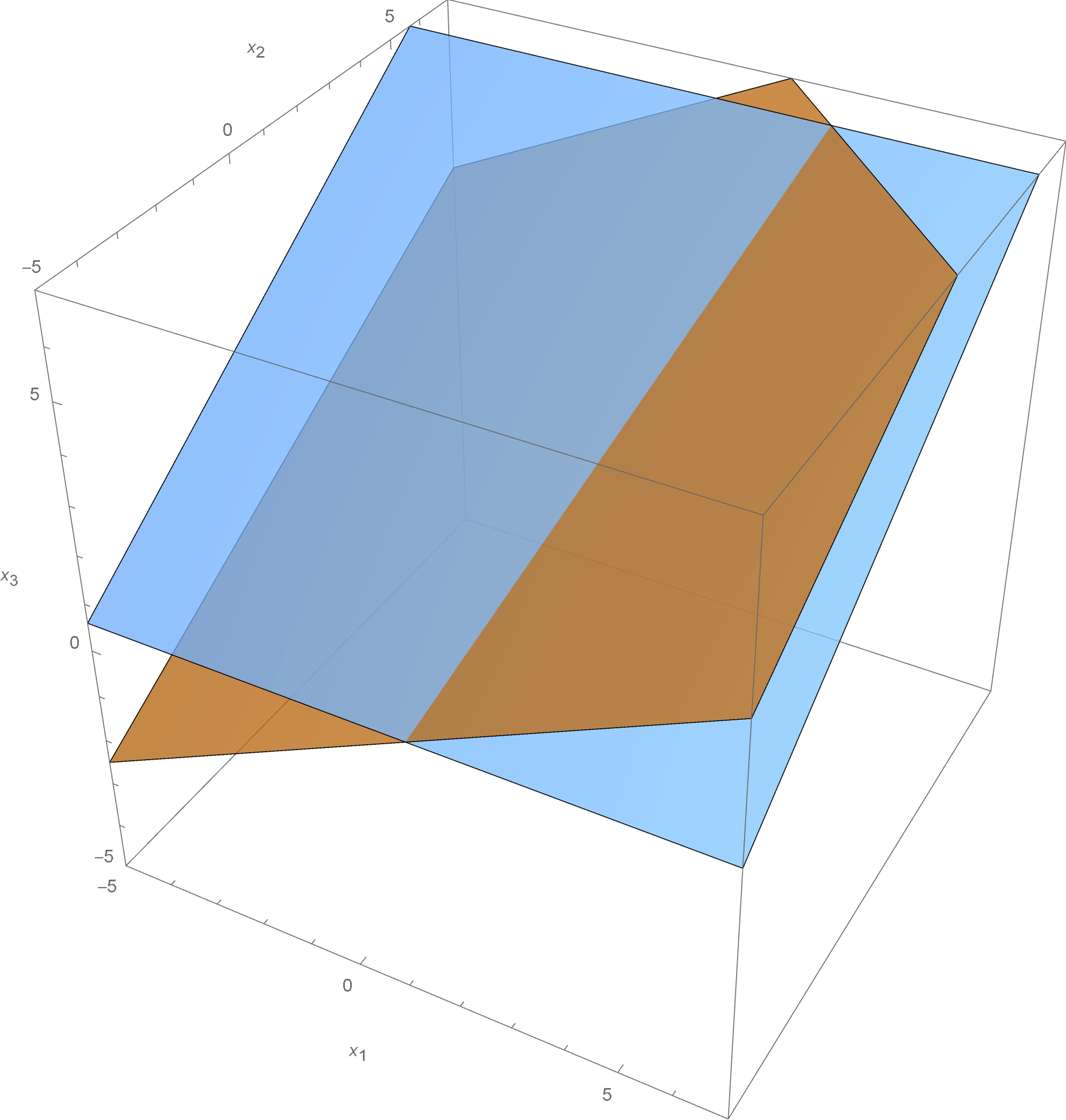
-
Let us change the system just by changing one number on the left hand side of the first equation:
\begin{alignat*}{8}
&x_1 & & + &&x_2 & & - &&2 &&x_3 &&= &&5\\
2 &x_1 & & - &&x_2 & & + && &&x_3 &&= &&8 \\
3 &x_1 & & && & & - && && x_3 &&= &&3
\end{alignat*}
The only difference is that in the first equation $-5$ is replaced by $5$. So, the same row operations that we used above will row reduce the corresponding augmented matrix:
\begin{align*}
\left[\!\begin{array}{crr|r}
1 & 1 & -2 & 5 \\
2 & -1 & 1 & 8 \\
3 & 0 & -1 & 3
\end{array}\! \right] & \sim
\left[\!\begin{array}{crr|r}
1 & 1 & -2 & 5 \\
0 & -3 & 5 & -2 \\
0 & -3 & 5 & -12
\end{array}\! \right] \\
& \sim
\left[\!\begin{array}{crr|r}
1 & 1 & -2 & 5 \\
0 & -3 & 5 & -2 \\
0 & 0 & 0 & -10
\end{array}\! \right] \\
& \sim
\left[\!\begin{array}{crr|r}
1 & 1 & -2 & 5 \\
0 & 1 & -5/3 & 1/3 \\
0 & 0 & 0 & 1
\end{array}\! \right] \\
& \sim
\left[\!\begin{array}{crr|r}
1 & 0 & -1/3 & 14/3 \\
0 & 1 & -5/3 & 1/3 \\
0 & 0 & 0 & 1
\end{array}\! \right] \\
& \sim
\left[\!\begin{array}{crr|r}
1 & 0 & -1/3 & 0 \\
0 & 1 & -5/3 & 0 \\
0 & 0 & 0 & 1
\end{array}\! \right]
\end{align*}
The preceding row reduction proves that the following two linear systems are equivalent:
The last equation in the system on the right is written with zeros for us to see that the resulting equation does not have a solution. Hence the above system on the right is inconsistent and thus, the given system is inconsistent.\begin{alignat*}{8} &x_1 & & + &&x_2 & & - &&2 &&x_3 &&= &&5\\ 2 &x_1 & & - &&x_2 & & + && &&x_3 &&= &&8 \\ 3 &x_1 & & && & & - && && x_3 &&= &&3 \end{alignat*} \begin{alignat*}{8} &x_1 & & && & & - 1/3 && &&x_3 &&= &&0\\ & & & &&x_2 & & - 5/3 && &&x_3 &&= &&0 \\ 0 &x_1 & & + 0 & & x_2 & & + \ 0 && && x_3 &&= &&1 \end{alignat*}
Below is the corresponding illustration in $\mathbb{R}^3.$
- The information sheet and the class calendar.
- We will start with Section 1.1 Systems of Linear Equations. Suggested problems are 3, 6, 7, 5, 9, 11, 12, 16, 17, 18, 21, 22, 23, 24, 25, 27, 31, 33, 34.
-
Just reading Section 1.1 you will experience that linear algebra is a subject full of new terminology:
- linear equation,
- coefficients of a linear equation,
- system of linear equations or linear system or just system,
- a solution of a linear system,
- the solution set of a linear system,
- consistent linear system,
- inconsistent linear system,
- equivalent systems,
- coefficient matrix of a system,
- augmented matrix of a system,
- elementary row operations,
- row-equivalent matrices.
- Learning the terminology of a field is crucial to getting to understand that field. This is true in general and particularly true in Linear Algebra. Therefore I started a webpage with Glossary of Linear Algebra Terms with my comments.
-
What is the oldest linear algebra problem?
-
Clay tablet VAT 8389 from the Old Babylonian period, from 2000 to 1600 BC, contains what is believed to be the earliest word problem that can be interpreted as a system of linear equations:
A translation of this word problem into a system of linear equations is as follows: \begin{alignat*}{4} &x_1 & &\ + &x_2 & = 1800 \\ \tfrac{2}{3} &x_1 & &- \tfrac{1}{2} &x_2 & = \phantom{1}500. \end{alignat*} -
Problem 40 of the Rhind papyrus which is dated to 1550 BC is:
Denote by $x_1$ the smallest number and by $x_2$ the common difference. After simplification, the above problem translates into the following system of linear equations: \begin{alignat*}{5} 5 &x_1 & & + 10 &x_2 & = 100 \\ \tfrac{11}{7} &x_1 & & - \phantom{1}\tfrac{2}{7} &x_2 & = \phantom{10}0. \end{alignat*} -
Most importantly for us, the oldest known treatment of systems of linear equations from antiquity which resembles the methods that we will use in this class is in Chapter 8 of the Chinese textbook Nine Chapters of the Mathematical Art which is at least 1800 years old.
-
Clay tablet VAT 8389 from the Old Babylonian period, from 2000 to 1600 BC, contains what is believed to be the earliest word problem that can be interpreted as a system of linear equations:
Different civilizations have created mathematical knowledge throughout history and sometimes passed that knowledge among themselves. A significant aspect of the growth of mathematical knowledge was that succeeding civilizations recognized the value of the knowledge created by preceding civilizations. Just the fact that I am writing this here is my recognition and appreciation of the contribution of the ancient civilizations to Linear Algebra.